
The index simply refers to the list of all the web pages on the Internet of which the search engines are aware, and from which they can make a section to answer the queries of Internet users.
The aim of any website owner is to see their pages appear on the SERPs when someone makes a query related to the site’s sector.
Unfortunately, this isn’t always the case, due to the absence of certain pages in the search engine index.
In other words, if Google isn’t aware of your page, it won’t appear in the SERPs at all.
To avoid this, I invite you to read this article to better understand the concept of the search engine index.
Chapter 1: What is the Index?
In this first chapter, we’re going to look at all the elements that can help us understand the background to the term Index.
1.1 What is an Index?
Although we’ve just defined the term above, what Google itself offers as an explanation is worth quoting:
”The Google Index is similar to an index in a library, which lists information about all the books available in the library. However, instead of books, the Google index lists all the web pages that Google knows about. When Google visits your site, it detects new and updated pages and updates the Google index”.
In a nutshell, the Google index is a list of web pages that the search engine has discovered and stored. So when someone uses Google to search for something, indexed pages can be found more easily.

To do this, Google looks at various factors, such as how often the page is updated and which other websites link to it.
It then begins the indexing process in three different stages:
- Discovery: Google discovers URLs by crawling the web and extracting links from newly discovered web pages. These pages can be discovered in a number of ways, for example by following links on other web pages or sitemaps, or by looking at where incoming links come from;
- Crawling: Google has state-of-the-art algorithms that enable it to determine which URLs should be given greater importance. Googlebot then visits pages that meet the defined standards;
- Indexing: Finally, Google examines the content of the page, checking for quality and uniqueness. This is where Google also turns over the pages to see all their different elements such as layout and design; if everything looks good, the page is indexed.
Although this is a simplification, each of these steps actually has sub-steps – these are the most important elements.
Once your web page has passed these stages and is indexed, it can be ranked for relevant queries and shown to users, resulting in significant organic traffic to your website.
Even if the page can’t be found on Google, it can still be indexed by a link on another page.
An exception to this rule would be if you intentionally prevented Google from visiting your page using your robots.txt file, thus preventing it from being crawled.
As Google doesn’t know what your page is about, or whether users will find it relevant, it won’t be able to display it, and as a result, you probably won’t get much traffic on that page.
1.2. does Google index all pages?
In reality, Google doesn’t aim to index every web page on the Internet, and to keep things clear, John Mueller has this to say:
as far as indexing is concerned, we don’t guarantee that we’ll index every page on the website. And especially for larger websites, it’s really normal that we don’t index everything. This could be the case where we only index maybe 1/10 of a website because it’s a very large website. We don’t really know if it’s worth indexing the rest”.
This means that more indexed pages on your website equals better SEO performance, plain and simple.
1.3. What are the index indices?
It’s the source data in Google’s index that ultimately determines the value of different search terms and keywords.
The search engines apply their algorithms to the available data and measure the frequency of different factors under different conditions.
The index includes not only URLs, but also all content, including text, images, videos and everything else in the URL’s HTML code.
The information gathered from this analysis is fed back into Google’s algorithm to provide a new evaluation of the index data, which attempts to understand the content that best matches the user’s intent.
Google search results, or rankings, are then calculated on the basis of this content evaluation.
In this process, here are some important indicators:
1.3.1 Country index
The world’s biggest search engines cover almost every region of the globe, so they dedicate a specific index to each market. For example, Google’s index for the USA (google.com) is completely different from its index for Japan (google.co.jp), and so on.
With country indexes, the search engine can provide more relevant results to users based on their location and language. This creates a reliable source of information that closely matches what users in that country are looking for.
An insufficient approach would be to display results based on a global index integrating data from all markets, but then it would be impossible to meet the specific needs of users in each country.
The search data for each keyword is unique to the national index from which it originates. Without this data, SEO and content marketing decisions cannot be based on actual user behavior.
Although many global companies have leading websites in several countries, as our global SEO rankings reveal, it can be useful to know the different ranking factors that apply in each country.
1.3.2 Local indexes
Like a country index, a local search engine index groups information by region or city.
Users searching for local services or places are primarily interested in results that relate to their proximity.
An example of this would be a search query including “near me” or something similar, such as “the nearest cab rank”; it’s quite obvious that someone living in Paris will expect totally different results from someone living in Bordeaux.

