
A web crawler or robot (also called “crawlers”, “indexing robots”, or “web spiders”) is an automated program that methodically navigates the web for the sole purpose of indexing web pages and their content. These robots are used by search engines to crawl web pages in order to renew their index with new information. Thus, when Internet users make a particular request, they can easily and quickly find the most relevant information.
When you make a query on a search engine, you will get as a result, a well ranked list of websites.
Before these websites appear in the SERPs, a process known as crawling andindexing is done behind the scenes by the search engines
The main actor at the heart of this machinery is the indexing robot also called crawler.
In this case :
- What is a robot or a crawler?
- How do they work?
- What is its importance in SEO ?
- What is indexing and what role do robots actually play?
- What is the difference between web crawler and web scraping?
These are all questions whose answers will allow us to clearly understand the definition of crawler and everything that surrounds it.
Let’s go !
Chapter 1: What do we really mean by Crawler or crawler?
Functional units of search engines, crawlers or robots are at the heart of the vast majority of web actions and interactions
Understanding Internet search clearly requires an exhaustive knowledge of its concepts
So, in this chapter, I will expose robots or crawlers in their smallest details.










1.1. A Crawler: What is it?
Before approaching the crawler in its functioning and its applications, it is essential to recall its origins and to give its true meaning.

That said, here is the history and the real meaning of the crawler.
1.1.1. Crawlers or indexing robots since the advent of the web
Indexing robots are now known under many names
- Crawler ;
- Exploration bots ;
- Spiders ;
- Web spider ;
- Search engine software ;
- And many other names.

Originally, the very first crawler was called WWW Wanderer (short for World Wild Web Wanderer)
This indexing robot designed and based on Perl (a stable, cross-platform programming language) was tasked in June 1993 with evaluating the growth of the Internet, which was still in its infancy
At that time, the WWW robot Wanderer was browsing the Internet collecting data that it recorded in the index of the moment, the very first Internet index: thewandex index
In its early days, Wanderer only crawled web servers. Shortly after its full introduction, it then started tracking URLs.
Contrary to what one might think, Wanderer with its Wandex index was not the first search engine on the Internet. It is actually the archietic search engine developed by Alan Emtage
However, with its Wandex index, Wanderer was definitely the closest thing to a general-purpose web search engine like today’s Google and Bing search engines.
Following the WWW Wanderer, in 1994 the first web browser appeared: the Webcrawler. Today, it is the oldest search engine (metasearch engine) still present and functional on the Internet.
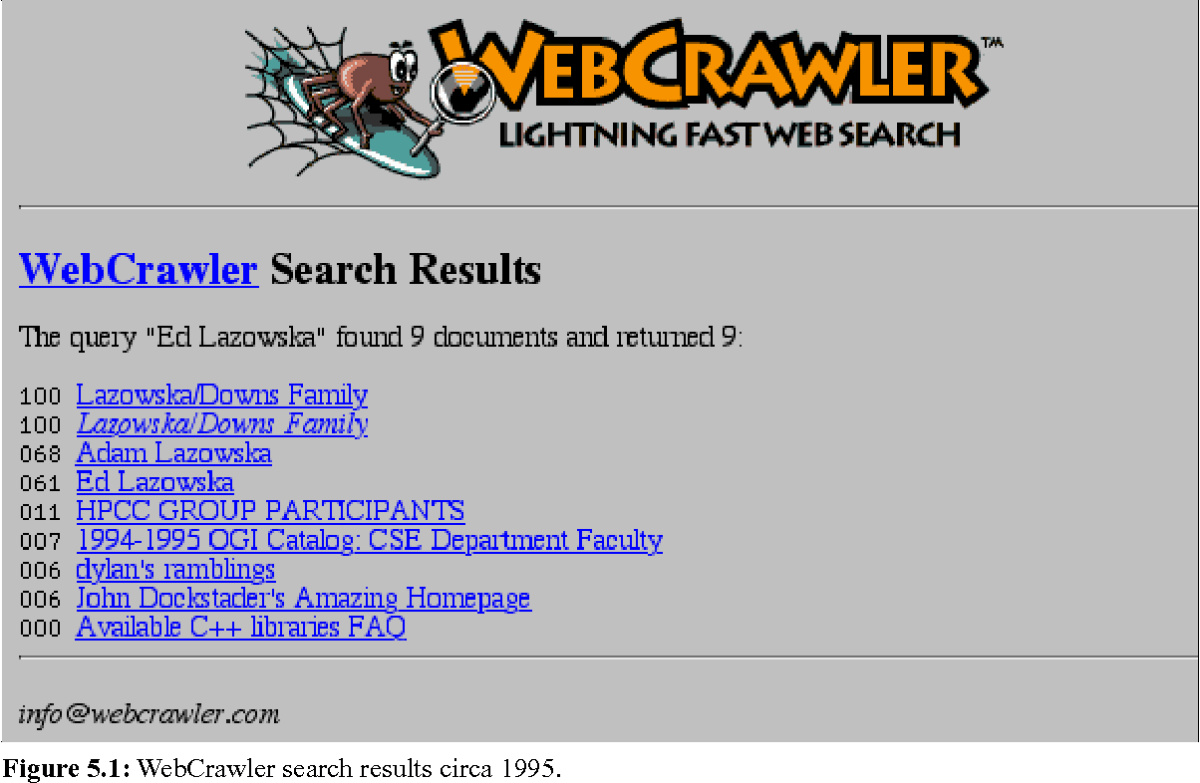
