
Un crawler Web ou robot (également appelé « robots d’exploration », « robots d’indexation », ou « araignées Web ») est un programme automatisé pour naviguer méthodiquement sur le net dans le seul but d’indexer les pages Web et leur contenu. Ces robots sont utilisés par les moteurs de recherche pour explorer les pages Web afin de renouveler leur index avec de nouvelles informations. Ainsi, lorsque les internautes feront une requête particulière, ils pourront trouver facilement et rapidement les informations les plus pertinentes.
Lorsque vous effectuez une requête sur un moteur de recherche, vous obtenez comme résultat, une liste bien classée de sites web.
Avant que n’apparaissent ces sites web dans les SERP, un travail connu sous le nom d’exploration et d’indexation est réalisé en coulisses par les moteurs de recherche.
L’acteur principal au cœur de cette machinerie est le robot d’indexation encore appelé crawler.
Dans ce cas :
- Qu’est-ce qu’un robot ou un crawler ?
- Comment fonctionnent-ils ?
- Quelle est son importance dans le SEO ?
- Qu’est-ce que l’indexation et quel rôle y joue concrètement les robots ?
- Quelle est la différence entre le web crawler et le web scraping ?
Voilà autant de questions dont les réponses nous permettront de comprendre clairement la définition de crawler et tout ce qui l’entoure.
C’est parti !
Chapitre 1 : Qu’entend-on véritablement par Crawler ou robot d’exploration ?
Unités fonctionnelles des moteurs de recherche, les crawlers ou robots sont au cœur même de la grande majorité des actions et interactions du web.
La compréhension de la recherche internet passe clairement par la connaissance exhaustive de ses concepts.
Ainsi donc, dans ce chapitre, je vous expose les robots ou crawlers dans leurs moindres détails.










1.1. Un Crawler : Qu’est-ce que c’est ?
Avant d’aborder le crawler dans son fonctionnement et ses applications, il est primordial de rappeler ses origines et de donner sa véritable signification.

Ceci dit, voici l’historique puis la signification réelle du crawler.
1.1.1. Les crawlers ou robots d’indexations depuis l’avènement du web
Les robots d’indexation sont aujourd’hui connus sous de nombreuses appellations :
- Crawler ;
- Bots d’exploration ;
- Spiders ;
- Araignée web ;
- Logiciels de moteurs de recherche ;
- Et bien d’autres noms.

Originellement, le tout premier robot d’indexation se nommait WWW Wanderer (l’abréviation de World Wild Web Wanderer).
Ce robot d’indexation conçu et basé sur Perl (langage de programmation stable et multiplateforme) était chargé dès juin 1993 d’évaluer l’expansion d’Internet dont l’avènement était encore de fraîche date.
À l’époque, le robot WWW Wanderer (« le vagabond ») parcourait Internet à la collecte de données qu’il enregistrait dans l’index du moment, le tout premier index Internet : l’index Wandex.
À ses débuts, Wanderer n’explorait que les serveurs web. Peu après son introduction complète, il s’est ensuite mis à suivre les URL.
Contrairement à ce qu’on pourrait penser, Wanderer avec son index Wandex n’était pas le premier moteur de recherche sur Internet. Il s’agit en réalité du moteur de recherche archie développé par Alan Emtage.
Toutefois, avec son index Wandex, Wanderer était résolument ce qui se rapprochait le plus d’un moteur de recherche généraliste du web comme les moteurs de recherche Google et Bing d’aujourd’hui.
À la suite du WWW Wanderer, en 1994 le premier navigateur web fit son apparition : le Webcrawler. Il s’agit aujourd’hui, du moteur de recherche (métamoteur) le plus ancien encore présent et fonctionnel sur Internet.
Dans l’évolution perpétuelle du web, de nombreuses améliorations se sont succédées et les moteurs de recherche ainsi que leurs robots d’indexation ont changé et se sont perfectionnés.
L’historique de la recherche Internet et des robots d’exploitation vient ainsi d’être balayé dans ces grandes lignes.
Cependant, quel est le véritable sens du mot crawler ?
1.1.2. Un Crawler : Quelle est sa vraie signification ?
Nommé à la suite du plus vieux moteur de recherche existant (Webcrawler), crawler est un mot anglais qui signifie littéralement « se faufiler », « ramper », « scanner »… Autant de correspondances opportunes qui expriment clairement l’essence même des robots d’indexations.
Au risque de se répéter, un robot d’indexation est un programme informatique, un logiciel qui parcourt Internet de manière contrôlée, repère et analyse les pages web dans un but précis.
À l’instar d’une araignée avec sa toile, le crawler explore et analyse le web. Cette analyse concerne les différentes pages web, leurs contenus et l’ensemble de leurs ramifications.
Le crawler ainsi à la recherche de données, va enregistrer et ranger dans des index et/ou des bases de données, les diverses informations recueillies.
On comprend donc pourquoi ces robots sont également appelés spiders ou araignées web.