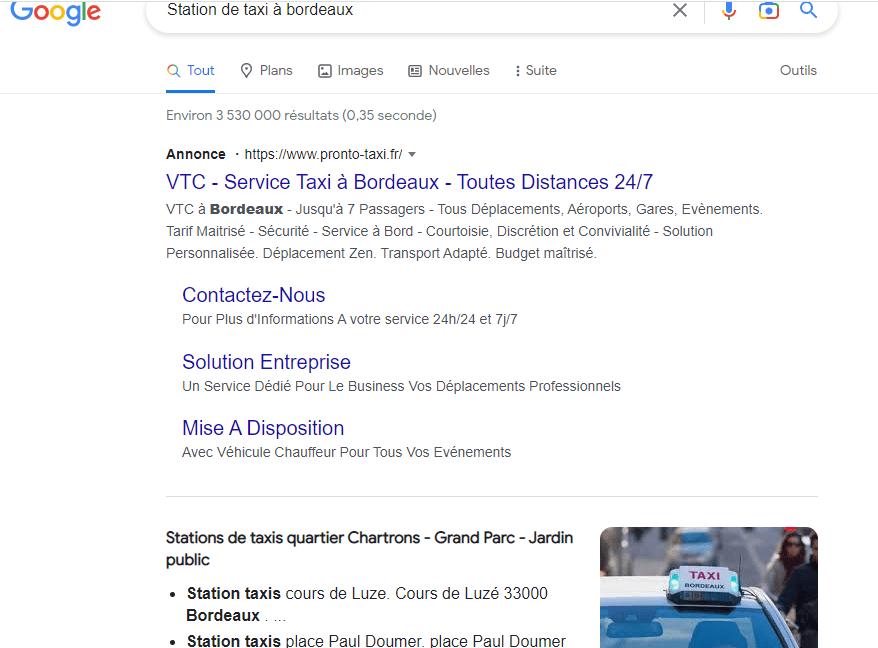
Even if we’re not located in both cities at the same time, when we include the name of each city in a query, we can see that the results proposed by Google are completely different from each other.
1.3.3. Mobile index
Although desktop crawlers are still used by search engines, they are not the only way to gather information.
The decision as to whether mobile results will be displayed separately from desktop results, or whether the latter will be modified for mobile devices, has remained under debate. However, Google webmaster announced in 2016 that there were plans to switch to displaying primarily mobile content.

In this case, the essential information that Google finds will come from the mobile versions of the operated websites. Thus, the desktop index is considered an adjustment or adaptation.
Google’s recent developments in indexing suggest that any webmaster seeking lasting success needs to be aware of how their website appears on both desktop and mobile devices.
While it’s unclear exactly what this new indexing method will mean for websites whose desktop pages contain long-form content and mobile pages short-form content, Google is certainly moving in that direction.
Chapter 2: What are the challenges of indexing?
Search engine indexing today presents several challenges:
2.1. Website page volume
The first challenge for indexing is that the web is growing at an exponential rate, and it’s becoming increasingly difficult to stand out from the crowd.
In March 2021, WorldWideWebSize revealed after analysis that there were over 5 billion pages on the Internet.
The majority of these pages are of no value to Google users, as they are filled with spam, duplicate content and harmful pages containing malware and phishing content.
Fortunately, Google has learned over time to avoid indexing these pages by crawling them as little as possible.
In addition, websites are increasingly focusing on high-quality images and videos, which are often difficult to index.
While this offers new experiences for Google users, it’s a bit difficult for the search engine to use a lot of resources to understand the content of these code- and media-laden pages.
With all that’s going on in the Internet, Google can only become stricter with its content guidelines.
2.2. Index selection
As the Internet grows ever larger, Google can’t index everything. As a result, it has to be selective about the pages it crawls and adds to its database.
Google wants to concentrate on quality pages, so its engineers have developed ways of preventing poor-quality pages from being crawled. As a result, Google may decide not to crawl some of your pages if it judges them to be of poor quality, based on other content you’ve published.
In this scenario, your pages drop out of the indexing pipeline right from the start.
we try to recognize duplicate content at different stages of our pipeline. On the one hand, we try to do this when we examine the content. It’s a bit like after indexing, we see that certain pages are identical, so we can fold them together. But we also do it, essentially, before crawling, where we look at the URLs we see, and based on the information we have from the past, we think, probably these URLs could end up being the same, and then we fold them together”.
