
Le Budget crawl est défini comme le nombre limite de pages que Google s’est fixé d’explorer sur un site web pour son référencement. Lors de l’exploration, le moteur de recherche essaye de contrôler ses tentatives pour ne pas surcharger le serveur du site, mais tout en prenant soin de ne pas ignorer les pages importantes. Pour retrouver le juste équilibre, Google va donc attribuer un Budget crawl différent à chaque site web sur la base de quelques critères comme : La réactivité du serveur, la taille du site, la qualité des contenus et la fréquence des mises à jour.
Le Web est en pleine extension, le SEO également. Rien qu’en 2019, plus de 4,4 millions d’articles de blog ont été publiés sur le net chaque jour.
Pendant que les internautes se plaisent à consulter ces contenus, les moteurs de recherche sont confrontés à un défi majeur : Comment organiser les ressources pour explorer uniquement les pages pertinentes et ignorer les liens spammeurs ou de mauvaise qualité.
D’où la notion de budget crawl.
- Qu’est-ce que c’est concrètement ?
- Quelle est son importance pour un site web ?
- Quels sont les facteurs qui l’affectent ?
- Comment l’optimiser pour un site Web ?
- Et comment le surveiller ?
Voilà autant de questions auxquelles nous donnerons des réponses claires et concises tout au long de ce mini-guide.
On y va donc !
Chapitre 1 : Budget crawl – Définitions et importance SEO
Pour bien développer ce chapitre, nous allons aborder la définition du budget crawl sous deux angles :
- Une définition vue du côté des experts SEO ;
- Et ce que Google entend réellement par ce terme.
1.1. Qu’est-ce que le budget crawl ?
Le budget crawl (ou budget d’exploration ou d’indexation) n’est pas un terme officiel donné par Google.
Il tire plutôt son origine de l’industrie du référencement où il est employé par les experts SEO comme un terme générique pour désigner les ressources allouées par Google pour explorer un site et indexer ses pages.

Pour faire simple, le budget crawl d’un site web désigne le nombre de pages que Google prévoit explorer sur le site dans un délai donné.
C’est un nombre prédéterminé d’URLs que le moteur de recherche ordonne à son robot d’indexation, GoogleBot, de considérer lors de son passage sur le site.

Dès que la limite du budget de crawl est atteinte, GoogleBot cesse d’explorer le site, le reste des pages non indexées est automatiquement ignoré et le robot quitte le site.
Ce nombre de pages à indexer peut varier d’un site à un autre parce que justement tous les sites ne possèdent pas la même performance ni la même autorité. Un budget crawl fixe pour tous les sites web pourrait s’avérer trop élevé pour un site et trop peu pour un autre.
Le moteur de recherche a donc décidé d’utiliser un certain nombre de critères avant de fixer le temps que mettra son robot d’indexation sur chaque site ainsi que le nombre de pages à crawler.
Pour ce qui est de ces critères, il n’existe pas une liste exhaustive, comme d’ailleurs pour beaucoup de choses en rapport avec l’algorithme de Google.
Néanmoins, voici quelques-uns de ces critères connus de tous :
- La performance du site : Un site web bien optimisé et qui a une vitesse de chargement rapide obtiendra probablement un budget crawl plus élevé qu’un site qui tarde à se charger.
- La taille du site : Plus un site contient de contenus, plus son budget sera important.
- La fréquence des mises à jour : Un site qui publie assez de contenus de qualité et qui met régulièrement à jour ses pages se verra attribuer un budget crawl considérable.
- Les liens sur le site : Plus un site contient de liens, plus son budget crawl sera élevé et mieux ses pages seront indexées.

Idéalement, le budget crawl doit couvrir toutes les pages d’un site, mais malheureusement, ce n’est pas toujours le cas. C’est pourquoi il est important d’optimiser les critères ci-dessus cités pour maximiser vos chances d’obtenir un budget crawl important.
Il faut dire que jusque-là, la définition de ce terme a été abordée d’un point de vue d’un propriétaire de site ou d’un expert SEO web qui a la charge de travailler le référencement d’un site web.
Mais, quand la question de savoir « qu’est-ce que le budget crawl » a été adressée à Gary Illyes, analyste chez Google, sa réponse était beaucoup plus nuancée.
1.2. Qu’est-ce que Google entend réellement par budget crawl ?
En 2017, Gary Illyes s’est intéressé à la question en détaillant comment Google conçoit le budget crawl. Dans sa réponse, on pourrait distinguer 3 grandes parties importantes :
- La notion de taux d’exploration ;
- La demande d’exploration ;
- Et quelques autres facteurs.