In the perpetual evolution of the web, many improvements have followed one another and the search engines and their indexing robots have changed and been perfected.
The history of Internet search and crawlers has just been swept up in these broad outlines.
However, what is the real meaning of the word crawler?
1.1.2. A Crawler: What does it really mean?
Named after the oldest existing search engine (Webcrawler), crawler is an English word that literally means “to sneak”, “to crawl”, “to scan”… So many opportune correspondences that clearly express the very essence of indexing robots
At the risk of repeating ourselves, an indexing robot is a computer program, a software that scans the Internet in a controlled way, locating and analyzing web pages with a specific goal
Like a spider with its web, the crawler explores and analyzes the web. This analysis concerns the different web pages, their contents and all their ramifications
The crawler thus in search of data, will record and store in indexes and / or databases, the various information collected
We can understand why these robots are also called spiders or web spiders.

These indexing robots are, in 99% of cases, still used by search engines. They allow search engines to build structured indexes and to optimize their performance as search engines (e.g. presentation of new relevant results).
In the remaining 1% of cases, crawlers are used to search for and collect contact and profile information (email addresses, RSS feeds and other) for marketing purposes.
To make it simple, let’s take the famous example of the librarian. In this example, the search engine bot is a librarian in charge of inventorying all the books and documents (sites and web pages) of a huge and completely disorganized library (the web).
The bot has to create a summary table (index of the search engine) that will allow readers (Internet users) to quickly and easily access the books (information) they are looking for
In order to order and classify (index) the books (websites) by centers of interest and then to make the inventory, the librarian (crawler) will have to inquire for each book, its title, its summary and the subject which is treated there
But unlike a library, on the Internet, websites are connected to each other by hyperlinks, which are used by bots to move from one site or web page to another.
In short, this is what the crawler represents and what it is responsible for. Now we just need to know how it works.
1.2) How does an indexing robot or crawler work?










The crawler is above all a program, scripts and algorithms whose set of tasks and commands are defined in advance
Like a good little soldier, it assiduously follows the instructions and functions predefined in its code in an automatic, continuous and repetitive way
By surfing the web through hyperlinks (from existing websites to new ones), spiders index both content and URLs. They analyze keywords and hashtags and make sure that the HTML code and links of the indexed sites are recent.
As the famous African proverb states, “It is at the end of the old rope that the new one is woven.”
