
En SEO, Allow es una directiva que permite gestionar los rastreadores enviados por los motores de búsqueda como Google y Bing. Su función principal es indicar a estos bots que tienen acceso a determinadas URLs, secciones o archivos del sitio web. Por otro lado, tenemos el Disallow que prohíbe el acceso a estos mismos elementos considerados sensibles.
La creación de contenidos y la animación de la página web es sólo una parte del esfuerzo que supone SEO. Varios otros elementos entran en juego cuando se trata de hacer que las páginas de un sitio web aparezcan entre las primeras del SERP (Página de resultados del motor de búsqueda)
De hecho, los sitios web tienen, por ejemplo, un archivo robots.txt que contiene directivas que le permiten gestionar las acciones de los rastreadores en las páginas de su sitio web. Entre estas directivas, tenemos Allow.
Así que :
- ¿Qué significa este término técnico?
- ¿Dónde puedo encontrarlo?
- ¿Cómo se puede utilizar y cuáles son sus beneficios para el SEO?
Siga leyendo este artículo para obtener respuestas claras y precisas a estas preguntas.
Capítulo 1: ¿Qué es la directiva Allow y cuál es su uso en el SEO?
En este capítulo, trataré de :
- Para profundizar un poco más en la definición del término Permitir
- Demuestre dónde se encuentra en una página web;
- Y dar su importancia en el SEO de una página web.
1.1 ¿Qué es la directiva Allow?
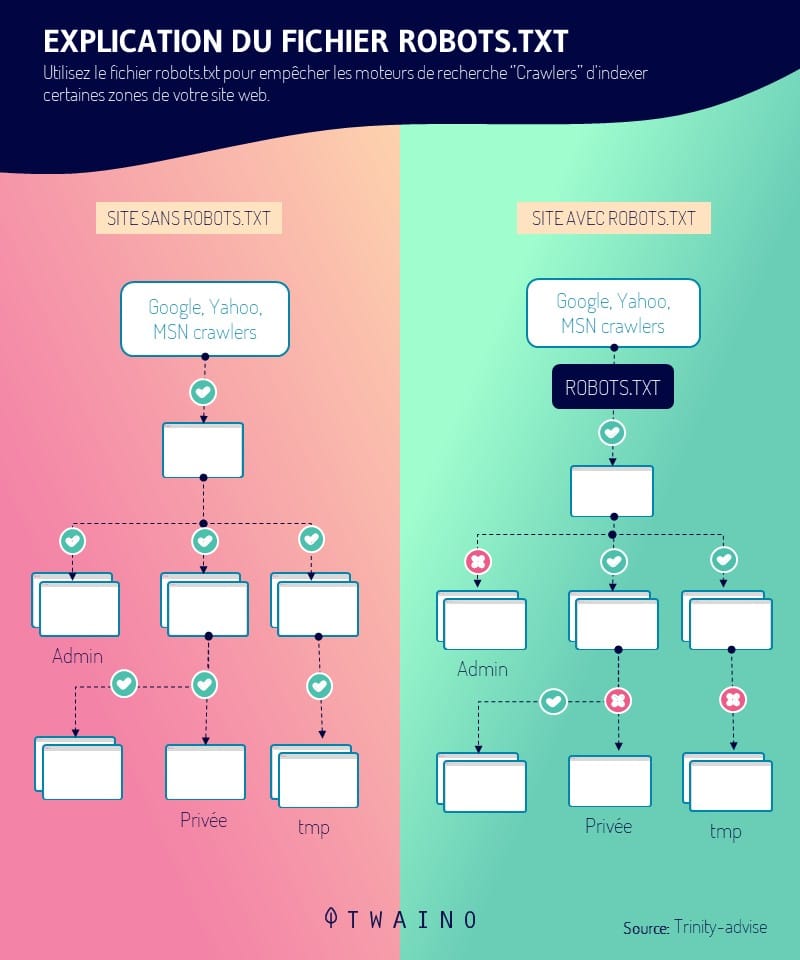
La directiva Allow es una declaración en un archivo robots.txt que le permite especificar y decirle al Crawlers (rastreadores) de los motores de búsqueda qué páginas de un sitio web deben visitar e indexar

A modo de recordatorio, el archivo robots.txt es un archivo de texto que contiene instrucciones para los rastreadores. Contiene varias directivas (Allow, Disallow, Sitemap, etc.) cada una con una o más especificidades
El lenguaje o código utilizado en este archivo robots.txt sólo lo entienden los motores de búsqueda como Google, Bing..