1.2.1. Le taux d’exploration
Lors de son exploration, Google craint de submerger chaque site crawlé et de faire sauter son serveur. Cela n’étonne guère, car nous savons que le moteur de recherche s’est toujours montré protecteur et prône une bonne expérience utilisateur sur les sites web.
Les propos de Gary Illyes viennent confirmer tout ceci encore une fois :
« Googlebot est conçu pour être un bon citoyen du Web. L’exploration est sa principale priorité tout en s’assurant qu’elle ne dégrade pas l’expérience des utilisateurs visitant le site. Nous appelons cela la ‘’limite du taux d’exploration’’, qui limite le taux de récupération maximal pour un site donné ».
Donc si GoogleBot constate des signes sur un site qui indiquent que son passage fréquent pourrait affecter les performances du site, alors le robot d’indexation ralentit sa durée de crawl ainsi que sa fréquence de visite.
Du coup, dans certains cas, certaines pages d’un site web peuvent se retrouver non indexées par GoogleBot.
À l’inverse, si le robot d’indexation reçoit des signes encourageants tels que des réponses rapides venant du serveur, cela facilite le travail et GoogleBot peut décider d’augmenter la durée ainsi que la fréquence de ses visites.
1.2.2. La demande d’exploration
En ce qui concerne la demande d’exploration, Gary Illyes explique :
« Même si la limite de vitesse d’exploration n’est pas atteinte, s’il n’y a pas de demande d’indexation, il y aura une faible activité de Googlebot ».
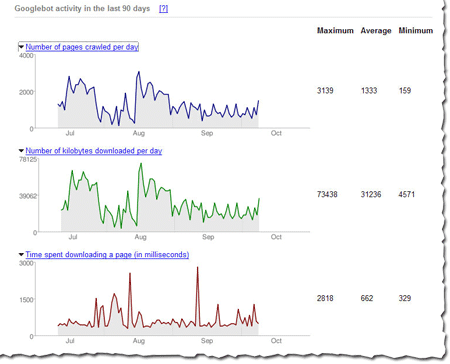
Source : Tech Journey
En clair, GoogleBot se base sur la demande d’exploration d’un site pour décider si le site vaut la peine d’être revisité.
Cette demande est influencée par deux facteurs :
- La popularité des URLs : Plus une page est populaire, plus elle a tendance à être explorée par les robots d’indexation.
- Les URLs obsolètes : Google essaie aussi de ne pas avoir des URLs obsolètes dans son index. Donc plus un site contient d’anciennes URLs, moins ses pages seront indexées par GoogleBot.
L’intention de Google est d’indexer les contenus récents ou régulièrement mis à jour des sites populaires et délaisser ceux qui sont obsolètes. C’est sa façon de maintenir son index toujours à jour avec de récents contenus pour ses utilisateurs.
Les autres facteurs regroupent tout ce qui pourrait améliorer la qualité des contenus d’un site ainsi que sa structure. C’est un aspect important sur lequel Gary Illyes a voulu mettre l’accent.
D’ailleurs, il recommande aux webmasters d’éviter certaines pratiques telles que :
- La création de contenus de mauvaise qualité ;
- La mise en place de certains style de navigation à facettes ;
- Les contenus dupliqués ;
- Etc.

Nous reviendrons sur ces facteurs plus en détail dans un chapitre ultérieur. Pour Gary Illyes, en utilisant de telles pratiques sur votre site, vous gaspillez en quelque sorte votre budget crawl.
Voici ses termes :
« Le gaspillage des ressources du serveur sur des pages comme celles-ci drainera l’activité d’exploration des pages qui ont réellement de la valeur, ce qui peut retarder considérablement la découverte d’un contenu de qualité sur un site ».
Pour mieux comprendre là où Gary veut en venir, admettons par exemple que vous disposez d’une boutique e-commerce populaire spécialisée dans la vente des consoles de jeux vidéo ainsi que de tous les accessoires.
Vous décidez de créer un espace sur le site où vos utilisateurs peuvent partager les expériences qu’ils ont vécues avec vos produits, une sorte de vaste forum très actif. Qu’est-ce qui va se passer à votre avis ?
Eh bien, à cause de ce forum, des millions d’URLs de faible valeur s’ajouteront à votre profil de liens. Conséquence : Ces Urls consommeront inutilement une bonne partie du budget crawl que Google vous a alloué. Du coup, des pages qui représentent réellement de la valeur pour vous peuvent ne pas être indexées.