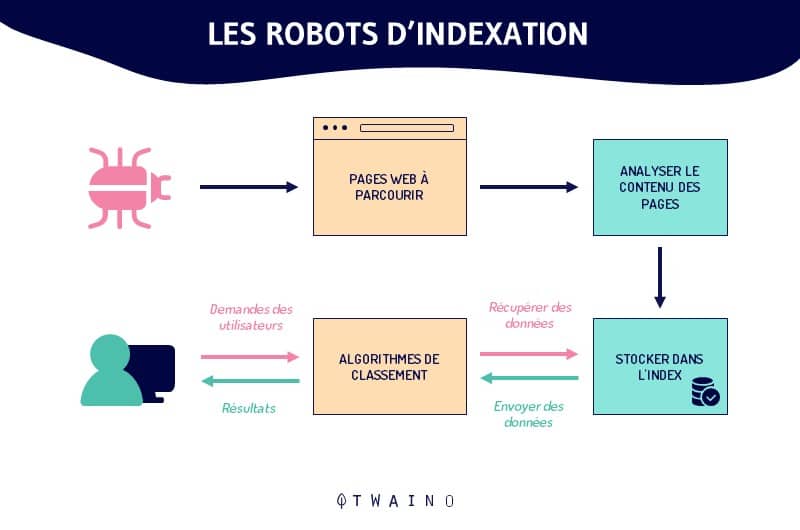
As the web is constantly growing, it is impossible to accurately assess the total number of pages existing on the Internet
In order to accomplish their tasks, crawlers start their exploration from a list of known URLs
Thus, the exploration is done according to a very simple scheme
Old known URLs => indexed web pages => hyperlinks => new URLs to explore => web pages to index => so on..
Far from working randomly, the indexing robots obey certain guidelines that give them a meticulous selectivity in the choice of pages to be indexed as well as in the order and frequency of the indexing of these pages.
Thus, an indexing robot determines the page to be indexed first according to
- The number of backlinks leading to the page (the number of external pages to which this page is linked) ;
- The internal linkage (the links between the different pages of the same website) ;
- The traffic of the page (the mass of visitors received on the page in question);
- The elements attesting to the quality, relevance and freshness of the information contained on the page (the Sitemap, the meta-tagsmeta-tags, the Canonical URLss, etc.);
- The protocol robots.txt (the file containing groups of directives for the bots) ;
- And so on.
Depending on the search engine, these factors are considered differently. It is therefore understandable that not all search engine bots behave in the same way.
1.3. What are the different types of Crawlers?
Sharing the same general operating principles, crawlers are mainly distinguished by their focus and scope
Yes, in addition to search engine indexing robots, there are many other categories of crawlers.










1.3.1. Search engine bots
These crawlers are without a doubt the very first crawlers that ever existed
They are known as searchbots. A name justified by the fact that they are designed with the intention of serving search engines in the optimization of their field of action and especially of their database.
Among the most famous ones, we remember the following searchbots:
- Google’s Googlebot: the most used searchbot on the net and whose index is the richest;
- The Bingbot of Bingthe search engine of Microsoft;
- The Slurpbot from Yahoo ;
- The Baidu Spider of the Chinese search engine Baidu
- The Yandex Bot from Yandexthe Russian search engine
- The DuckDuckBot from DuckDuckGo ;
- Facebook’s Facebot ;
- Amazon’s Alexa Crawler ;
- And more.
1.3.2. Desktop Crawlers
These are mini crawlers with very limited functionality. Their low competence is compensated by their relatively insignificant cost
They are bots that can be run directly from a personal laptop or PC and can only process a very small amount of data.
1.3.3. Personal web crawlers
A category of crawlers designed for companies and which are used for example specifically to inform about the frequency of use of certain hashtags/keywords
As an example we can mention:
- The VoilaBot of the telecommunication company Orange
- The OmniExplorer_Bot from the company OmniExplorer
- And many others.
1.3.4. Commercial Crawlers
These are algorithmic solutions offered for a subscription fee to companies that personally need a crawler. The crawlers act as paid tools that allow companies to save huge time and financial resources needed to design their own crawler.
As an example of paid crawler software, we can mention the following:
- Botify ;
- SEMRush ;
- Oncrawl ;
- Deep Crawl ;
- Etc
1.3.5. Website bots in the cloud
The particularity of these website crawlers lies in the fact that they are able to save the collected data on the cloud
This is quite an advantage over other crawlers that simply store the information on local paid servers of IT companies.
On top of that, accessibility to data and analysis tools is much better. No more worries about localization and logistical compatibility.