Su misión es autorizar la indexación o no de las páginas de un sitio web o de una tienda en línea durante el rastreo
A diferencia de la directiva Disallow que permiteevitar las arañas de los motores de búsqueda rastreen una página web o todo el directorio, Permitir indica a las arañas qué partes del sitio deben rastrear.
1.2) ¿Dónde se encuentra la directiva Allow?
Permitir se incluye en un archivo robots.txt que se encuentra en el directorio raíz y la URL de los sitios web. Este archivo contiene otras directivas como :
- Disallow ;
- Denegar ;
- Orden
- Etc
Para comprobar la presencia del archivo robots.txt, simplemente escriba el siguiente enlace en la barra de direcciones de su navegador http://www.adressedevotresite.com/robots.txt
1.3. ¿Para qué sirve la directiva Allow?
Veremos a continuación su utilidad en la gestión de sitios web y su relación con el SEO:
1.3.1. La importancia de la directiva Allow en la gestión de sitios web
Como su nombre indica, esta directiva se utiliza para gestionar un sitio web. Permite al webmaster dirigir los rastreadores enviados por los motores de búsqueda a zonas específicas del servidor, páginas que pueden rastrear
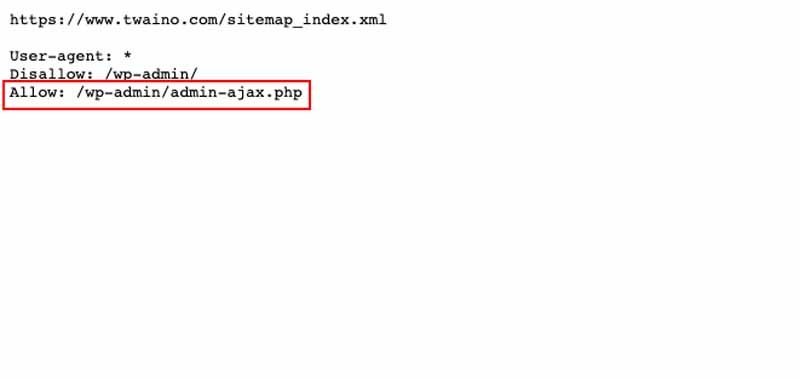
Esto puede hacerse según el nombre del bot, la dirección IP o cualquier otra característica vinculada a cada bot y registrada en las variables de entorno
En resumen, la directiva Allow le permite especificar qué orugas están permitidas para acceder al servidor del sitio web y las páginas que pueden explorar.
1.3.2. La directiva Allow y el SEO
En primer lugar, el archivo robots.txt contribuye a un buen SEO por su misión de dirigir el examen de diferentes partes de un sitio web a través de sus diversas directivas
Con la directiva Allow incluida en este archivo, el Webmaster tiene la capacidad de controlar a los rastreadores y decirles cuáles son las mejores páginas (altamente optimizadas) del sitio web para rastrear
También puede evitar que se rastreen páginas no deseadas, pero esta vez con la directiva disallow.

La función principal de la directiva Allow con la Disallow es gestionar la ruta del crawler indicándole qué páginas de alto valor debe indexar. Estas páginas indexadas por las arañas o crawlers se mostrarán en las SERPs
Capítulo 2: Aplicación de la Directiva de Permisos
Al controlar la aplicación de la directiva Allow, puede controlar y especificar qué arañas deben visitar su sitio y qué áreas del mismo deben ser visitadas.
La directiva Allow se aplica en función de ciertos argumentos o características específicas de los rastreadores web. Se puede aplicar en función de lo siguiente:
- El nombre de dominio ;
- La dirección IP completa o parcial;
- Un par de redes ;
- Una especificación de red CIDR.
