
La balise Noindex est un code qui est ajouté aux pages web, afin d’indiquer aux moteurs de recherche que celles-ci ne doivent pas être indexées, même si elles sont explorées. De cette façon, toutes les pages sur lesquelles est placée la directive « noindex » ne pourront pas être intégrées à l’index du moteur de recherche, et ne pourront donc pas s’afficher dans les SERPs.
Le monde du numérique est guidé par la performance. En effet, tous les sites désirent faire indexer leurs pages pour avoir plus de trafic, un bon retour sur investissement et une bonne visibilité.
Au même moment, d’autres détenteurs souhaitent interdire aux moteurs de recherche de classer certaines pages pour diverses raisons, mais ne savent pas forcément comment le faire. Et si vous lisez cet article, c’est que vous êtes probablement dans le cas, c’est là qu’intervient la balise noindex.
Cette directive qui permet aux détenteurs de sites web ou développeur d’interdire aux moteurs de recherche de ne pas afficher certaines pages de leur site web dans les résultats de recherche est de plus en plus employée de nos jours.
Mais pour l’appliquer, il est d’abord important de connaître les savoir-faire nécessaires, ainsi que les critères à suivre.
Alors,
- Qu’est-ce que Noindex ?
- Comment l’appliquer sur une page ou un site web ?
- Quelles sont les pages sur lesquelles noindex peut être appliqué ?
Ce sont des problématiques auxquelles nous trouverons des solutions dans le reste de cet article. Suivons ensemble!
Chapitre 1 : Noindex : De quoi s’agit-il ?
Dans ce chapitre, je vous présenterai ce que signifie une balise noindex, et nous verrons après la série d’éléments qui suit :
- Comment appliquer la balise noindex sur une page ?
- Quelles sont les pages sur lesquelles ajouter cette balise ?
- Comment utiliser noindex et nofollow ?
1.1. Qu’est-ce que Noindex ?
Noindex est une balise qui permet d’indiquer aux moteurs de recherche tels que Google, Bing ou Yahoo qu’ils ne doivent pas inclure une page donnée dans les résultats de recherche. Cette balise est souvent utilisée dans la section head du HTML ou sur les en-têtes de réponse.
Si les moteurs de recherche trouvent la balise noindex dans le code HTML d’une page web, celle-ci ne sera pas incluse dans l’indexation et ne pourra pas être affichée aux internautes dans les SERPs après une requête.

Comme vous pouvez déjà le remarquer, l’inverse de noindex est « index » qui stipule clairement l’indexation. Grâce à noindex, vous avez le pouvoir de contrôler l’indexation des différentes pages de votre site web sans fournir un grand effort.
Par conséquent, elle représente un instrument essentiel pour le SEO. Google obéit toujours à une directive noindex, alors qu’il considère l’index comme une simple recommandation que vous lui avez faite pour vos pages.

À suivre également : comment vérifier si votre site est indexé dans Google.
1.2. Comment insérer Noindex ?
Pour exclure une page web de l’indexation des moteurs de recherche, il suffit d’insérer Noindex dans la métadonnée de la page concernée. En effet, c’est dans cette balise méta que sont indiquées les instructions que Google ou les autres moteurs de recherche doivent suivre pour un site web.
Cependant, pour empêcher les moteurs de recherche d’insérer une page dans leur l’index vous devez ajouter la balise qui suit dans l’en-tête du code HTML :
<meta name= » robots » content= » noindex »>
Plutôt que de boycotter tous les robots d’exploration (crawler), vous pouvez décider d’appliquer cette balise méta à un moteur de recherche en particulier.
Si vous désirez par exemple, interdire l’indexation d’une certaine page à Googlebot uniquement, vous pouvez remplacer la valeur de l’attribut « name » par « Googlebot », ça donne ceci :
<meta googlebot= » robots » content= » noindex »>
Pour ce qui est de Yahoo, le nom de son robot d’exploration est « slurp ». Toutefois, dans les procédures pour un bon référencement, il n’est pas important de baliser les robots individuellement.
