
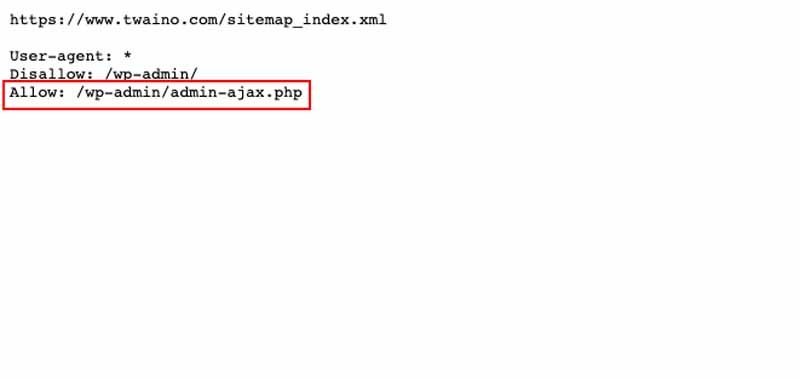
En SEO, Allow est une directive qui permet d’administrer les crawlers (robots d’explorations) envoyés par les moteurs de recherche tels que Google et Bing. Sa fonction principale est d’indiquer à ces bots qu’ils ont accès à des URL, des sections ou des fichiers particuliers du site web. À l’opposé, nous avons le Disallow qui interdit l’accès à ces mêmes éléments jugés sensibles.
La création de contenu et l’animation du site internet ne sont qu’une partie des efforts à fournir dans le SEO. Plusieurs autres éléments entrent en jeu lorsqu’il s’agit de faire apparaître les pages d’un site web parmi les premières des SERP (Search Engine Result Page).
En effet, les sites internet disposent par exemple d’un fichier robots.txt contenant des directives qui vous permet d’administrer les actions des robots explorateurs sur les pages de votre site internet. Parmi ces directives, nous avons Allow.
Alors :
- Que faut-il comprendre par ce terme technique ?
- Où le trouver ?
- Comment l’utiliser et quels sont ses avantages pour le SEO ?
Continuez la lecture de cet article pour avoir des réponses claires et précises à ces questions.
Chapitre 1: Qu’est-ce que la directive Allow et quelle est son utilité dans le SEO ?
Dans ce chapitre, je vais essayer :
- D’approfondir un peu plus la définition du terme Allow ;
- De démontrer où il se trouve sur une page web ;
- Et de donner son importance dans le référencement d’une page web.
1.1. Qu’est-ce que la directive Allow ?
La directive Allow est une instruction contenue dans un fichier robots.txt qui permet de spécifier et d’indiquer aux Crawlers (robots d’exploration) des moteurs de recherche les pages d’un site web à visiter et à indexer.

Pour rappel, le fichier robots.txt est un fichier texte comportant des indications à l’endroit des robots d’exploration. Il contient plusieurs directives (Allow, Disallow, Sitemap, etc.) ayant chacune une ou des spécificités.
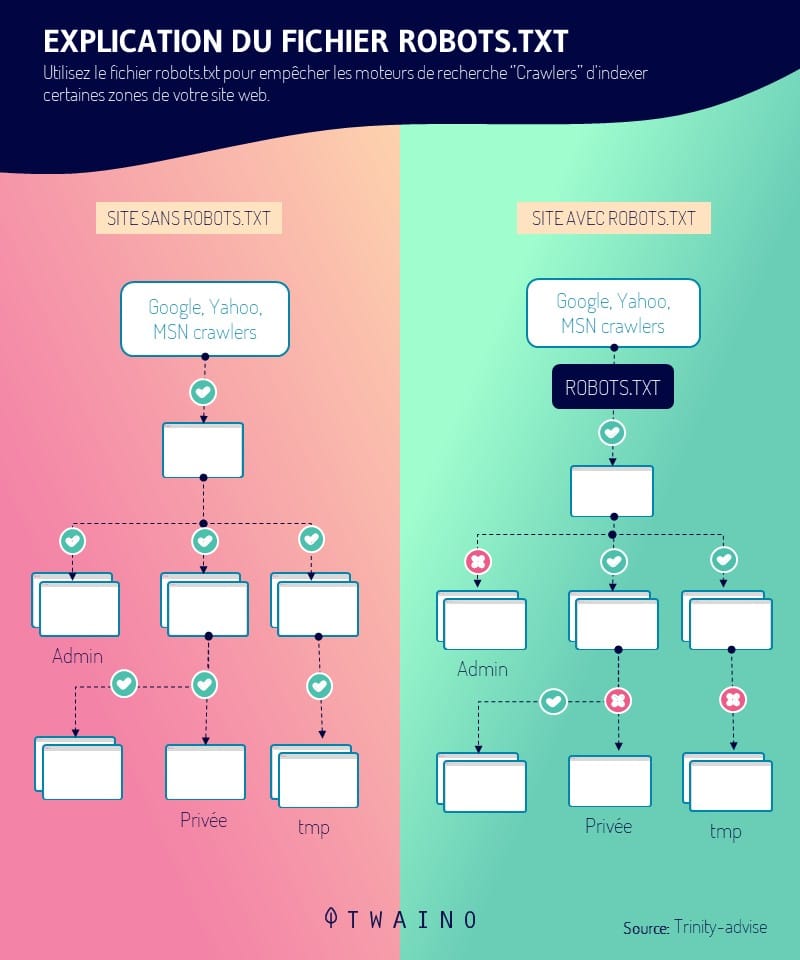
Le langage ou le code utilisé dans ce fichier robots.txt est compris uniquement par les moteurs de recherche tels que Google, Bing…
Sa mission est d’autoriser l’indexation ou non des pages d’un site web ou d’une boutique en ligne lors du Crawl.
Par opposition à la directive Disallow qui permet d’empêcher aux robots des moteurs de recherche l’exploration d’une page web ou le répertoire complet, Allow indique aux Spiders les parties du site à explorer.
1.2. Où se situe la directive Allow ?
Allow est incluse dans un fichier robots.txt qui se retrouve dans le répertoire racine et l’URL des sites internet. Ce fichier comporte plusieurs autres directives comme :
- Disallow ;
- Deny ;
- Order ;
- Etc.