À présent, vous avez une idée plutôt claire de ce qu’est le budget crawl, mais concrètement quelle est son importance pour un site web ?
Chapitre 2 : L’importance du budget crawl pour le référencement naturel
Un budget d’exploration optimum représente une grande importance pour les sites web puisqu’il permet d’indexer rapidement les pages importantes.
Comme l’a souligné Gary Illyes, un gaspillage de votre budget crawl empêchera Google d’analyser efficacement votre site. Le robot d’indexation pourrait passer plus de temps sur des pages non importantes au détriment de celles pour lesquelles vous désirez vraiment être classé.
Ce qui réduirait votre potentiel de référencement puisque chaque page non indexée ne sera pas présente dans les résultats de recherche Google. Cette page perdra alors toute probabilité d’être consultée par les internautes depuis une SERP.
Imaginez-vous produire un contenu intéressant avec de superbes visuels très illustratifs. Puis vous allez encore plus loin en optimisant les balises Title, Alt, Hn et pleins d’autres facteurs, exactement comme le ferait un expert SEO averti.
Mais si au final, vous ignorez l’optimisation du budget d’exploration, je crains malheureusement que les bots d’indexation de Google n’atteignent pas ce contenu de qualité et les internautes non plus. Ce qui serait bien dommage vu tous les efforts de référencement qui ont été fournis.
Cependant, il faut souligner que l’optimisation du budget crawl n’est particulièrement importante que pour les sites web de grande taille.
John Mueller, un autre analyste Google l’a mentionné dans un tweet en ces termes :
« La plupart des sites n’ont jamais besoin de s’inquiéter à ce sujet. C’est un sujet intéressant, et si vous explorez le Web ou exécutez un site de plusieurs milliards d’URL, c’est important, mais moins pour le propriétaire de site moyen. »
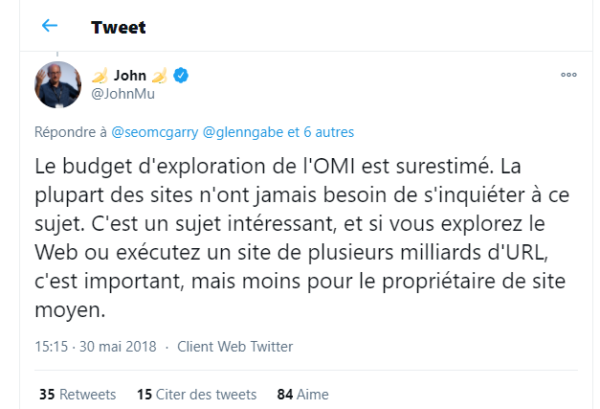
Comme vous pouvez le constater, le budget crawl concerne les sites web de grande envergure avec des milliards d’URLs comme les célèbres plateformes de commerce en ligne par exemple.
Ces sites peuvent vraiment observer une baisse de leur trafic si leur budget crawl n’est pas bien optimisé. Pour ce qui est des autres sites, Google reste moins alarmiste et rassure qu’ils ne devraient pas trop s’inquiéter des problèmes liés au taux d’exploration.
Si vous êtes un petit site local ou que vous venez de créer fraîchement votre site web, voilà une nouvelle qui fait pousser un ouf de soulagement.
Pourtant, vous ne perdez rien à vouloir optimiser votre budget crawl surtout si vous envisagez une extension de votre site à l’avenir.
Bien au contraire, une bonne partie des méthodes utilisées pour optimiser le taux d’exploration se retrouvent également dans les méthodes utilisées pour optimiser le classement d’un site sur les pages Google.
En gros, lorsqu’une entreprise essaye d’améliorer le budget crawl de son site, elle améliore également sa position sur Google.
Voici une liste de quelques avantages SEO dont bénéficie un site en web optimisant son budget crawl, même s’il ne présente aucun problème dans ce domaine :
- Amener GoogleBot a exploré que les pages importantes du site ;
- Avoir un plan de site bien structuré ;
- Réduire les erreurs et les chaînes de redirections trop longues ;
- Améliorer les performances du site ;
- Mise à jour des contenus du site ;
- Etc.
Avec tous ces avantages, il ne fait aucun doute que le budget crawl est d’une grande importance pour un site web.
Mais pour réussir son optimisation, je tiens à vous présenter quelques facteurs négatifs auxquels vous devez faire attention avant de commencer.