Il faut insérer la directive noindex à partir d’un champ dans l’en-tête de réponse HTTP. Pour le faire, il vous faut ajouter le code ci-dessous à votre en-tête de réponse HTTP :
X- Robots-Tag : noindex
1.3. Quelles sont les pages sur lesquelles est appliquée la directive noindex ?
Voici les pages sur lesquelles vous pouvez appliquer la directive noindex, donc les pages qui n’auront potentiellement pas besoin d’être indexées dans Google.
1.3.1. Les archives des auteurs sur des blogs avec un seul auteur
Lorsque vous êtes seul à rédiger sur votre blog, vous disposez probablement des pages qui auront un degré de ressemblance de 90 % à celui du page principal de votre blog. Ces pages ne sont pas utiles pour Google et peuvent parfois être retenues comme du contenu dupliqué.

La solution pour éviter ces types de contenu est de désactiver intégralement l’archive des auteurs.
Vous avez également le choix de l’activer ou de le désactiver avec l’outil Yoast SEO. Cependant, si pour n’importe quelle raison vous aimeriez garder cette archive sur votre site, mais sans qu’il apparaisse dans les résultats de recherche, vous pouvez utiliser le Noindex.
Vous pouvez aussi l’effectuer avec l’outil Yoast seo. Voici donc comment noindexer les pages de l’auteur unique avec cet outil :
- Connectez-vous à votre site wordpress : Une fois connecté, vous irez sur le tableau de bord ;
- Cliquez sur utilisateur : Vous verrez le bouton « utilisateurs », dans le menu à gauche ;
Source : Yoast
- Dirigez-vous vers tous les utilisateurs ;
Source : Yoast
- Choisissez dans la vue d’ensemble des utilisateurs, le bon profil d’utilisateurs à modifier ;
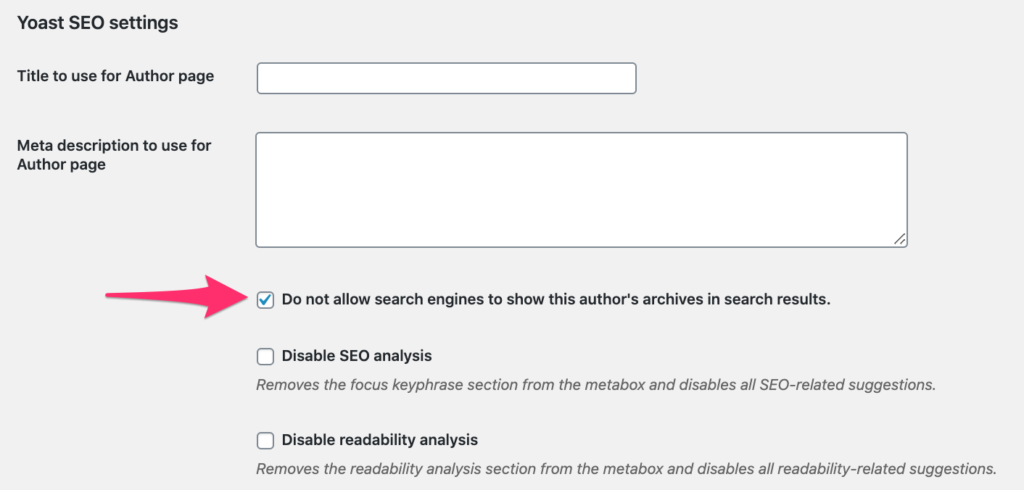
- Arriver sur la page sur laquelle vous voulez modifier le profil, sélectionnez la case qui dit de ne pas utiliser les archives de l’auteur dans les résultats de recherches. Cela indiquera à Google qu’il ne doit pas indexer la page de cet auteur.
Source : Yoast
1.3.2. Certaines formes de publications personnalisées
Il peut arriver qu’un programmeur web ou un plugin ajoute au site des types de pages personnalisées, que vous n’aimeriez pas forcément voir indexer. Par exemple, certains sites de e-commerce peuvent ajouter des spécifications telles que les dimensions et le poids en tant que type de message personnalisé.
Source : Road to Blogging
Ce genre de contenu est considéré comme des contenus de faible qualité. Vous verrez alors que ces pages ne sont d’aucune utilité ni pour les internautes ni pour Google, et donc elles ne doivent pas figurer parmi les pages de résultats de recherche.