1.4. What should we remember about indexing (Google) in Internet search?
The portion of the web accessible to the public and really searched by robots remains undetermined
It is roughly estimated that only 40 to 70% of the net is indexed for search, i.e. several billion URLs.
If we take the example of the librarian above, the action of prospecting, classifying and cataloguing the books (sites and web pages) of the library represented the indexing of the Internet search.

Indexing is therefore a practical term that designates all the processes following which the crawler scans, analyzes, organizes and arranges the pages of the websites before proposing them in the SERPs
It is a crucial aspect of natural referencingbecause it consists of the insertion and consideration of web pages in the index of search engines
This first step of the organic search engine optimization is not enough to ensure the appearance and positioning of the web pages in the SERPs.
Thanks to the continuous updates of the Google index, and especially with the implementation of Caffeinethe Google indexing has evolved more
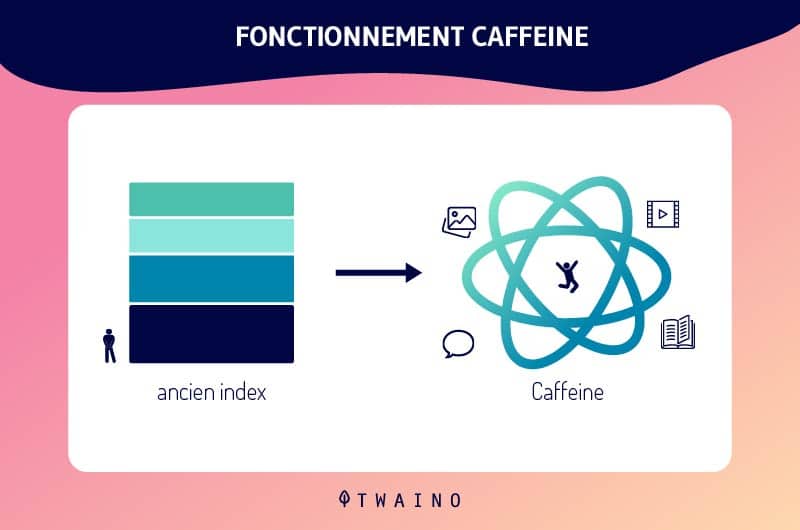
Therefore, new contents and/or new web pages are promptly indexed and their appearance in the SERPs is done directly.
All this aside, it is crucial to remember that the pages and content of your website will not be indexed by the Googlebot until it has found them. This essential step of the Google indexation is controllable.
Indeed, there are several solutions to make your resources visible by Google. The search engine itself offers interesting and efficient alternatives on the subject.
Chapter 2: A Crawler in application: What does it do?
The presentations are done, now let’s get to the heart of the matter.
What are the contributions, advantages and SEO importance of crawlers?
2.1. In practice, how do crawlers work?
As we have seen, the behavior of crawlers is predefined and integrated in their lines of code. The factors governing the indexation of web pages are thus weighted accordingly according to the bots and according to the goodwill of search engines.
In practice, the action of the indexing bots is decided in several stages.
First, the search engines must determine the target and/or the preferences of these robots. The exploration policies of the websites, especially the types of URLs to be indexed, will be specified in the portion of data used as a safeguard called crawler frontier
In a second step, the recipients of the crawlers assign their robots a “seed” list that will serve as a starting point for indexing. This is a series of old known URLs or new URLs to explore.
Then, the search engines add to the program of the bots, the frequency of exploration and treatment to be given to each of the URLs.