Pour vérifier la présence du fichier robots.txt, il suffit de taper dans la barre d’adresse de votre navigateur le lien suivant : http://www.adressedevotresite.com/robots.txt
1.3. Quelle est l’utilité de la directive Allow ?
Nous allons voir ci-dessous son utilité dans la gestion de site web et son rapport avec le SEO :
1.3.1. L’importance de la directive Allow dans la gestion du site web
Comme son nom l’indique, cette directive permet d’administrer un site web. Elle permet au webmaster de diriger les robots d’exploration envoyés par les moteurs de recherche vers des zones spécifiques du serveur, des pages qu’ils peuvent explorer lors du crawl.
Ce travail peut se faire en fonction du nom du Bot, de l’adresse IP ou toutes autres caractéristiques liées à chaque robot et enregistrées dans les variables d’environnement.
En résumé, la directive Allow permet d’indiquer de façon précise les Crawlers qui sont autorisés à accéder au serveur du site web et les pages qu’ils peuvent explorer.
1.3.2. La directive Allow et le SEO
D’abord, le fichier robots.txt contribue au bon référencement du site en raison de sa mission qui consiste à diriger l’examen des différentes parties d’un site web par l’intermédiaire de ses différentes directives.
Avec la directive Allow (Autoriser) incluse dans ce fichier, le Webmaster a la capacité de contrôler les robots d’exploration et de leur indiquer les meilleures pages (très bien optimisées) du site web à explorer.
Il peut aussi empêcher l’exploration des pages indésirables, mais cette fois-ci avec la directive disallow (Refuser).

La fonction principale de la directive Allow avec le Disallow est donc d’administrer le parcours des robots en leur indiquant les pages à fortes valeurs ajoutées à indexer. Ces pages indexées par les spiders ou robots d’explorations seront affichées dans les SERP.
Chapitre 2 : L’application de la directive Allow
Avec la maîtrise de l’application de la directive Allow, vous pouvez contrôler et spécifier quels robots explorateurs doivent visiter votre site ainsi que les endroits du site susceptibles d’être visités.
La directive Allow s’applique en fonction de certains arguments ou caractéristiques propres aux robots d’exploration. Elle peut être appliquée en fonction des éléments suivants :
- Le nom de domaine ;
- L’adresse IP complète ou partielle ;
- Une paire de réseau ;
- Une spécification de réseau CIDR.
2.1. L’application de Allow en fonction du nom de domaine
Allow utilise toujours “from” comme premier argument.
Dans le cas où vous spécifiez le premier argument sur “Allow from all », c’est-à-dire ‘’Autoriser tout’’, vous donnez accès à tous les spiders d’explorer votre site internet et d’accéder à toutes les pages de votre site.