1.3.2.1. Page de remerciement
La page de remerciement a pour seul but de remercier le client ou les abonnées à votre newsletter.
https://i.pinimg.com/originals/e7/4f/0c/e74f0c0edd1b8c0c81d4210ce8388d40.jpg
Ce sont souvent des pages de faible contenu, avec des possibilités de ventes additionnelles et de diffusion sociale, mais qui ne procurent aucune valeur pour les internautes qui prennent par Google pour trouver de bonnes réponses à leurs requêtes. Dès lors, ces pages ne devraient pas apparaître dans les SERPs de Google.
1.3.2.2. Pages des administrateurs ou de connexion
La majorité des pages de connexion devraient être exclues de Google. Mais ces pages y figurent souvent. Je vous conseille de garder les vôtres en dehors de l’index de Google en y ajoutant une balise noindex.
Source : Behance
Celles qui doivent faire l’œuvre d’exception sont les pages de connexions aux services d’une communauté tels que Dropbox ou les plateformes similaires.
Posez-vous la question de savoir pourquoi vous chercheriez une page de connexion sur Google, alors que vous n’intervenez pas sur le site en question. S’il n’y a aucune chance que vous fassiez de telles recherches, on peut dire que Google n’a pas besoin d’indexer ces pages de connexion.
Par ailleurs, si vous vous servez de WordPress, vous ne risquez rien, puisque le CMS ne peut pas effectuer l’indexation automatique de la page de connexion du site lui-même.
1.3.2.3. Résultats de recherche interne
Les résultats de recherches sont pratiquement les dernières pages vers lesquelles Google voudrait diriger ses utilisateurs. Si vous souhaitez perturber l’expérience de recherche, vous devez créer un lien vers d’autres pages de recherche et non vers une vraie page de résultat.
Par contre, les liens qui figurent sur les pages de résultats de recherche possèdent toujours une grande valeur. Par conséquent, tous ces liens doivent être suivis. La configuration de robots méta pour faire suivre ces liens est :<meta name= » robots » content= »noindex, follow »>.
1.4. Listes de types de contenu à définir sur noindex avec l’outil Yoast SEO
Voici une liste de types de contenu sur laquelle vous pouvez ajouter une balise noindex avec l’outil Yoast SEO.
1.4.1. Articles, pages, médias ou éléments de taxonomie individuels.
La partie réservée aux paramètres avancés dans le champ méta yoast SEO de l’écran d’édition des éléments de contenus offre aux administrateurs et aux éditeurs la possibilité de définir des informations personnalisées concernant les directives, telles que noindex et nofollow ainsi que d’autres paramètres avancés liées aux directives.
Pour effectuer le noindex d’un article individuel, réglez le paramètre « Autoriser les moteurs de recherche à afficher ce… dans les résultats de recherche » sur « Non ».
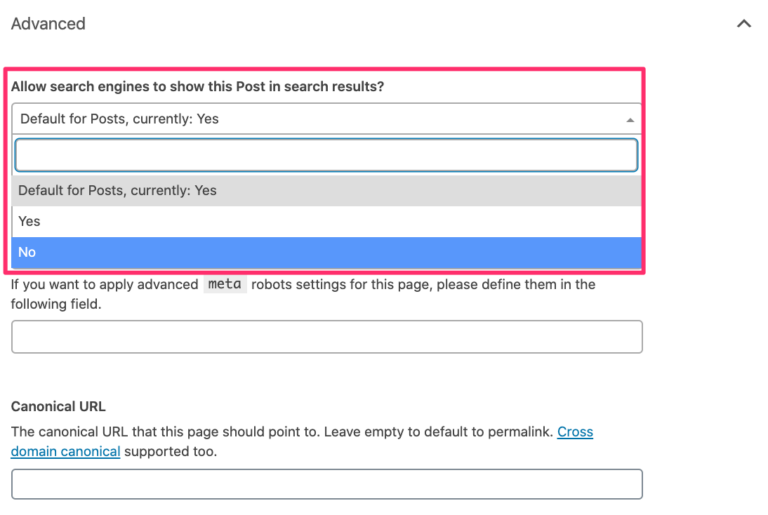
Source : yoast
La présentation peut être différente, car l’exemple ci-dessus est tiré d’un type de message par défaut.