Chapitre 3 : Les facteurs qui affectent le budget crawl
Voici quelques facteurs qui peuvent affecter négativement le budget crawl d’un site :
3.1. La navigation à facettes
Il s’agit d’une forme de navigation qu’on retrouve souvent sur les sites de boutique en ligne. La navigation à facettes permet à l’utilisateur de choisir un produit puis d’avoir sur la page d’autres filtres au choix du même produit.
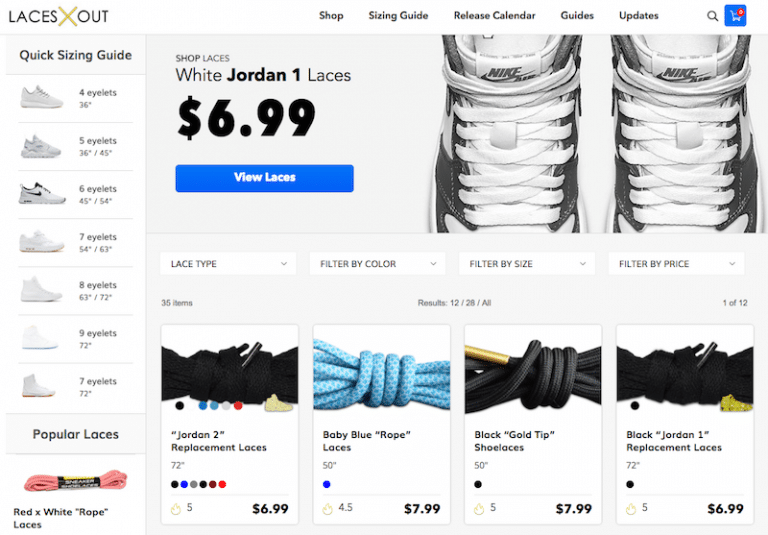
Il peut s’agir d’un produit disponible en plusieurs couleurs ou tailles différentes. Le fait est que cette façon d’organiser les résultats oblige à ajouter des URLs à la page.
Et chaque nouvelle URL ajoutée affiche juste un extrait de sa page originale et non un nouveau contenu. Ce qui représente un gaspillage du budget crawl pour le site.
3.2. Les URLs avec des identifiants de session
La technique de création des identifiants de session dans les URLs ne devrait plus être utilisée, car à chaque nouvelle connexion le système génère automatiquement une nouvelle adresse URL. Ce qui crée une quantité massive d’URLs sur une même page.
Source : Pole Position Marketing
3.3. Les contenus dupliqués
S’il existe plusieurs contenus identiques sur un site, Googlebot peut explorer toutes les pages concernées sans pour autant tomber sur un nouveau contenu.
Les ressources utilisées par le moteur de recherche pour analyser toutes ces pages identiques pouvaient être utilisées pour explorer des URLs avec des contenus pertinents et différents.
3.4. Les pages d’erreur logicielles
Contrairement aux erreurs 404, ces erreurs renvoient bel et bien vers une page fonctionnelle, mais pas celle souhaitée. N’arrivant pas à avoir accès au contenu réel de la page, le serveur renvoie un code d’état 200.
3.5. Les pages piratées
Google s’assure toujours de fournir les meilleurs résultats à ses utilisateurs, ce qui exclut bien entendu les pages piratées. Du coup si le moteur de recherche repère de telles pages sur un site, l’indexation est arrêtée pour empêcher que ces pages finissent dans les résultats de recherche.

3.6. Les espaces infinis
Il existe des espaces infinis qu’on peut retrouver sur un site. Prenons le cas d’un calendrier où le bouton « mois suivant » est programmé pour renvoyer effectivement vers le mois prochain.
Lors de l’exploration, Googlebot pourrait tomber dans une sorte de boucle infinie et vider le budget crawl du site en recherchant constamment le « mois prochain ».

Chaque fois qu’un utilisateur clique sur la flèche de droite, c’est une nouvelle URL qui est créée sur le site, ce qui fait un nombre astronomique de liens sur la seule page.
3.7. Les contenus spammeurs ou de mauvaise qualité
Google essaye d’avoir dans son index que des contenus de qualité qui apportent une réelle valeur ajoutée aux internautes.
Donc, si le moteur de recherche détecte des contenus de mauvaise qualité sur un site, il lui accorde très peu de valeur.