Even the data we abstract from Google Search Console confirms that this happens very often. Called ”Discovered, currently unindexed”, this problem is one of the most common we observe and is usually caused by:
- Poor page quality: Google has detected a common pattern and decided not to waste resources crawling low-quality or duplicate content;
- Insufficient crawl budget: Google has too many URLs to crawl and process them all. Faced with this, its budget is limited.
2.3. The constantly evolving search market
Like any other economic market, the search market is constantly evolving. This means that if search engines want to give users the most accurate information for their searches, they have to keep indexing and re-indexing data to be sure of what they’re offering.

To ensure that users can find the most up-to-date information, search engines regularly update their indexes of websites and content.
While a new web page may follow all the SEO and content marketing advice, this doesn’t guarantee that Google will rank it. More often than not, the problem lies in the search engine’s indexing system.
The engine only displays pages that are included in its database in response to queries.
2.4. Technical specifications for inclusion in the index
If a website is not included in the index, it becomes worthless and will never be displayed in search results.
If you want your pages to be crawled by Google and other search engines, it’s essential to understand how these robots work. This means that the pages on your website must be easy for the crawler to access, and that all the content on these pages must be easy to display.
In addition, all URLs on your domain must be included in the corresponding index.
Chapter 3: How can you ensure that Google indexes all your pages?
In this chapter, we’ll look at a few tactics to help search engines access your web pages with ease:
3.1. Check your site’s search engine visibility parameters
First and foremost, you need to check that your entire website is visible to search engines.
If you’re using WordPress as your content management system, you can check your website’s accessibility to search engines by accessing the “Settings” tab on the admin panel of your WordPress site.
Once in the settings, scroll down to the “Search Engine Visibility” option.
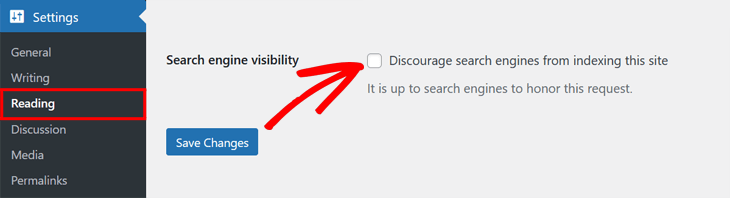
For search engines to be able to index and crawl your website, you need to have this setting’s box checked.
On the other hand, if you’re using a content management system that doesn’t offer this setting, there are several other ways to check your website’s indexability:
3.1.1. Using the ”site” command
A quick way to check how many pages of your website are indexed by Google is to use the search operator ”site:example.com” in Google, replacing ”example” with your domain name.
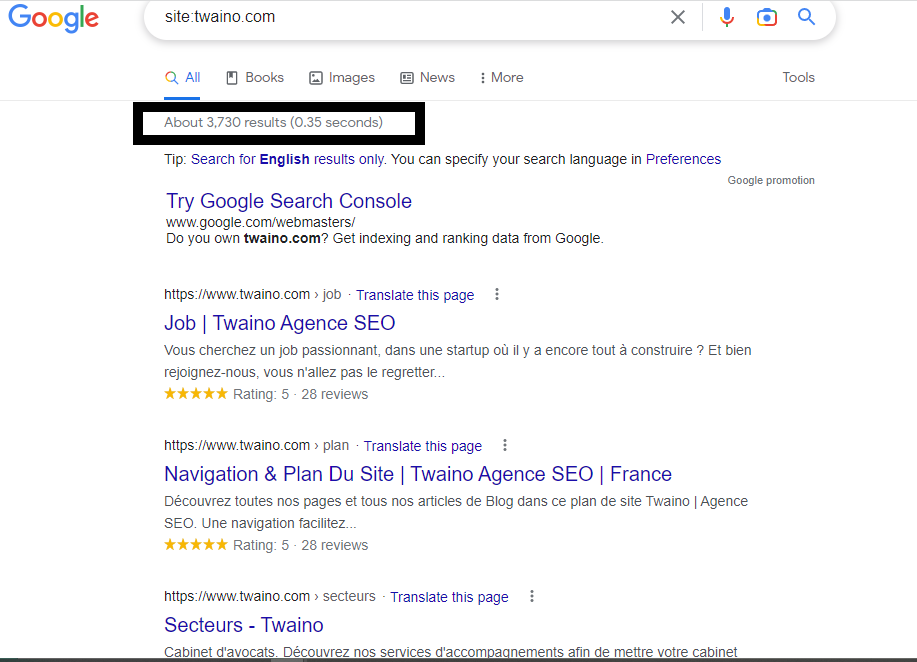
Although the indexing status of a website can be checked using this method, the data may be inaccurate, as it is only an estimate. This method is particularly inadequate when the content of your site changes regularly.