1.4.2. Noindex d’un article d’actualité individuel
Le plugin yoast seo new vous donne la possibilité d’indiquer à Google news, qu’il ne doit pas indexer un article d’actualité donné. Vous trouverez cette option dans la section plugins de la zone méta dans « Google news ».

Source : yoast
1.4.3. Noindex des types de post, catégories, tags ou autres taxonomies
Si vous souhaitez ne pas indexer un groupe d’éléments, mettez en place cette fonctionnalité en suivant les étapes ci-dessous. Par défaut, les pages 404 et les pages de recherche sont définies sur noindex.
- Connexion à votre site web WordPress : Une fois connecté, vous serez sur votre tableau de bord ;
- Sélectionnez « SEO » : à gauche de l’écran vous verrez un menu, sur celui-ci cliquez sur SEO ;
- Cliquez sur « Apparence de recherche » ;
Source : Yoast
- Choisissez l’onglet qui représente le genre de contenu, la taxonomie ou le type d’archive que vous voulez supprimer des résultats de recherche ;

Source : Yoast
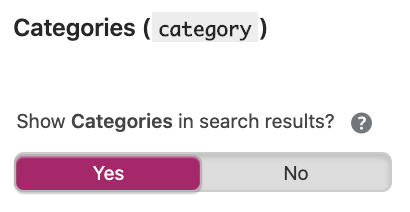
- Activez le bouton « Afficher XYZ dans les résultats de recherche » : Pour indexer le contenu, mettez le bouton sur « oui », dans le cas contraire mettez « non » ;
Source : Yoast
- Sélectionner « Enregistrer les modifications »;
1.4.4. Noindex d’un site entier
Il est également possible d’empêcher l’intégralité d’un site d’être indexée, mais cela revient aux moteurs de recherche d’honorer cette demande. Voici comment effectuer le noindex d’un site entier sur Yoast SEO :
- Connectez-vous à votre site wordpress : lorsque vous êtes connecté, vous atterrissez sur votre tableau de bord ;
- Sélectionnez « paramètres » : À votre gauche, vous trouverez un menu, c’est dans celui-ci que vous trouverez les paramètres ;
Source : yoast
- Sélectionnez l’option « lecture » ;
Source : yoast
- Ensuite, marquer la case « découragez les moteurs de recherche d’indexer ce site » ;
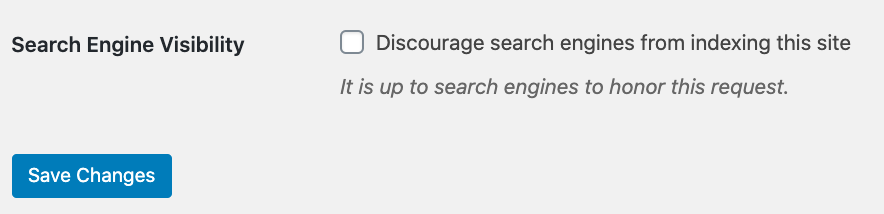
Source : yoast
- Enfin, sélectionnez « enregistrer les modifications ».
1.4. Quand utiliser « noindex » et « nofollow » séparément ?
Lorsque vous intégrez une balise « nofollow » à une page internet, elle empêche les moteurs de recherche d’explorer les liens qui figurent sur ladite page. Cela veut également dire que toute autorité de positionnement dont jouissent les pages dans les SERPs ne sera pas transférée aux pages auxquelles cette balise renvoie.
Comme ça, toute page ayant une directive « nofollow » constatera que ses liens ont été ignorés par Google, de même que par les autres moteurs de recherche.
Vous devez savoir que vous pouvez ajouter une directive « noindex » seule ou accompagnée d’une directive « nofollow ». Ou vice versa, c’est-à-dire ajouter seule la directive nofollow.
Mais savez-vous quand réellement utiliser de façon séparée « noindex » et « nofollow » ?
En effet, n’ajouter que la balise noindex lorsque vous n’aimeriez pas qu’un moteur de recherche comme Google procède à l’indexation de votre page, mais que vous acceptez qu’il suive les liens inclus sur celle-ci. Ce qui permet de donner une autorité de classement aux autres pages vers lesquelles votre page renvoie.