Ces robots d’indexation sont, dans 99 % des cas, toujours utilisés par les moteurs de recherche. Ils permettent à ces derniers de se construire des index structurés et d’optimiser leurs performances en tant que moteurs de recherche (présentation de nouveaux résultats pertinents, par exemple).
En ce qui concerne le 1 % des cas restants, les crawlers servent plutôt à la recherche et à la collecte d’informations à type de contacts et de profils (adresses mail, flux RSS et autres) dans un but marketing.
Pour faire simple, reprenons le célèbre exemple du bibliothécaire. Dans cet exemple, le bot du moteur de recherche est un bibliothécaire chargé d’inventorier l’ensemble des bouquins et documents (sites et pages web) d’une immense bibliothèque complètement désorganisée (le web).
Le bot se doit de créer une table récapitulative (index du moteur de recherche) qui permettra aux lecteurs (internautes) d’accéder rapidement et aisément aux livres (informations) qu’ils recherchent.
Afin d’ordonner et de classer (indexer) les livres (sites web) par centres d’intérêt puis de faire l’inventaire, le bibliothécaire (crawler) devra pour chaque livre, s’enquérir de son titre, son résumé et du sujet qui y est traité.
Mais à l’opposé d’une bibliothèque, sur Internet, les sites web sont reliés les uns aux autres par des hyperliens, lesquels sont utilisés par les bots pour passer d’un site ou d’une page web à l’autre.
Sommairement, voilà ce que représente le crawler et ce dont il est chargé. Reste plus qu’à savoir comment il fonctionne.
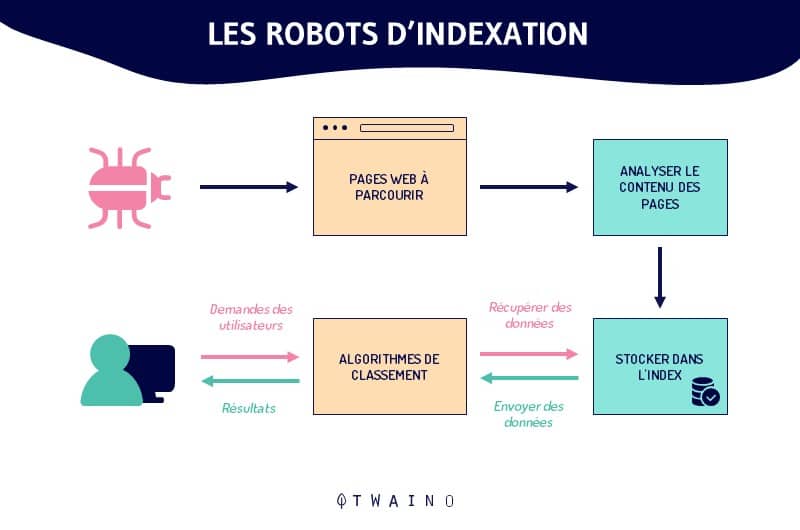
1.2. Comment fonctionne un robot d’indexation ou Crawler ?










Le crawler est avant tout un programme, des scripts et des algorithmes dont l’ensemble des tâches ainsi que les commandes sont définis d’avance.
Tel un bon petit soldat, il se contente de suivre assidûment les instructions et les fonctions prédéfinies dans son code de manière automatique, continue et répétitive.
En surfant sur la toile au travers des liens hypertextes (des sites web existant vers les nouveaux sites), les spiders indexent aussi bien les contenus que les URL. Ils analysent les mots-clés et les hashtags et s’assurent du caractère récent du code HTML ainsi que des liens des sites indexés.
Comme le stipule le célèbre proverbe africain : « C’est au bout de l‘ancienne corde que l’on tisse la nouvelle. »
Le web étant en perpétuelle croissance, il est impossible d’évaluer précisément le nombre total de pages existant sur Internet.
Dans l’accomplissement de leurs tâches, les crawlers débutent l’exploration à partir d’une liste d’URL connues.
Ainsi, l’exploration se fait suivant un schéma très simple :
Anciennes URL connues => pages web indexées => hyperliens => nouvelles URL à explorer => pages web à indexer => ainsi de suite…
Loin de fonctionner hasardeusement, les robots d’indexations obéissent à certaines conduites qui leur confèrent une sélectivité minutieuse dans le choix des pages à indexer ainsi que dans l’ordre et la fréquence de l’indexation de ces pages.
Ainsi, un robot d’indexation détermine la page à indexer en premier selon :
- Le nombre de backlinks menant à la page (le nombre de pages externes auxquelles cette page est liée) ;
- Le maillage interne (les liens entre les différentes pages d’un même site web) ;
- Le trafic de la page (la masse de visiteurs accueillis sur la page en question) ;
- Les éléments attestant de la qualité, de la pertinence et de la fraîcheur des informations contenues sur la page (le Sitemap, les meta-tags, les URL canoniques, etc.) ;
- Le protocole robots.txt (le fichier contenant des groupes de directives à l’intention des bots) ;
- Etc.