Often, the results will show a different number of indexed pages each time you use this method.
If you don’t find the ”site:domain” command satisfactory enough, you can try using the ”site:URL” command instead. This way, you’ll know whether a specific URL has been indexed or not.
3.1.2. Tools in Google Search Console
Google Search Console provides a comprehensive suite of tools that can prove very useful for your index coverage strategy.
In other words, several Google Search Console features make it easy for you to check your website’s status in the search engines.
3.1.2.1. Index coverage report (page indexing)
This is a report in Google Search Console that gives you an idea of which pages can be easily indexed, as well as the progress status of your URLs.
If there are any issues preventing URL indexing, they will also appear here.
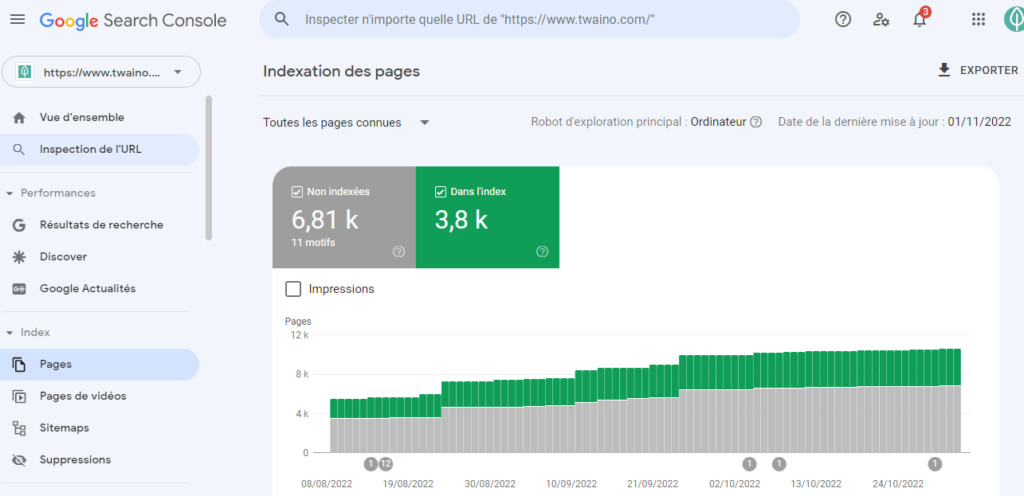
As you can see, the Index Coverage report shows us two categories of url on the website.
- Not indexed: This category includes pages that the search engine is unable to index for a number of reasons. These pages may display errors, such as an HTTP status code of 5xx, a ban directive that is not correctly listed in the robots.txt file, or the use of the noindex tag without appropriate instructions. Google may decide not to index a page for a number of reasons, even if the page was available for crawling;
- Indexed : Pages in this category are generally those that search engines index without any problems. Some of them may have minor problems that you should check, but nothing major prevents them from being indexed.
In the top left-hand corner, you can select the data you wish to display:
- All known pages: These are URLs that the search engine has found in any way;
- All submitted pages: These are pages that the search engine has found in your sitemap;
- Non-submitted pages only: These are pages that are not included in the sitemap, but which the search engine discovered during crawling.
If certain pages appear in “Unsubmitted pages only” and you want Google to index them, add them to your sitemap. If you don’t want Google to index these same pages, Google may find them elsewhere on the Internet, most likely through links.
The report contains a maximum of 1,000 pages per specific problem display. However, there are ways around this problem, for example by creating separate domain properties for different sections of the website.
3.1.2.2. URL inspection tool
The URL inspection tool available in Google Search Console is another excellent way of checking whether the pages on your website are indexed by Google.