Les pages de destination payantes représentent une bonne illustration de ce fait. En effet, il ne faut pas que les moteurs de recherches indexent les pages de destinations pour lesquelles les internautes doivent payer, mais il faut que les pages auxquelles elles sont liées bénéficient de leur autorité.
Vous ne devriez ajouter seulement une balise nofollow, si vous voulez qu’un moteur de recherches ne suive pas les liens de votre page web, mais qu’il indexe la page. Il n’y a pas beaucoup d’exemples de cas où une page entière peut être marquée d’une balise « nofollow » sans être accompagnée d’une balise « noindex ».
Lorsque vous réfléchissez à ce que vous devriez faire pour une page donnée, il faut plutôt se demander s’il faut ajouter la balise « noindex » avec ou sans la balise « nofollow ».
1.5. Quand utiliser noindex et nofollow de façon combinée ?
Il est recommandé d’utiliser à la fois la balise nofollow et noindex, lorsque vous n’aimeriez pas que Google ou les autres moteurs de recherche indexent une page dans les résultats de recherche et que vous n’aimeriez pas également qu’il suive les liens de cette page.
Les pages de remerciement représentent l’illustration parfaite de ce fait. En effet, vous ne souhaitez pas que les moteurs de recherche puissent indexer votre page de remerciements ni qu’ils suivent le lien vers vos offres et commencent à indexer le contenu de ces offres.
Voici les étapes pour ajouter ensemble ou séparément une balise nofollow et noindex.
1.5.1. Étape 1 : Copiez l’une des balises suivantes
Dans le cas de noindex utiliser séparément et que nous avions déjà vu un peu plus haut :
<META NAME= » robots » CONTENT= » noindex »>
Dans le cas de nofollow :
<META NAME= » robots » CONTENT= » nofollow »>
Lorsque nofollow et noindex sont combinés ça donne ceci :
<META NAME= » robots » CONTENT= » noindex, nofollow »>
1.5.2. Étape 2 : Ajoutez la balise à la partie <head> du code HTML de la page
Il s’agit d’ajouter la balise à l’en-tête de la page web. Vous n’avez qu’à coller de façon manuelle la balise dans le code de votre page web. Ça peut paraître compliqué au premier abord, mais ne vous inquiéter pas, car c’est très simple. Voici comment procéder :
Premièrement, il faut que vous ouvriez le code source de la page que vous aimeriez désindexer. Après, coller l’intégralité de la balise au sein d’une nouvelle ligne de la section <head> du code HTML de la page ou de l’en-tête de la page. Les écrans capturés ci-dessus vous aideront dans le processus.
La balise <head> veux dire le début de votre en-tête :
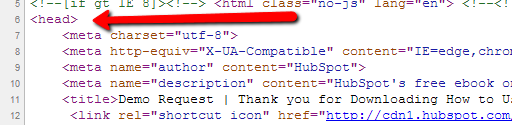
Source : hubspot
Voilà la méta balise pour « noindex » et « nofollow » collée dans l’en-tête :
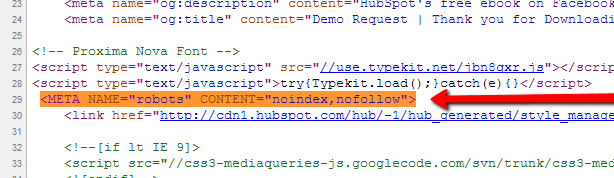
Source : hubspot
La balise </head> indique la fin de l’en-tête :
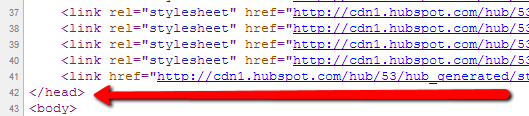
Source : hubspot
Et voilà, c’est fait. Cette balise ordonne aux moteurs de recherche de se retourner en excluant la page de tous les résultats de recherche.
1.6. Différence entre la directive noindex et disallow dans un fichier robots.txt
Lorsque vous vous servez de la directive disallow dans un fichier robots.txt, vous êtes en train d’indiquer aux moteurs de recherche de ne pas explorer les zones qui sont définies dans ce fichier.

Cette directive est employée par exemple pour des fichiers comme ceux des images contenues dans de grandes bases de données afin d’économiser le précieux Budget crawl des moteurs de recherche.