Selon le moteur de recherche, ces facteurs sont considérés différemment. On comprend alors parfaitement que tous les bots de moteurs de recherche ne se comportent pas de la même façon.
1.3. Quels sont les différents types de Crawlers existant ?
Partageant les mêmes principes généraux de fonctionnement, les crawlers se distinguent principalement de par leur focalisation et leur portée.
Eh oui, outre les robots d’indexations des moteurs de recherche, on retrouve bien d’autres catégories de crawlers.










1.3.1. Les bots des moteurs de recherche
Ces crawlers sont sans l’ombre d’un doute, les tous premiers crawlers ayant jamais existés.
Ils sont connus sous le nom de searchbots. Un nom justifié par le fait qu’ils sont conçus dans l’intention de servir les moteurs de recherche dans l’optimisation de leur champ d’action et surtout de leur base de données.
Parmi les plus célèbres, on retient les searchbots suivant :
- Le Googlebot de Google : searchbot le plus utilisé sur le net et dont l’index est le plus riche ;
- Le Bingbot de Bing, le moteur de recherche de Microsoft ;
- Le Slurpbot de Yahoo ;
- Le Baidu Spider du search engine chinois Baidu ;
- Le Yandex Bot de Yandex, le moteur de recherche russe ;
- Le DuckDuckBot de DuckDuckGo ;
- Le Facebot de Facebook ;
- L’Alexa Crawler d’Amazon ;
- Et plus encore.
1.3.2. Les Crawlers de bureau
Ce sont des minis crawlers aux fonctionnalités des plus limitées. Leur faible domaine de compétence est compensé par leur coût relativement insignifiant.
Ce sont des bots directement exécutables depuis un ordinateur portable personnel ou un PC et ils permettent uniquement de traiter une très petite quantité de données.
1.3.3. Les robots des sites web personnels
Une catégorie de crawlers conçue pour les entreprises et qui servent par exemple de manière spécifique à renseigner sur la fréquence d’utilisation de certains hashtags/mots-clés.
On peut mentionner à titre d’exemple :
- Le VoilaBot de l’entreprise de télécommunication Orange ;
- L’OmniExplorer_Bot de la société OmniExplorer ;
- Et bien d’autres.
1.3.4. Les Crawlers commerciaux
Il s’agit ici de solutions algorithmiques proposées moyennant un abonnement aux entreprises ayant personnellement besoin de crawler. Les crawlers font alors office d’outils payants permettant aux sociétés d’économiser d’énormes ressources temporelles et financières nécessaires à la conception de leur propre robot.
On peut citer à titre d’exemple de logiciel de crawl payant, les logiciels suivant :
- Botify ;
- SEMRush ;
- Oncrawl ;
- Deep Crawl ;
- Etc.
1.3.5. Les bots de site web dans les nuages
La particularité de ces crawlers de site web réside dans le fait qu’ils soient en mesure d’enregistrer sur le cloud les données collectées.
Un sacré avantage sur les autres crawlers qui se contentent de stocker les informations sur des serveurs locaux payants d’entreprises informatiques.
En plus de cela, l’accessibilité aux données et aux outils d’analyse est bien plus améliorée. Plus de soucis de localisation et de compatibilité logistique.
1.4. Que faut-il retenir de l’indexation (Google) dans la recherche Internet ?
La portion du web accessible au public et véritablement prospectée par les robots reste indéterminée.
Il est approximativement estimé que seuls 40 à 70 % du net est répertorié pour la recherche, soit plusieurs milliards d’URL.
Si nous reprenons l’exemple du bibliothécaire plus haut, l’action de prospection, de classification et de catalogage des livres (sites et pages web) de la bibliothèque représentait l’indexation de la recherche Internet.

L’indexation est donc un terme pratique qui désigne l’ensemble des processus à la suite desquels le crawler parcourt, analyse, organise et range les pages des sites web avant de les proposer dans les SERP.
Il s’agit d’un versant déterminant du référencement naturel, car il consiste en l’insertion et en la considération des pages web dans l’index des moteurs de recherche.
Bien que déterminante, cette première étape du référencement organique est loin d’être suffisante à l’apparition et au positionnement des pages web dans les SERP.
Grâce aux mises à jour continues de l’index Google, et surtout avec la mise en place de Caffeine, l’indexation Google a connu plus d’évolution.
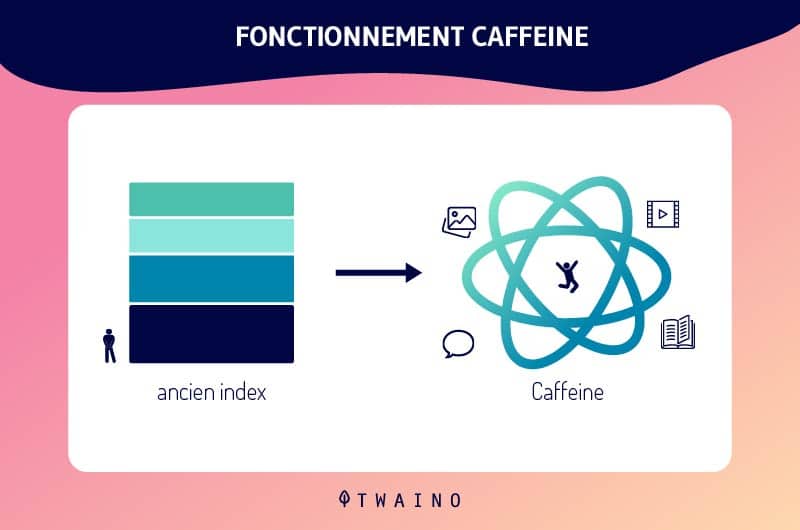
Par conséquent, les nouveaux contenus et/ou nouvelles pages web sont promptement indexés et leur parution dans les SERP se fait directement.