Finally, the crawlers are trained to respect the directives of the robots.txt file and/or the nofollow HTML tags, unlike the spambots
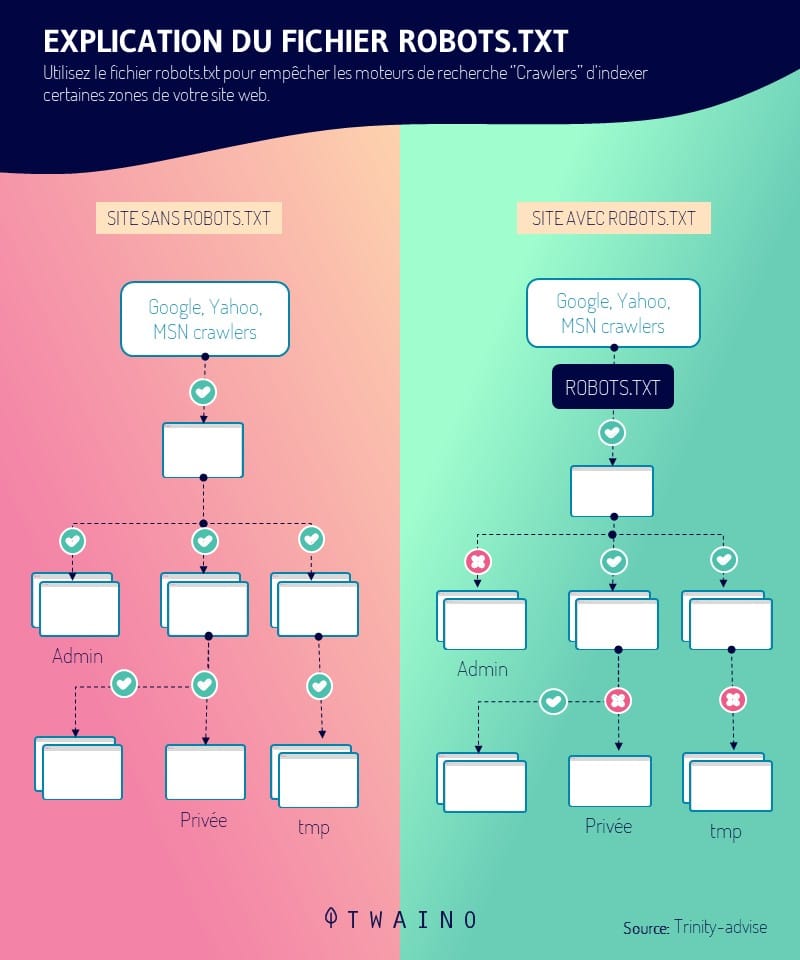
Thus, the indexing robot in accordance with the guidelines of the robots.txtprotocol, will be instructed to avoid all or part of a website.
2.2. An indexing robot : What does it bring ?
The crawler in its applications offers various advantages in many areas.
The first advantage of a crawler is its ease of use and its ability to simplicity of use and in its capacity to to ensure a continuous and complete collection and processing of data.
Its unparalleled efficiency in the accomplishment of its functions of exploration and indexation of the web content is also a precious advantage
And for good reason, by carrying out the prospecting, analysis and indexing of the web in place of humans, robots allow an incredible saving of time and money.
In a perspective of SEO (Search Engine Optimization), the crawler allows to increase the organic traffic of a website and to stand out from the competition
To do this, it provides information on search terms and the most popular keywords.

In addition to these main advantages, crawlers are also used in many other disciplines, such as
- E-marketing optimization by analyzing the company’s customer base;
- Data mining and targeted advertising by collecting public e-mail and/or postal addresses of companies;
- Evaluation and analysis of customer and company data for the purpose of improving the company’s marketing strategies;
- Creation of databases;
- The search for vulnerabilities through continuous monitoring of systems;
- And many others.
Chapter 3: What is the importance and role of Crawlers in SEO?










The role and importance of crawlers in indexing is no longer in question. However, their partitions and their interests in the SEO strategy are still a bit unclear.
3.1. The place of crawlers in SEO
The importance of crawlers for SEO is intimately linked to their ability to establish the necessary conditions for the appearance of a website in the SERPs
The objective of SEO is to obtain considerable organic traffic generated by natural results.
In other words: To be among the first results of search engines.

The exploration and indexing of web pages by crawlers is the basis for appearing among the results of search engines. In fact, it is not enough to appear in the SERPs, but it is an essential step.
3.how does the web crawler help SEO experts?
Search engine optimization is all about improving a website’s ranking in the SERPs. This is done by optimizing the technical and non-technical factors of the page for these search engines.
The SEO implications of the web crawler are huge since it is their job to index your site before the algorithms determine if it deserves a place on the first page
Here are two (02) tips to get them to index your important pages efficiently:
3.2.1. Internal linking
By placing new backlinks and additional internal links, the SEO professional makes sure that the crawlers discover the web pages from the extracted links to make sure that all the pages of the website end up in the SERPs.