3.8. Les chaînes de redirection
Lorsque pour une raison ou une autre, vous créez des chaînes de redirections, Googlebot doit parcourir toutes les URLs intermédiaires avant d’atteindre le contenu réel.
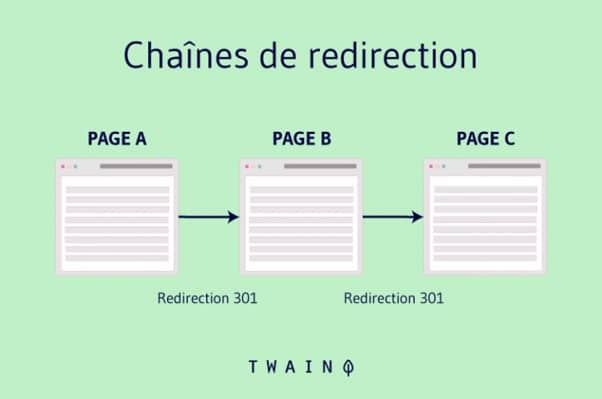
Le robot n’arrive pas encore à faire la différence, il traite alors chaque redirection comme une page à part entière, ce qui vide inutilement le budget crawl alloué au site.
3.9. Le cache Buster
Parfois, des fichiers tels que le fichier CSS peuvent être renommés comme ceci : style.css?8577484. Le hic avec cette façon de nommage est que le signe “?” est généré automatiquement à chaque fois que le fichier est sollicité.
L’idée est d’empêcher les navigateurs des utilisateurs de stocker en cache le fichier. Cette technique génère aussi une quantité massive d’URLs que Google va traiter individuellement. Ce qui affecte le budget crawl.

3.10. Les redirections manquantes
Pour ne pas perdre une partie de son audience, un site peut décider de rediriger sa version non-www vers une version www exactement comme twaino.com vers www.twaino.com ou vice versa.
Il peut également vouloir migrer du protocole HTTP vers le HTTPS. Cependant, si ces deux types de redirections générales ne sont pas correctement configurées, remarquez que Google pourrait explorer 2 ou 4 URLs pour le même site :
http://www.monsite.com
https://www.monsite.com
http://monsite.com
https://monsite.com
3.11. Les mauvaises paginations
Lorsque la pagination est composée juste de boutons qui permettent de naviguer dans les deux sens, sans aucune numérotation, Google a besoin d’explorer plusieurs pages dans ce sens avant de comprendre qu’il s’agit d’une pagination.
Le style de pagination qui est recommandé et qui ne gaspille pas le budget crawl est celui qui mentionne explicitement le numéro de chaque page.

Avec ce style de pagination, Googlebot peut naviguer facilement de la première à la dernière page pour se faire une idée des pages importantes à indexer.
Si vous détectez un ou plusieurs des facteurs cités jusqu’ici, il est important d’optimiser votre budget crawl pour aider Googlebot à indexer les pages les plus importantes pour vous.
Mais comment l’optimiser ?
Chapitre 4 : Comment optimiser le budget crawl ?
À présent que les bases ont été établies, nous pouvons commencer l’optimisation du budget crawl proprement dite.
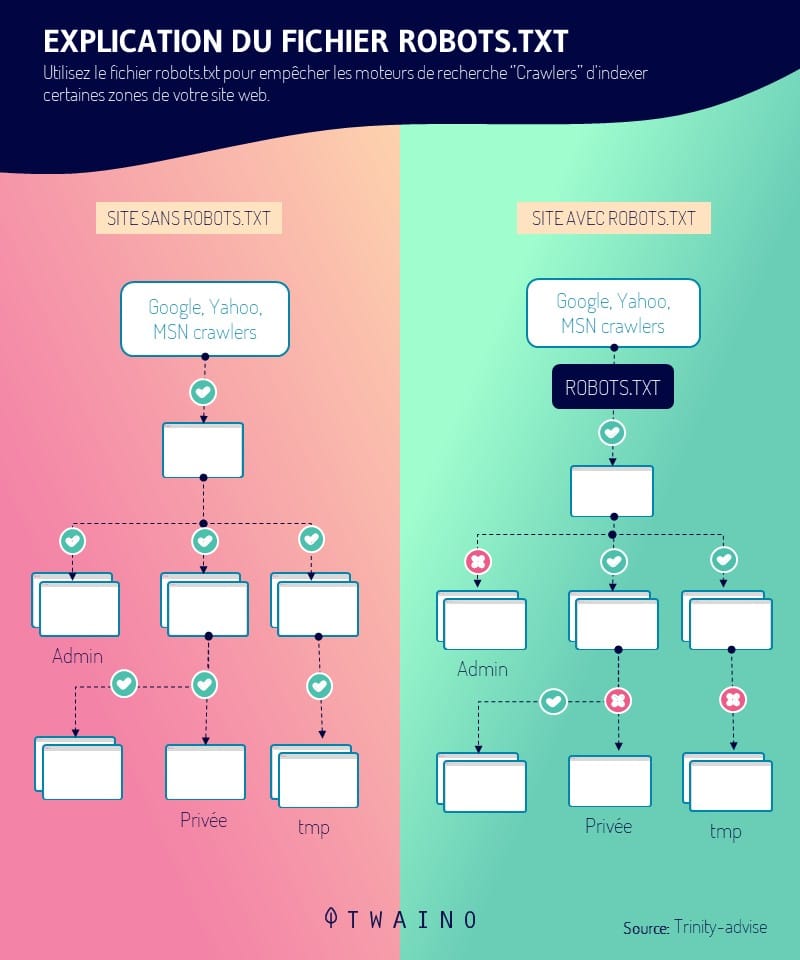
4.1. Autorisez l’exploration de vos pages importantes dans le fichier Robots.Txt
Cette première étape de l’optimisation du budget crawl est probablement la plus importante de toutes.