En revanche, il ne faut pas utiliser cette directive, si vous désirez que tel ou tel contenu ne soit pas indexé. Même si la commande disallow interdit l’exploration d’une page spécifique, celle-ci peut tout de même être affichée dans l’index, si des backlinks provenant des autres sites web pointent vers elle.
Voilà pourquoi, il ne faut jamais cumuler noindex et disallow sur la même page. Puisque les robots accèdent généralement au fichier robots.txt en premier. Quand ils indexent un site web, ces crawlers remarquent d’abord la directive disallow et renoncent donc à explorer les sous-pages qui sont incluses.
Il en résulte que les robots ne parviennent pas à détecter les éventuelles directives noindex sur ces pages et peuvent toujours inclure les pages secondaires dans l’index, si celles-ci sont reliées par des backlinks.
Si l’on ne souhaite pas qu’une page particulière soit comprise dans l’index des moteurs de recherche, il convient donc d’utiliser exclusivement des directives noindex.

À lire également comment créer des backlinks.
Vous savez à présent, ce qu’est une directive noindex, et son mode de fonctionnement. Voyons maintenant les meilleures pratiques de référencement pour les directives noindex.
Chapitre 2 : 03 meilleures pratiques de référencement pour les directives noindex.
Dans ce chapitre, je vous montrerai les 03 meilleures pratiques de référencement pour les commandes noindex. Mais avant d’aborder les étapes, je vous montre les raisons pour lesquelles noindex peut améliorer le référencement ainsi que comment s’en servir pour accroître la visibilité dans les résultats de recherche.
2.1. Pourquoi noindex peut-elle améliorer le référencement ?
Arrivé à ce niveau, je peux clairement m’imaginer que vous vous demandez comment une commande qui est destinée à supprimer des pages de l’index des moteurs de recherche peut vous permettre d’optimiser vos performances sur les moteurs de recherche.
Voici la situation : il existe des pages que vous ne voudrez pas simplement qu’elles s’affichent dans les SERPs des moteurs de recherche. Croyez-vous qu’un utilisateur voudrait tomber sur une quelconque page de votre site ? Est-ce réellement utile pour ceux-ci ? Est-ce qu’ils y pourront trouver des réponses à leurs requêtes ?
Vous vous dites sûrement qu’au moins, ils auront atterri sur votre site et que quelques-uns parmi ces personnes pourront trouver ce qu’ils recherchent, ou même pourront finalement devenir des clients.
Ce raisonnement est en partie vrai. Mais ce n’est pas aussi facile que cela ne le paraît. En fait, que se passera-t-il si une quelconque page de votre site internet obtient un classement plus élevé que celle qui correspond le mieux au besoin de l’utilisateur ?
En effet, les pages pertinentes peuvent se trouver dans l’index, sans pour autant figurer dans les SERPs, puisque l’algorithme de Google cherche souvent à éviter de placer plusieurs pages du même site internet dans ses résultats. Tandis que les pages d’archive les moins pertinentes peuvent occuper finalement sa place.
En faisant le noindex des pages d’archives, des pages de balises ou des pages identiques, vous pouvez empêcher ces problèmes de se produire. Et mieux référencer votre site pour les meilleures pages concernées.
2.2. Comment utiliser NoIndex pour accroître la visibilité dans les résultats de recherche ?
D’après une étude de cas réalisée par Harrison Jones, nous pouvons voir la manière dont l’utilisation de la balise noindex peut générer plus de trafic de référence lorsqu’elle est utilisée convenablement.
Voici comment s’est passée l’expérience de Harrison : Ce dernier à effectuer le noindex des pages de taxonomie (tout comme les pages de catégories et de balises) sur un domaine. Prit de façon isolée, ce fut une mauvaise décision, ce qui fit chuter le trafic de 20 %.
En revanche, après avoir amélioré la mise en page (pagination) à l’aide des balises rel=next et rel=prev, le nombre de visiteurs est reparti en flèche.
Sur un second site, il a tenté d’améliorer la pagination sans employer la directive noindex. Il n’en résulte aucun changement notable.
Sur deux derniers sites, il a amélioré la mise en page et effectué le noindex des pages de taxonomie. Cette approche a porté ses fruits. Le trafic a en effet augmenté de 30 % sur un site et de 20 % sur le second.