3.2.2. Submitting the sitemap
Creating a sitemaps (site maps) and submitting them to search engines helps SEO, as these sitemaps contain lists of pages to crawl
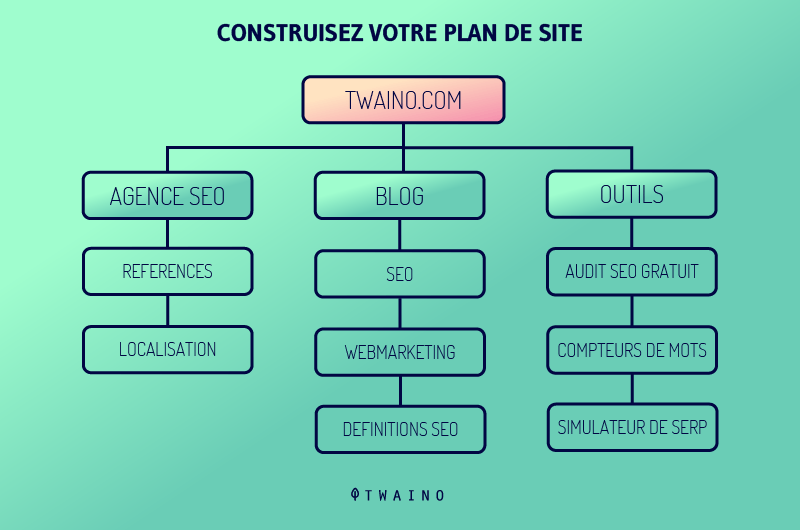
The crawlers will be able to easily discover the content hidden deep in the website and crawl it in a short period of time, thus producing a presence of the important pages of the website in the search results.










3.3. Best practices to improve your SEO with crawlers
The optimization of its SEO strategy depends mainly on the optimization of its crawl budget (the crawl or exploration budget). This is the period of time as well as the quantity of web pages that the crawlers can explore and analyze for a website.
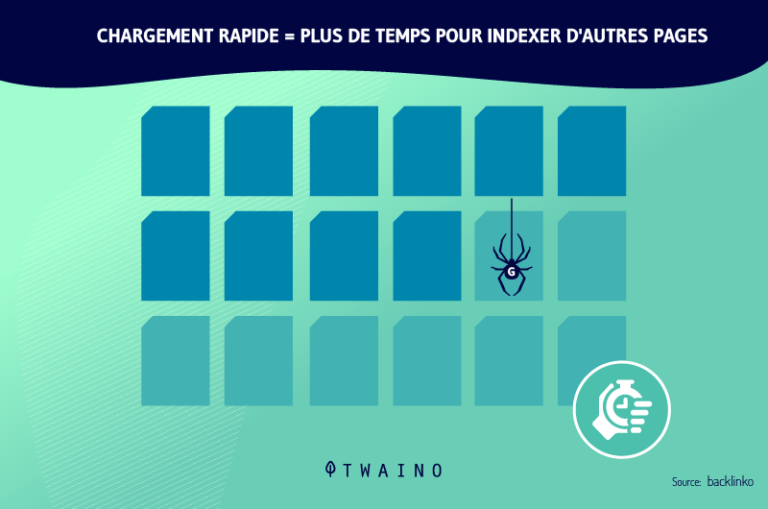
The optimization of this budget involves improving the navigation, architecture and technical aspects of the website. It is then advisable to adopt among others, the good practices practices:
- Submit an XML Sitemap via GSC (Google Search Console). This is a non-standard directive in robots.txtfile, which guides the crawlers by telling them which pages to prioritize for crawling and indexing.
- Do a full audit of the website. The goal is to improve factors such as keywords, page load speed, etc.
- Build an optimal netlinking strategy with backlinks and a solid internal linkage. On the one hand, this consists of obtaining links from other websites that are already indexed and whose frequency of exploration by crawlers is high. And on the other hand, it is about intelligently linking the different pages of the website together to allow the crawlers to easily move from one page to another.
- Inspect URLs, content and HTML code in order to remove or update obsolete, superfluous, questionable or irrelevant elements.