La seule restriction est lorsque les directives Deny et Order sont configurées pour empêcher l’accès au serveur à certains robots explorateurs.
Par ailleurs, lorsque vous configurez le premier argument de la directive Allow par le nom de domaine, les robots explorateurs dont les noms se rapportent à la chaîne spécifiée peuvent accéder au serveur et explorer les pages du site.
Exemple : Allow from twaino.org
Allow from.net exemple.edu

2.2. L’application de Allow en fonction de l’adresse IP
Avec la configuration en fonction de l’adresse IP, l’accès sera donné aux robots explorateurs suite à un double test de reconnaissance (recherches DNS) sur l’adresse IP du spider.
D’abord, une première recherche inverse sera faite pour déterminer le nom du robot associé à l’adresse IP.
Ensuite, une deuxième portera directement sur le robot afin de vérifier si le nom du robot explorateur correspond véritablement à l’adresse IP originale.
Ainsi, le robot n’aura accès au serveur du site que lorsque son nom correspond à la chaîne spécifiée.
Aussi, il faudrait que les deux recherches inversées portant sur l’adresse IP donnent des résultats logiques et consistants.
Exemple : Allow from 10.1.2.3
Allow from 192.145.1.124.236.128
2.3. L’application de Allow en fonction de la variable d’environnement
Ce troisième type d’argument utilisé par la directive Allow donne accès à l’exploration des pages du site que lorsqu’elle reconnaît l’existence des informations liées au Spider dans un mécanisme de stockage d’information appelé : variable d’environnement.
Du point de vue pratique, lorsque Allow est spécifié “Allow from env=var-env”, elle autorise l’accès à tous les robots explorateurs qui disposent de la variable d’environnement “var-env”.
Le serveur du site donne la possibilité de spécifier beaucoup de variables d’environnement avec une certaine facilité. Vous avez donc la capacité de vous servir de cette directive pour contrôler l’accès de votre site en fonction des en-têtes.
Exemple :
SetEnvIf User-Agent ^KnockKnock/2\.0 laisse_moi_entrer
<Directory /docroot>
Order Deny,Allow
Deny from all
Allow from env=laisse_moi_entrer
</Directory>
Chapitre : Autres questions posées sur la directive Allow
3.1. Qu’est-ce que Allow ?
Allow est un terme anglais qui signifie Autoriser. Il fait partir des directives se trouvant dans le fichier robots.txt et indique aux robots d’exploration les pages auxquelles ils ont accès. Il permet aussi de définir les types de robots qui peuvent accéder à une page donnée.
3.2. Pourquoi allow est important pour la gestion et le référencement d’un site web ?
Son importance se justifie par le fait qu’il vous permet d’avoir le contrôle total sur l’administration de votre site. C’est-à-dire, vous pouvez donner des ordres aux crawlers sur les pages indispensables qu’ils doivent explorer. Vous pouvez aussi donner l’accès à des robots spécifiques.
3.3. Qu’est-ce qu’un fichier robots.txt ?
Le fichier robots.txt est un fichier texte comportant un ensemble de directives permettant de manipuler positivement les robots des moteurs sur la façon d’explorer et d’indexer un site web.
3.4. Qu’est-ce qu’une adresse IP ?
Une adresse IP (avec IP qui signifie Internet Protocol) est un numéro unique attribué de façon permanente ou provisoire à un périphérique (ou appareil) connecté à un réseau afin de l’identifier.
3.5. Qu’est-ce qu’un robot d’exploration ?
Un robot d’exploration Web également appelé araignée, spiders ou crawlers, est un programme qui est généralement utilisé par Google et Bing pour explorer et indexer automatiquement les pages web.
Ces pages web après être mis dans l’index du moteur de recherche peuvent désormais apparaître dans les résultats de ce moteur de recherche.
En résumé
Le référencement naturel d’un site est un travail à longue haleine. Il existe une panoplie d’actions qui rentre en composition pour permettre de mieux référencer un site et de faire apparaître ses pages parmi les premiers résultats des SERP (Search Engine Result Page).
La directive Allow est l’un des outils que vous devez maîtriser pour pouvoir bien contrôler l’indexation des pages de votre site internet.
J’espère que ce guide a apporté des réponses claires à vos doutes sur le terme Allow. N’hésitez donc pas à le partager s’il vous a aidé.
Merci et à bientôt !