Vous disposez de deux façons d’utiliser votre fichier robots.txt, soit directement à la main, soit à l’aide d’un outil d’audit SEO.
Si vous n’êtes pas un féru de la programmation, l’option de l’outil reste probablement la plus facile et la plus efficace.
Prenez un outil de votre choix, puis ajoutez le fichier robots.txt. En seulement quelques secondes, vous pouvez décider d’autoriser ou d’interdire l’exploration de n’importe quelle page de votre site.
Découvrez comment le faire dans ce guide entièrement consacré au fichier robots.txt.
4.2. Évitez au mieux les chaînes de redirection
On ne peut pas s’interdire définitivement de recourir aux chaînes de redirection parce que dans certaines circonstances, c’est une approche qui peut être utile. Toutefois, l’idéal serait d’avoir une seule redirection sur un site web.
Mais, il faut reconnaître que c’est presque impossible pour les sites de grande taille. À un moment ou à un autre, ils se voient contraints d’utiliser les redirections 301 et 302.

Cependant, configurer des redirections à tout va sur le site nuit gravement au budget crawl quitte à empêcher Googlebot d’explorer les pages pour lesquelles vous souhaitez être référencé.
Contentez-vous juste de quelques redirections, une ou deux et de préférence de courtes chaînes.
4.3. Recourez au code HTML autant que possible
Le robot d’exploration de Google s’est beaucoup amélioré dans la compréhension des contenus en Javascript, mais aussi Flash et XML.
Mais les autres moteurs de recherche ne peuvent pas en dire autant. Donc pour permettre à tous les moteurs de recherche d’explorer pleinement vos pages, il serait plus judicieux d’utiliser le HTML qui est un langage de base, accessible à tous les moteurs de recherche.
Ainsi, vous augmentez les chances à vos pages d’être explorées par tous les moteurs de recherche.
4.4. Corrigez les erreurs HTTP au risque de perdre inutilement votre budget crawl
Si vous ne le saviez pas, les erreurs 404 et 410 rongent littéralement votre budget d’exploration. Pire encore, elles dégradent votre expérience utilisateur.
Imaginez la déception d’un internaute qui s’empresse de consulter un produit que vous vendez ou un contenu que vous avez rédigé et qui se retrouve finalement sur une page blanche, sans aucune autre alternative.
C’est pourquoi il est important de corriger les erreurs HTTP pour la santé de votre site, mais aussi pour la satisfaction de vos visiteurs.
Tout comme pour les erreurs de redirection, il serait plus pratique d’utiliser un outil dédié pour repérer ces erreurs et les réparer si vous n’êtes pas très épris de la programmation.
Vous pouvez utiliser des outils comme SE Ranking, Ahrefs, Screaming Frog… pour effectuer un audit SEO de votre site.
4.5. Bien paramétrer vos URLs
Si vous paramétrez des URLs différentes pour accéder à une même page, Google ne le comprendra pas de la sorte. Pour le moteur de recherche, chaque page est identifiable par une et une seule adresse URL.
Et donc Googlebot indexera distinctement chaque URL, qu’importe si elles sont plusieurs à rediriger vers un même contenu. Ce qui constitue un gaspillage du budget crawl.