- Opt for explicit and relevant meta-tags, quality content, canonical URLs..
- Avoid duplicate contentand cloaking and all BlackHat SEO practices.
- Ensure the accessibility of the server hosting the website to search engine crawlers.
- Identify and correct the various elements blocking the indexing of web pages.
- Be attentive to updates and changes in search engine algorithms in order to always know the current SEO criteria.
3.4. Other use cases of crawlers beyond search engines
Google has started to use the web crawler to search and index content to easily discover websites by keywords and phrases
Search engines and computer systems have created their own web crawlers programmed with different algorithms. These crawl the Web, analyze the content and create a copy of the visited pages for further indexing
The result is visible, because today you can easily find any good information or data that exists on the Web.
We can use crawlers to collect specific types of information from web pages, such as
- Indexed notices from a feed aggregation application;
- Information for academic research;
- Market research to find the most popular trends;
- Best services or locations for personal use;
- Corporate jobs or opportunities;
- Etc.
Other use cases for crawlers include:
- Tracking content changes;
- Detecting malicious websites;
- Automatically retrieving prices from competitors’ websites for pricing strategy;
- Identifying potential best-sellers for an e-commerce platform by accessing competitor data;
- Ranking the popularity of leaders or movie stars;
- Accessing data feeds from thousands of similar brands;
- Indexing of the most frequently shared links on social networks;
- Access and index job listings based on employee reviews and salaries;
- Price comparison analysis and cataloging by zip code for retailers;
- Access to market and social data to build a financial recommendation engine;
- Discovering terrorism-related chat rooms ;
- Etc.
If you know about Web scrapingyou may be confusing it with web crawling. Now let’s see the difference:
3.5. Web crawler vs Web scraper: Comparison
Like the crawler, the scraper is a robot in charge of collecting and processing data on the web. But make no mistake, crawlers and scrapers are not the same kind of robots.
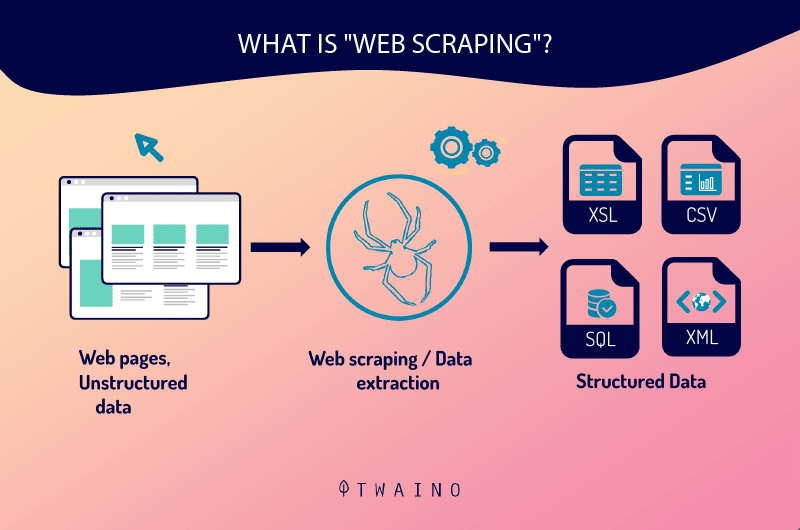
The web scraper is to the web crawler what yin is to yang, black to white, evil to good..
One is at the service of the lawful and the righteous, while the other sometimes serves the dark side
In reality, the scraper is a bot programmed to locate and duplicate in its entirety, usually without authorization, specific data belonging to the content of a website
After extracting this data, the scraper adds it as is or with minimal modification to databases for later use.
Although they are similar, the two bots are clearly different in several ways:
- Their main function
The crawler’s function consists exclusively in exploring, analyzing and indexing web content through the continuous consultation of old and new URLs. Scrapers, on the other hand, only exist to copy data from websites by following specific URLs.
- Their impact on web servers:
Unlike search engine crawlers that are diligent about following the guidelines of robots.txt files and make do with the metadata, scrapers don’t obey any rules.