Tout cela mis à part, il est crucial de rappeler que les pages et le contenu de votre site web ne seront pas indexés par le Googlebot tant qu’il ne les aura pas trouvés. Cette étape primordiale de l’indexation Google est contrôlable.
En effet, il existe plusieurs solutions pour rendre visibles vos ressources par Google. Le moteur de recherche lui-même propose des alternatives intéressantes et efficaces sur le sujet.
Chapitre 2 : Un Crawler en application : Qu’est-ce que ça donne ?
Les présentations sont faites, passons maintenant à l’essentiel de la question.
Quels sont les apports, les avantages et l’importance SEO des crawlers ?
2.1. En pratique, comment s’y prennent les Crawlers ?
Nous l’avons vu, le comportement des crawlers est prédéfinie et intégré dans leurs lignes de code. Les facteurs régissant l’indexation des pages web sont ainsi pondérés en conséquence selon les bots et selon le bon vouloir des moteurs de recherche.
En pratique, l’action des robots d’indexation se décide en plusieurs étapes.
Dans un premier temps, les moteurs de recherche se doivent de déterminer la cible et/ou les préférences de ces robots. Les politiques d’exploration des sites web notamment les types d’URL à indexées, seront donc précisées dans la portion de données servant de garde-fou appelé crawler frontier.
Dans un second temps, les destinataires des crawlers attribuent à leurs robots une liste « seed » (graine) qui servira de point de départ à l’indexation. Il s’agit d’une série d’anciennes URL connues ou de nouvelles URL à explorer.
Ensuite, les moteurs de recherche complètent au programme des bots, la fréquence d’exploration et de traitement à accorder à chacune des URL.
Pour finir, les crawlers sont éduqués à respecter les directives du fichier robots.txt et/ou les balises HTML nofollow, contrairement aux spambots.
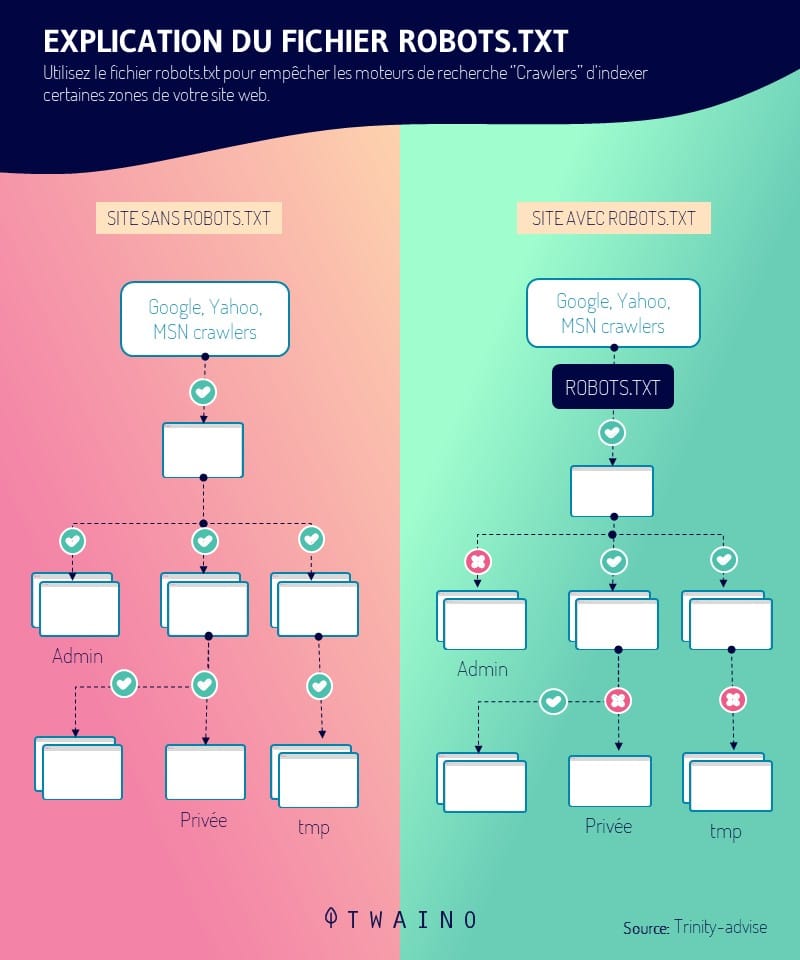
Ainsi, le robot d’indexation en accord avec les directives du protocole robots.txt, recevra l’instruction d’éviter tout ou partie d’un site web.