Si vous avez une telle situation sur votre site, vous devez le notifier à Google.
C’est une tâche qui présente un double avantage, d’une part votre budget d’exploration est économisé et d’autre part vous n’avez plus à craindre une sanction de Google pour vos contenus dupliqués.
Retrouvez comment bien gérer vos contenus en double en consultant cet article qui montre en détail la procédure à suivre.
4.6. Gardez votre plan de site toujours à jour
Il est important de mettre à jour votre plan de site XML. Cela permet aux robots d’indexation de comprendre la structure de votre site, ce qui facilite son exploration.
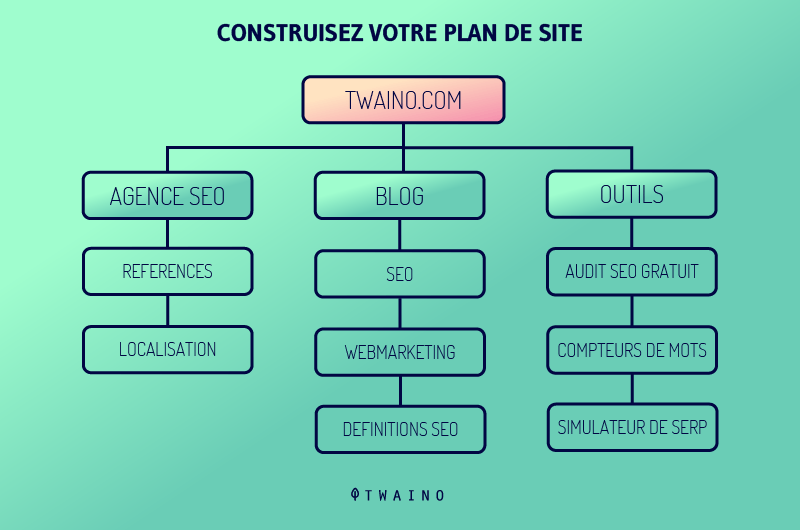
Il est recommandé d’utiliser uniquement des URLs canoniques pour votre plan de site.
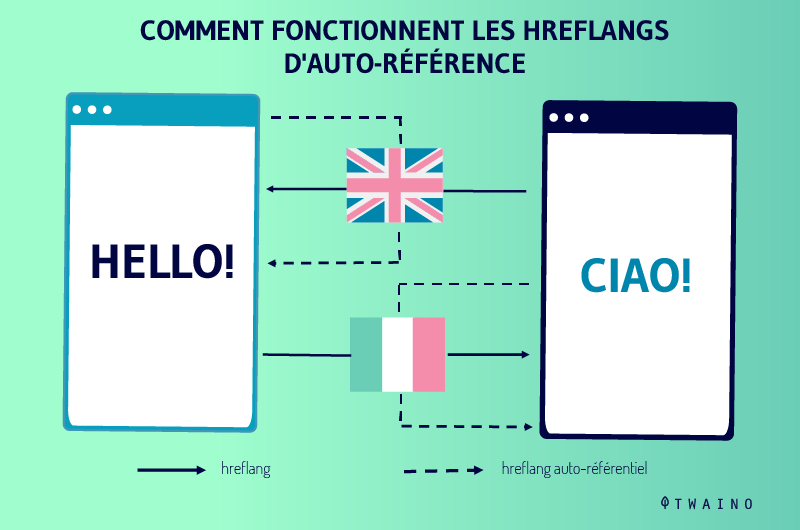
4.7. Les balises Hreflang sont indispensables
Quand il s’agit d’explorer une page locale, les robots d’indexation se basent sur les balises hreflang. C’est pourquoi il est important d’informer Google des différentes versions que vous disposez.
Retrouvez toutes les informations sur la balise Hreflang dans ce mini-guide.
C’était 7 conseils pour optimiser le budget crawl de votre site, pourtant tout ne s’arrête pas là. Il est aussi utile de surveiller comment Googlebot explore votre site et accède à vos contenus.
Chapitre 5 : Comment surveiller son Budget crawl ?
Pour surveiller le budget d’exploration de votre site, vous disposez de deux outils pour le faire : Google Search Console et le fichier journal du serveur :
5.1. Google Search Console
GSC est un outil proposé par Google qui offre plusieurs fonctionnalités qui permettent d’analyser votre position dans l’index et les SERP du moteur de recherche. L’outil propose également un aperçu de votre budget crawl.