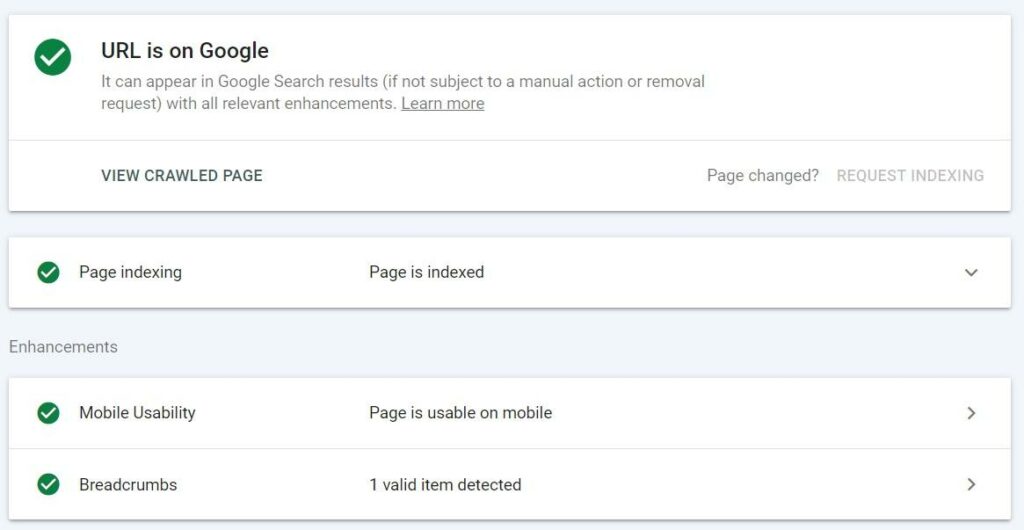
When you run this feature, it presents you with valuable data such as:
- Presence status: The presence status of a URL determines whether it can appear in Google’s search results. In addition, any warnings or errors detected by Google will also be displayed here;
- Show crawled page: This option allows users to see the HTML code and HTTP response that Google received during its last visit to the page;
- Request indexing: This feature allows you to ask Google to re-explore and re-index your URL. Although not explicitly mentioned in Google’s documentation, it is mentioned as a way to submit “just a few URLs”. With this method, you can submit up to 50 URLs per day;
- Enhancements : The “Enhancements” section indicates whether Google has found valid structured data on the page, in addition to mobile usability and AMP details;
- Live URL testing: Live URL testing lets you test URLs in real time to validate changes or fixes.
The URL inspection tool can help you check whether your website is indexed, but this may take some time depending on the number of pages you have. If you want to make a quicker assessment, try sampling some of your pages instead to get an idea of the problems your site is experiencing.
You can improve your website’s ranking by inspecting both URLs that have been excluded from Google’s index and those that should be indexed but aren’t receiving organic traffic.
3.1.2.3. URL Inspection API
The URL Inspection API was Google’s answer in 2022 to people who found the URL Inspection Tool data useful but could only check one URL at a time. Google’s URL Inspection API allows you to collect data for up to 2,000 queries per day for a single Google Search Console property from 2022.
3.2. create a sitemap
A sitemap, as the name suggests, is a map of your website that tells crawlers which pages of your website are accessible and indexable.
In other words, XML sitemaps are created to communicate effectively with these robots.

Their purpose is to ensure that all high-value pages are crawled, and to facilitate the search for new content.
Creating an effective sitemap is crucial to successful indexing.
If you don’t have a sitemap, Google can take up to 24 hours to index your new blog post or website.
When you have a sitemap, however, you can reduce this time significantly, to just a few minutes.
Fortunately, there are several tools available to create a sitemap for your website:
The fastest and most efficient way to create an XML sitemap is to use Screaming Frog’s SEO Spider tool.
For sites with less than 500 pages, this sitemap tool is completely free to download. But if your site contains more than 500 pages, you’ll need to consider purchasing a license.
Google XML Sitemaps is a free plugin for WordPress sites that offers an easy way to generate custom sitemaps, just like the ones you can create with Screaming Frog.
After setting your preferences, you’ll get your sitemap in the form of http://votredomaine.com/sitemap.xml.
3.3. Submit your sitemap to Google Search Console
Submitting your sitemap to Search Console enables Google to find all the pages you wish to index, which is essential to help its robots identify your most important content.
To do this, you’ll go to your Google search Console home page to choose the domain you wish to use.
Once this is done, you can configure your sitemap, using the options in the left-hand sidebar, before submitting it to Google.
Typically, your sitemap URL is in the form of http://yoururl.com/sitemap.xml.