2.2. Un robot d’indexation : Qu’est-ce que ça apporte ?
Le crawler dans ses applications offre des avantages divers et variés dans bien de domaines.
Le premier avantage que l’on trouve au crawler réside dans sa simplicité d’utilisation et dans sa capacité à assurer une collecte ainsi qu’un traitement continu et complet des données.
Son efficacité à nul autre pareil dans l’accomplissement de ses fonctions d’exploration et d’indexation du contenu du web est également un précieux avantage.
Et pour cause, en réalisant la prospection, l’analyse ainsi que l’indexation du web en lieu et place de l’homme, les robots permettent un incroyable gain de temps et d’argent.
Dans une optique d’optimisation SEO (Search Engine Optimisation), le crawler permet d’augmenter le trafic organique d’un site web et de se démarquer de la concurrence.
Pour ce faire, il renseigne sur les termes de recherche et les mots-clés les plus tendances.

Outre ces principaux avantages, les crawlers servent remarquablement dans bien d’autres disciplines, tels que :
- L’optimisation du e-marketing par l’analyse de la clientèle de l’entreprise ;
- Le datamining et la publicité ciblée grâce à la collecte des adresses e-mail et/ou postales publiques des entreprises ;
- L’évaluation ainsi que l’analyse des données clients et des données d’entreprise dans le but d’amélioration des stratégies marketing de l’entreprise ;
- La création de banques de données ;
- La recherche des failles par la surveillance continue des systèmes ;
- Et bien d’autres.
Chapitre 3 : Quelle est l’importance et le rôle des Crawlers dans le SEO ?










Le rôle et l’importance des crawlers dans l’indexation n’est plus à démontrer. Cependant, leurs partitions et leurs intérêts dans la stratégie SEO demeurent jusqu’ici un peu flous.
3.1. La place des robots d’indexation en SEO
L’importance des crawlers pour le référencement naturel est intimement liée à leur capacité à établir les conditions nécessaires à l’apparition d’un site web dans les SERP.
L’objectif du SEO est d’obtenir un trafic organique considérable généré par des résultats naturels.
En d’autres mots : Faire partir des premiers résultats des moteurs de recherche.

L’exploration et l’indexation des pages Web par les crawlers est la base pour figurer parmi les résultats des moteurs de recherche. En vrai, ce n’est pas suffisant pour paraître dans les SERP, mais ça reste une étape indispensable.
3.2. Comment le robot d’exploration Web aide-t-il les experts en référencement ?
L’optimisation des moteurs de recherche consiste à améliorer le positionnement d’un site Web dans les SERPs. Cela se fait en optimisant les facteurs techniques et non techniques de la page pour ces moteurs de recherche.
Les implications SEO du crawler web sont énormes puisque c’est à eux d’indexer votre site avant que les algorithmes ne déterminent s’il mérite une place sur la première page.
Voici deux (02) astuces pour les amener à indexer efficacement vos pages importantes :
3.2.1. Le maillage interne
En plaçant de nouveaux backlinks et des liens internes supplémentaires, le professionnel du référencement s’assure que les crawlers découvrent les pages Web à partir des liens extraits pour s’assurer que toutes les pages du site web se retrouvent dans les SERP.
3.2.2. Soumission du plan du site
Créer un sitemaps (plans de site) et les soumettre aux moteurs de recherche favorise le référencement, car ces sitemaps contiennent des listes de pages à explorer.
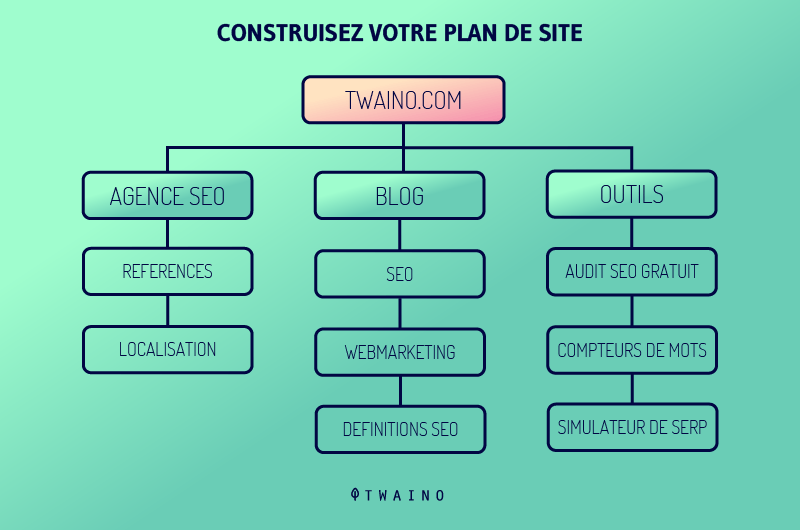
Les crawlers pourront facilement découvrir le contenu caché profondément dans le site Web et l’explorer en peu de temps, produisant ainsi une présence des pages importantes du site web dans les résultats de recherche.