Par conséquent, à elle seule, la balise noindex peut affecter la visibilité de votre site web dans les résultats de recherches, mais si elle est combinée à une mise en page optimisée elle accroît véritablement votre visibilité dans les SERP.
2.3. Les 03 bonnes pratiques pour le référencement appliqué aux directives noindex
2.3.1. Ne plus utiliser noindex sur des pages importantes
Le fait d’inclure de manière accidentelle la balise noindex sur une page importante peut avoir pour effet de supprimer cette page des index des moteurs de recherche et de mettre fin à la réception de tout trafic organique.
À titre d’exemple, lorsque vous lancez une nouvelle version de votre site web, mais que vous oubliez les balises « noindex », qui avaient pour but d’empêcher les moteurs de recherche d’effectuer l’indexation des nouvelles variantes de la page avant que celle-ci ne soit prête.
Ainsi, la nouvelle version du site web peut cesser systématiquement de générer du trafic sur les moteurs de recherche.
2.3.2. Sachez que « noindex » est maintenant traité comme “nofollow”
Les détenteurs de sites se servent souvent des balises métarobots, ainsi que des en-têtes de réponses afin d’indiquer aux moteurs de recherche de ne pas effectuer l’indexation des pages actuelles, mais de continuer l’exploration des liens de page :
<meta name= » robots » content= »noindex, follow » />
Ceci est généralement appliqué aux pages de liste paginées. À titre d’exemple, “noindex, follow” peut être utilisé sur les archives d’un blog, afin que les pages d’archives n’apparaissent pas dans les résultats de recherche.
Ceci tout en permettant aux moteurs de recherche d’effectuer l’exploration, l’indexation, et le classement des articles du blog eux-mêmes.
Toutefois, cette démarche est susceptible de ne pas fonctionner comme souhaité, puisque Google a déclaré que son système traitait finalement une directive « noindex, follow » comme un « noindex, nofollow ». Autrement dit, ils arrêteront de faire l’exploration des liens de toutes les pages qui comportent une balise « noindex ».
Cette situation risque d’empêcher l’indexation des pages de destinations des liens ou encore de diminuer leur pagerank, ou leur autorité. Ce qui diminue leur rang par rapport aux mots clés pertinents.

2.3.3. Ne pas employer les règles « noindex » dans les fichiers Robots.txt
Google déconseille cette utilisation des fichiers robots.txt pour paramétrer les directives « noindex » et a supprimé le code qui prenait en charge ces règles en septembre 2019.
Même s’ils n’ont jamais apporté de soutien officiel, les moteurs de recherche ont respecté pendant un certain temps les directives « noindex » contenues dans les règles robots.txt.
Étant donné que les fichiers robots.txt contenant des caractères génériques peuvent être utilisés sur plusieurs pages à la fois sans avoir à modifier les pages elles-mêmes, cette approche a tout de même été privilégiée par de nombreux webmasters.
Résumé
Si vous désirez tout simplement ne pas voir une page spécifique être indexée par les moteurs de recherche, vous savez désormais quoi faire. Il vous suffit d’utiliser la balise noindex sur l’en-tête de réponse des pages concernées et le tout est joué.
Dans cet article, je vous ai montré comment utiliser convenablement noindex sur une page. Après, j’ai eu à présenter les différents types de pages qui ne doivent pas figurer dans les moteurs de recherche et qui doivent être cependant noindexer.
Noindex et nofollow sont deux balises qui diffèrent l’un de l’autre, mais qui se complètent. C’est alors que j’ai pris le temps de vous décrire dans quelle condition, ils peuvent être cumulés ou peuvent être utilisés de manière séparée.
La balise noindex bien qu’elle a pour particularité d’ordonner aux moteurs de recherche la non-indexation des pages peut également participer d’une manière ou d’une autre au référencement de votre site, les pratiques menant à de tels résultats ont été également abordées dans cet article.
Nous sommes à la fin de notre article. J’attends vivement vos commentaires.



Il est intéressant de noter que dans le blog de google « blog.google » ils n’utilisent le fichier robots.txt que pour déclarer le sitemap.xml et pour disallow les pages générées par les recherches internes
Ils recommandent et appliquent majoritairement le noindex via la valide meta de se que j’ai pu voir