Once your sitemap has been validated, you’ll be able to see how many pages you’ve submitted compared with the number indexed by Google.
In this way, you’ll have complete control over the amount of information about your site that Google has retained.
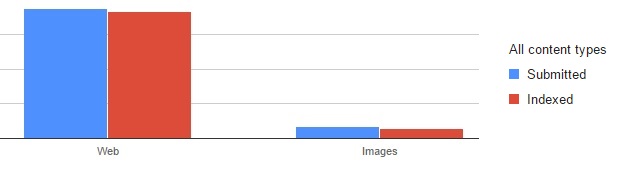
It’s essential to understand that a sitemap shouldn’t be created and then forgotten. As you add pages and modify your site, it evolves, and your sitemap must evolve too. By keeping Google informed of changes to your site, it can crawl and index it more efficiently.
3.4. Create a robots.txt file
The name “robots.txt” may sound technical and complicated, but this file is actually quite easy to understand.
For a search engine to include your website in its results pages, you must first have a robots.txt file that tells the crawler what content to index and what not to include.
This document essentially provides a list of commands that tell the spider where it can and cannot go on your site. Without this file, the spider will simply move on to another website.
Google crawls your website following the instructions defined in your robots.txt file. By default, this allows Google to index all the content on your site.
However, if you have pages or content that you don’t want to appear in search results, you can block them using this file.
In fact, Google itself makes it clear, ”We offer webmaster tools to give site owners precise choices about how Google crawls their site: they can provide detailed instructions on how to treat the pages on their sites, can request a new crawl, or can disable crawling altogether using a file called “robots.txt”.
Especially when you have more pages on your website, the robots.txt file optimizes your website’s indexing by dictating which pages can be indexed and improving control.
Robots.txt files are basic text documents that can be easily created using any plain text editor, such as Notepad (for Windows) or TextEdit for Mac. Don’t use programs like Microsoft Word, as they add extra formatting that will distort your file.
If you’re starting from scratch, creating a robots.txt file is easy, even if you have no previous experience. Once you’ve finished, store it in your root folder as http://votredomaine.com/robots.txt.
However, before starting the process, check your FTP to see if such a file already exists; if so, downloading it and revising it if necessary will be quicker than creating one from scratch.
Google offers a simple guide to the whole process.

Websites are constantly being crawled and indexed by search engines, but you can also speed up this process by using internal links.
By including links in your pages, you make it easier for bots to find all the content on your site.
A well-designed website should be identified by the way the most important web pages are linked together.
Although often overlooked, the structure of your website can actually have a considerable influence on various aspects of your SEO :
3.5. Ensure user experience
If you want users to have a pleasant time on your website, design a clear hierarchy and navigation system. This way, everyone will know where everything is and can find what they’re looking for more easily.
When you don’t have a lot of content on your site, it’s vital to keep the structure simple. While sophisticated mega-menus can be visually appealing, they’re not necessary.
It’s better to use a simple, straightforward layout that quickly shows users where to click to find the information they need, and the same goes for search engines.
- Crawlers
Not only does a well-designed site architecture make it easier for your users to navigate, it also enables web crawlers to access and index your content more efficiently.
By establishing a hierarchy between your pages, you help crawlers understand which pages are most important and how they relate to each other.
Links between your pages are the best way to help crawlers find your new content. All pages should have a few internal links each, to make the crawling process more efficient.
- Content center pages
If your website contains a lot of content, you can create “content center pages” as an effective way for users and search engines to navigate your site more efficiently.
There are many ways of structuring content with numerous content type pages, but the center pages essentially serve as an index for specific topics related to the information on your website as a whole.
This makes it easier for visitors to find the products or services they’re looking for, without having to sift through everything else.
This increases conversion rates and generates more leads and sales from incoming organic traffic
Hub pages typically include :
- Blog content on similar topics;
- Similar products, if you run an e-commerce site;
- Related news content, if you run an editorial site;
- Etc.
Google uses these pages to determine the relevance of individual pages and how they relate to other pages on your site. What’s more, from the user’s point of view, this simplifies the search for additional content related to the page of interest.
Conclusion
To sum up, the search engine index groups together only those web pages that are easily accessible. In addition to accessibility, the index relies on several other factors such as region and page version to display results. And to ensure that your pages meet all these requirements, we’ve provided a few tips in this article that you can put into practice.