3.3. Les bonnes pratiques pour améliorer son SEO avec les crawlers
L’optimisation de sa stratégie SEO passe principalement par l’optimisation de son crawl budget (le budget de crawl ou d’exploration). Il s’agit de la période de temps ainsi que la quantité de pages web que peuvent explorer et analyser les crawlers pour un site web.
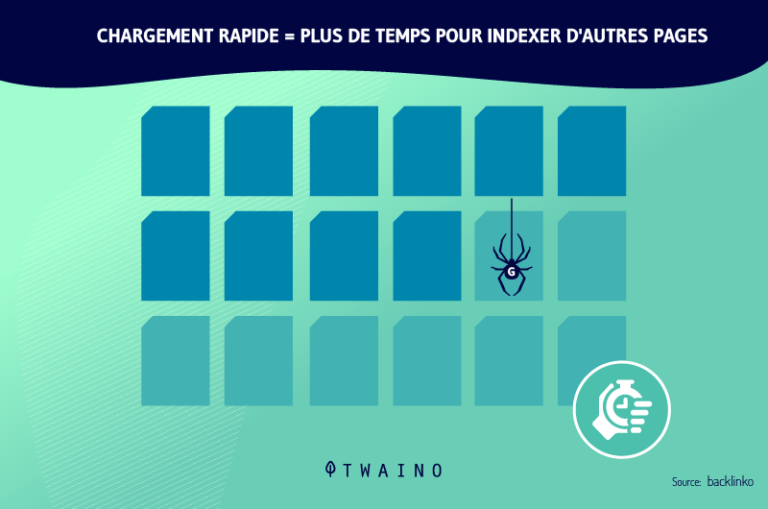
L’optimisation de ce budget passe par l’amélioration de la navigation, de l’architecture et des aspects techniques du site web. Il est alors conseillé d’adopter entre autres, les bonnes pratiques suivantes :
- Soumettez un Sitemap XML via GSC (Google Search Console). Il s’agit d’une directive non-standard du fichier robots.txt, qui guide les crawlers en leur indiquant les pages dont l’exploration et l’indexation sont prioritaires.
- Faites un audit complet du site web. L’objectif est d’améliorer les facteurs comme les mots-clés, la vitesse de chargement des pages du site web, etc.
- Construisez une stratégie de netlinking optimale avec des backlinks et un solide maillage interne. Cela consiste d’une part, en l’obtention de liens provenant d’autres sites web déjà indexés et dont la fréquence d’exploration par les crawlers est élevée. Et d’autre part, il s’agit de relier intelligemment les différentes pages du site web entre elles afin de permettre au crawlers de facilement circuler d’une page à l’autre.
- Inspectez les URL, les contenus et le code HTML dans le but de supprimer ou d’actualiser les éléments obsolètes, superflus, douteux ou ceux dont la pertinence fait défaut.
- Optez pour des méta-tags explicites et pertinents, un contenu de qualité, des URL canoniques…
- Évitez le duplicate content, le cloaking ainsi que l’ensemble des pratiques SEO BlackHat.
- Assurez l’accessibilité au serveur hébergeant le site web aux crawlers des moteurs de recherche.
- Identifiez et corrigez les divers éléments bloquant l’indexation des pages web.
- Être attentif aux mises à jour et changement d’algorithmes des moteurs de recherche afin de toujours connaître les critères SEO en vigueur.
3.4. Autres cas d’utilisation des crawlers au-delà des moteurs de recherche
Google a commencé à utiliser le robot d’exploration Web pour rechercher et indexer le contenu afin de découvrir facilement des sites Web par mots-clés et expressions.
Les moteurs de recherche et les systèmes informatiques ont créé leurs propres robots d’exploration Web programmés avec différents algorithmes. Ceux-ci explorent le Web, analysent le contenu et créent une copie des pages visitées pour une indexation ultérieure.
Le résultat est visible, car aujourd’hui, vous pouvez trouver facilement toutes les bonnes informations ou données qui existent sur le Web.
Nous pouvons utiliser des crawlers pour collecter des types spécifiques d’informations à partir de pages Web, telles que :
- Avis indexés à partir d’une application d’agrégation d’aliments ;
- Informations pour la recherche académique ;
- Etude de marché pour trouver les tendances les plus populaires ;
- Meilleurs services ou emplacements pour un usage personnel ;
- Emplois ou opportunités en entreprise ;
- Etc.
Autres cas d’utilisations des crawlers incluent :
- Suivi des modifications du contenu ;
- Détection des sites Web malveillants ;
- Récupération automatique des prix à partir des sites Web des concurrents pour la stratégie de tarification ;
- Identification des best-sellers potentiels pour une plateforme de commerce électronique en accédant aux données de la concurrence ;
- Classement de la popularité des leaders ou des stars de cinéma ;
- Accès aux flux de données de milliers de marques similaires ;
- Indexation des liens les plus fréquemment partagés sur les réseaux sociaux ;
- Accès aux offres d’emploi et leur indexation en fonction des avis et des salaires des employés ;
- Analyse comparative des prix et catalogage par code postal pour les détaillants ;
- Accès aux données de marché et sociales pour construire un moteur de recommandation financière ;
- Découvrir les salons de discussion liés au terrorisme ;
- Etc.