2.1. La aplicación de Allow basada en el nombre de dominio
Permitir siempre utiliza «de» como primer argumento
En caso de especificar el primer argumento como «Permitir desde todoses decir, «Permitir todo», le da a todas las arañas acceso para rastrear su sitio web y acceder a todas las páginas de su sitio
La única restricción es cuando el Denegar y Pida las directivas se establecen para evitar que ciertas arañas accedan al servidor.
Además, cuando se establece el primer argumento de la directiva Allow con el nombre del dominionombre de dominio, los rastreadores con nombres que coinciden con la cadena especificada pueden acceder al servidor y rastrear las páginas del sitio.
Ejemplo: Permitir desde twaino.org
Permitir desde .net ejemplo.edu

2.2. La aplicación de Allow basada en la dirección IP
Con ladirección IPla configuración basada en la web, se dará acceso a los rastreadores de la web tras una prueba de reconocimiento doble (búsquedas DNS) en la dirección IP de la araña
En primer lugar, se realizará una primera búsqueda inversa para determinar el nombre del robot asociado a la dirección IP
A continuación, se realizará una segunda búsqueda directamente en el robot para comprobar si el nombre del robot explorador corresponde realmente a la dirección IP original
Así, el robot sólo tendrá acceso al servidor del sitio cuando su nombre coincide con el la cadena especificada
Además, es necesario que las dos búsquedas de direcciones IP inversas deberían dar resultados lógicos y coherentes.
Ejemplo: Permitir desde 10.1.2.3
Permitir desde 192.145.1.124.236.128
2.3. La aplicación de Allow basada en la variable de entorno
Este tercer tipo de argumento utilizado por la directiva Allow da acceso a la exploración de las páginas del sitio sólo cuando reconoce la existencia de información relacionada con la Araña en un mecanismo de almacenamiento de información llamado variable de entorno
Desde un punto de vista práctico, cuando se especifica Permitir «Permitir desde env=var-env«permite el acceso a todos los rastreadores que tengan la variable de entorno «var-env«.
El servidor del sitio le permite especificar muchas variables de entorno con relativa facilidad. Por lo tanto, tiene la posibilidad de utilizar esta directiva para controlar el acceso a su sitio en función de las cabeceras.
Ejemplo:
SetEnvIf User-Agent ^KnockKnock/2\.0 let_me_enter
Orden Denegar,Permitir
Rechazar de todos
Permitir desde env=let_me_in
Capítulo: Otras preguntas formuladas sobre la directiva Allow
3.1 ¿Qué es permitir?
Permitir es un término que significa «permitir». Es una de las directivas que se encuentran en el archivo robots.txt y que indica a los rastreadores a qué páginas pueden acceder. También define los tipos de robots que pueden acceder a una página determinada
3.2. ¿Por qué es importante permitir la gestión y la referenciación de un sitio web?
Su importancia se justifica por el hecho de que le permite tener un control total sobre la administración de su sitio. Es decir, puede dar órdenes a los rastreadores sobre las páginas esenciales que deben explorar. También puede dar acceso a robots específicos.
3.3. ¿Qué es un archivo robots.txt?
El archivo robots.txt es un archivo de texto con un conjunto de directivas para manipular positivamente los robots de los motores de búsqueda sobre cómo rastrear e indexar un sitio web.
3.4. ¿Qué es una dirección IP?
Una dirección IP (con IP significa Protocolo de Internet) es un número único asignado permanente o temporalmente a un dispositivo conectado a una red para identificarlo.
3.5. ¿Qué es un rastreador web?
Un rastreador web, también conocido como araña, spiders o crawlers, es un programa que suelen utilizar Google y Bing para rastrear e indexar automáticamente las páginas web
Estas páginas web después de ser puestas en el índice del motor de búsqueda pueden aparecer en los resultados de este motor de búsqueda.
En resumen
La referenciación natural de un sitio es una tarea a largo plazo. Hay toda una serie de acciones que entran en juego para mejorar el ranking de un sitio y hacer que sus páginas aparezcan entre los primeros resultados de la SERP (Search Engine Result Page)
La directiva Allow es una de las herramientas que debe dominar para controlar la indexación de las páginas de su sitio web.
Espero que esta guía haya proporcionado respuestas claras a sus dudas sobre el término Permitir. Así que, por favor, compártalo si le ha servido de ayuda.
¡Gracias y hasta pronto!