Let’s see a quick case study of this concept of web scraping:
Case study
- First, by referring to to Terms of Service of June 7, 2017, Linkedin states the following through section 8.2.k
“You agree not to: […] develop, support or use any software, devices, scripts, bots or any other means or processes (including, without limitation, web crawlers, browser plug-ins and add-ons, or any other technology or physical work) to web scrap the Services or otherwise copy profiles and other data from the Services.”
Despite this, in a legal battle between Linkedin and an American start-up called HiQ Labs (regarding the use of web scraping practices for the exclusive collection of information belonging to the public LinkedIn profiles of a company’s employees), the court ruled as follows
The data that is present on the users’ profiles is public once it is published on the net and can in this case be freely collected via web scraping.
- Secondly, referring to digital-factoryweb scraping would be considered according to the article 323-3 of the French penal code as a “data theft”. This article states:
“The fact of fraudulently introducing data into an automated processing system, extracting, holding, reproducing, transmitting, deleting or fraudulently modifying the data it contains is punishable by five years imprisonment and a fine of 150,000 €. When this offence has been committed against a system of automated processing of personal data implemented by the State, the penalty is increased to seven years’ imprisonment and a €300,000 fine.”
Now it’s up to you to draw your conclusion from this concept of Web scraping.
Chapter 4 : Other questions about web crawlers
4.1. What is a crawler?
A web crawler is a software designed by search engines to automatically crawl and index the web.
4.2 What is Google crawling?
Crawling is the process by which Googlebot (also called robot or spider) visits pages in order to add them to the Google index. The search engine uses a vast array of computers to retrieve (or “crawl”) billions of pages on the Web
4.3. When is it crawling?
Crawling occurs when Google or another search engine sends a robot (or spider) to a web page or web publication to crawl the web page
Then these crawlers extract links from the pages they visit to discover additional pages on the website
4.4 How does the Google crawler work?
Web crawlers start their crawling process by downloading the website’s robot.txt file. The file includes sitemaps that list the URLs that the search engine can crawl. Once crawlers start crawling a page, they discover new pages via links
Thus, they add the newly discovered URLs to the crawl queue so that they can be crawled later. With this technique, these crawlers can index every page that is connected to others.
Since pages change regularly, search engine crawlers use several algorithms to decide on factors such as how often an existing page should be crawled and how many pages of a site should be indexed.
4.5. What is the anti crawler?
Anti crawler is a technique to protect your website from crawlers or indexers. If your website contains valuable images, pricing information and other important information that you do not want crawled, you can use meta robots tags.
4.6. How does Google work to provide relevant results to user queries?
Google crawls the web, categorizes the millions of pages that exist and adds them to its index. So when a user makes a query, instead of browsing the entire Web, Google can simply browse its more organized index to get relevant results quickly.
4.7. What are web crawling applications?
Web crawling is commonly used to index pages for search engines. This allows search engines to provide relevant results for user queries.
Web crawling is also used to describe web scraping, the extraction of structured data from web pages and the like.
4.8. What are examples of crawlers?
Every search engine uses its own web crawler to collect data from the Internet and index the search results
For example:
- Amazonbot is a web crawler from Amazon for web content identification and backlink discovery
- Baiduspider for Baidu ;
- Search engine Bingbot for Bing by Microsoft ;
- DuckDuckBot for DuckDuckGo ;
- Exabot for the French search engine Exalead ;
- Googlebot for Google ;
- Yahoo! Slurp for Yahoo ;
- Yandex Bot for Yandex ;
- Etc.
4.9. What is the difference between web crawling and web scraping?
Generally, theweb crawling is practiced by search engines through robots which consist in browsing and creating a copy of the page in the index
Unlike crawling, the web scraping is used by a human, always through a bot, to extract particular data, usually on a website, for possible analysis or to create something new
In summary
Crawlers and indexing are now concepts whose meaning and implications you master. Remember that these concepts are the daily life and the very essence of search engines
The crawler in its function of prospecting and archiving the web, conditions the presence and position of websites in the results of search engines
However, indexing robots, spiders or whatever you want to call them, are also used in many other fields and disciplines
From the functioning of the different protagonists of internet search to the good practices allowing its optimization, you now have a pretty clear idea of the whole subject.
Apply intelligently the knowledge you have just acquired
Share with us in comments, your experience and your discoveries on the subject
See you soon!