Si vous connaissez le Web scraping, il est possible que vous le confondez avec le Web crawler. Voyons à présent la différence :
3.5. Web crawler vs Web scraper : Comparaison
Comme le crawler, le scraper est un robot chargé de la collecte et du traitement des données sur le web. Mais ne vous y trompez pas, les crawlers et les scrapers ne sont pas des robots du même genre.
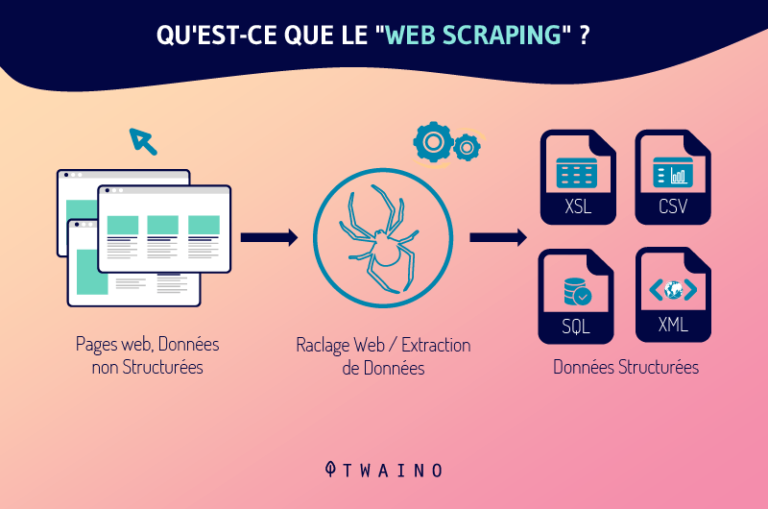
Le web scraper est au web crawler ce que le yin est au yang, le noir au blanc, le mal au bien…
L’un est au service du licite et de la droiture, tandis que l’autre sert parfois du côté obscur.
En réalité, le scraper est un bot programmé pour repérer et dupliquer intégralement, généralement sans autorisation, des données spécifiques appartenant au contenu d’un site web.
Après l’extraction de ces données, le scraper les ajoute tel quel ou à peine modifié dans des bases de données pour être ultérieurement utilisé.
Bien qu’étant assimilables, les deux bots se distinguent clairement de par plusieurs caractères notamment :
- Leur principale fonction :
Celle des crawlers consiste exclusivement en l’exploration, l’analyse et l’indexation des contenus du web au travers de la consultation continue d’anciennes ainsi que de nouvelles URL. À l’opposé, les scrapers n’existent que pour copier les données des sites web en suivant ponctuellement des URL précises.
- Leur impact sur les serveurs web :
Contrairement aux robots d’indexation des moteurs de recherche qui s’appliquent à respecter les directives des fichiers robots.txt et se contentent des métadonnées, les scrapers n’obéissent à aucune règle.
Voyons une étude de cas rapide de ce concept de Web scraping :
Etude de cas
- Premièrement, en nous référant aux Conditions d’utilisation du 7 juin 2017, Linkedin affirme ce qui suit par l’article 8.2.k :
« Vous vous engagez à ne pas : […] développer, prendre en charge ou utiliser des logiciels, des dispositifs, des scripts, des robots ou tout autre moyen ou processus (notamment des robots d’indexation, des modules d’extension de navigateur et compléments, ou toute autre technologie ou tout travail physique) visant à effectuer du web scraping des Services ou à copier par ailleurs des profils et d’autres données des Services ».
Malgré cela, lors d’une lutte juridique entre Linkedin et un start-up américain appelé HiQ Labs (au sujet de recours aux pratiques de web scraping pour la collecte exclusive des informations appartenant aux profils publics LinkedIn des salariés d’une entreprise), la cour tranché sur ce qui suit :
Les données qui sont présentes sur les profils des utilisateurs sont publiques une fois qu’elles sont publiées sur le net et peuvent dans ce cas être librement collectées via le web scraping.
- Deuxièmement, en nous référant à usine-digitale, le web scraping serait considéré selon l’article 323-3 du Code pénal en France comme un ‘’Vol de données’’. Ce article énonce :
« Le fait d’introduire frauduleusement des données dans un système de traitement automatisé, d’extraire, de détenir, de reproduire, de transmettre, de supprimer ou de modifier frauduleusement les données qu’il contient est puni de cinq ans d’emprisonnement et de 150.000 € d’amende. Lorsque cette infraction a été commise à l’encontre d’un système de traitement automatisé de données à caractère personnel mis en œuvre par l’Etat, la peine est portée à sept ans d’emprisonnement et à 300.000 € d’amende. »
A présent, à vous de tirer votre conclusion de ce concept de Web scraping.
Chapitre 4 : Autres questions posées sur les robots d’explorations
4.1. Qu’est-ce qu’un crawler ?
Un Crawler Web (appelé en français robot d’indexation, robot d’exploration ou araignée du Web) est un logiciel conçu par les moteurs de recherche pour explorer et indexer automatiquement le Web.
4.2. C’est quoi l’exploration de Google ?
L’exploration est le processus par lequel Googlebot (également appelé robot ou araignée) visite les pages afin de les ajouter à l’index Google. Le moteur de recherche utilise ainsi un vaste ensemble d’ordinateurs pour récupérer (ou « explorer ») des milliards de pages sur le Web.
4.3. Quand est-ce qu’on parle d’exploration ?
L’exploration se produit lorsque Google ou un autre moteur de recherche envoie un robot (ou araignées) vers une page Web ou une publication Web pour parcourir la page web.
Ensuite, ces robots d’exploration extraient les liens des pages qu’ils visitent pour découvrir des pages supplémentaires sur le site Web.
4.4. Comment fonctionne le crawler Google ?
Les robots d’exploration Web démarrent leur processus d’exploration en téléchargeant le fichier robot.txt du site Web. Le fichier comprend des plans de site qui répertorient les URL que le moteur de recherche peut explorer. Une fois que les robots d’exploration commencent à explorer une page, ils découvrent de nouvelles pages via des liens.
Ainsi, ils ajoutent les URL nouvellement découvertes à la file d’attente d’analyse afin qu’elles puissent être explorées ultérieurement. Grâce à cette technique, ces robots d’indexation peuvent indexer chaque page connectée à d’autres.
Étant donné que les pages changent régulièrement, les crawlers des moteurs de recherche utilisent plusieurs algorithmes pour décider de facteurs tels que la fréquence à laquelle une page existante doit être réexplorée et le nombre de pages d’un site à indexer.
4.5. Qu’est-ce que l’anti crawler ?
L’anti-robot est une technique de protection contre les robots d’exploration ou d’indexation de votre site Web. Si votre site Web contient des images de grande valeur, des informations sur les prix et d’autres informations importantes que vous ne voulez pas voir explorer, vous pouvez utiliser les balises meta robots.
4.6. Comment Google fonctionne pour fournir des résultats pertinents aux requêtes des utilisateurs ?
Google explore le Web, catégorise les millions de pages existantes et les ajoute à son index. Ainsi, lorsqu’un internaute lance une requête, au lieu de parcourir l’ensemble du Web, Google pourra simplement parcourir son index plus organisé pour obtenir rapidement des résultats pertinents.
4.7. Que sont les applications d’exploration du Web ?
L’exploration Web est couramment utilisée pour indexer les pages des moteurs de recherche. Cela permet à ces derniers de fournir des résultats pertinents pour les requêtes des utilisateurs.
L’exploration Web est également utilisée pour décrire le scraping Web, l’extraction de données structurées à partir de pages Web et autres.
4.8. Quels sont les exemples de Crawler ?
Chaque moteur de recherche utilise son propre robot d’exploration Web pour collecter des données sur Internet et indexer les résultats de la recherche.
Par exemple :
- Amazonbot est un robot d’exploration Web d’Amazon pour l’identification de contenu Web et la découverte de backlink ;
- Baiduspider pour Baidu ;
- Moteur de recherche Bingbot pour Bing par Microsoft ;
- DuckDuckBot pour DuckDuckGo ;
- Exabot pour le moteur de recherche français Exalead ;
- Googlebot pour Google ;
- Yahoo! Slurp pour Yahoo ;
- Yandex Bot pour Yandex ;
- Etc.
4.9. Quelle est la différence entre l’exploration et le scraping Web ?
Généralement, l’exploration Web est pratiquée par les moteurs de recherche par le biais des robots qui consistent à parcourir et créer une copie de la page dans l’index.
Contrairement au crawl, le scraping Web est utilisé par un humain, toujours par le biais d’un bot qui a pour but d’extraire des données particulières, généralement sur un site Web, pour d’éventuelles analyses ou pour créer quelque chose de nouveau.
En résumé
Les crawlers et l’indexation sont maintenant des notions dont vous maîtriser le sens et les implications. Retenez que ces concepts sont le quotidien et l’essence même des moteurs de recherche.
Le crawler dans sa fonction de prospection et d’archivage de la toile, conditionne la présence et la position des sites web dans les résultats des moteurs de recherche.
Toutefois les robots d’indexations, spiders ou quel que soit le nom que vous utilisez pour les désigner, servent également dans de nombreux autres domaines et disciplines.
Du fonctionnement des différents protagonistes de la recherche internet aux bonnes pratiques permettant son optimisation, vous avez maintenant une idée assez précise sur l’ensemble du sujet.
Appliquez intelligemment ces connaissances que vous venez d’acquérir.
Partagez avec nous en commentaire, votre expérience ainsi que vos découvertes sur le sujet.
À bientôt !