Pour commencer la vérification, vous pouvez accéder au rapport « Statistiques sur l’exploration ». Il s’agit d’un rapport qui retrace sur les 30 derniers jours, l’activité de googlebot sur votre site.
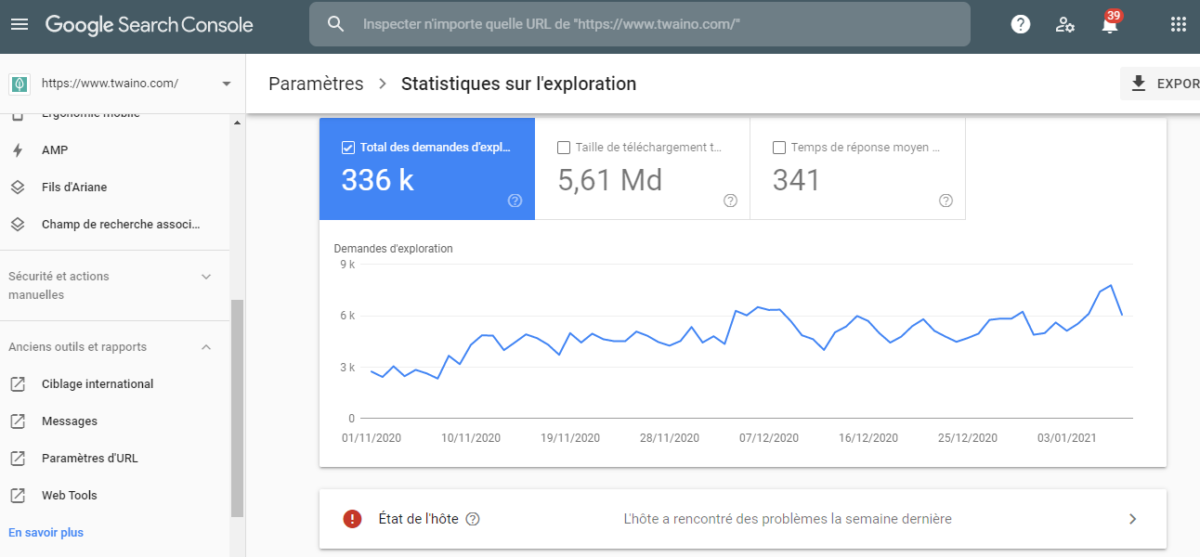
Sur ce rapport, on peut voir que Googlebot explore quotidiennement 48 pages en moyenne sur le site. La formule pour calculer le budget crawl moyen de ce site serait :
BC = Nombre moyen de pages crawlées par jour x 30 jours
BC = 48 x 30
BC = 1440
Donc pour ce site, le budget d’exploration moyen est de 1440 pages par mois.
Toutefois, il est important de souligner que ces chiffres de Google Search Console sont un peu trop abusés.
Mais en fin de compte, il s’agit d’une estimation et non d’une valeur absolue du budget crawl. Ces chiffres permettent juste d’avoir un aperçu du taux d’exploration dont bénéficie le site.
Pour la petite astuce, vous pouvez noter cette estimation avant de commencer l’optimisation de votre budget crawl. Une fois le processus terminé, vous pouvez consulter à nouveau la valeur de ce budget d’exploration.
En comparant les deux valeurs, vous évaluerez mieux le succès de vos stratégies d’optimisation.
Google Search offre également un autre rapport, « un rapport de couverture » pour connaître le nombre de pages qui a été indexé sur le site, ainsi que celles qui ont été désindexées.
Vous pouvez comparer le nombre de pages indexées au nombre total de pages que compte votre site pour savoir le nombre réel des pages ignorées par Googlebot.
5.2. Le fichier journal du serveur
Le fichier journal du serveur reste incontestablement l’une des sources fiables pour vérifier le budget crawl d’un site web.
Tout simplement parce que ce fichier retrace fidèlement l’historique des activités des robots d’indexation qui explorent un site. Dans ce fichier journal, vous avez également accès aux pages qui sont régulièrement crawlées et leur taille exacte.
Voici un aperçu du contenu d’un fichier journal :
11.222.333.44 – – [11 / mars / 2020: 11: 01: 28 –0600] « GET https://www.seoclarity.net/blog/keyword-research HTTP / 1.1 » 200 182 « – » « Mozilla / 5.0 Chrome / 60.0.3112.113 «
Pour interpréter ce bout de code, on dira que le 11 mars 2020, un utilisateur a tenté d’accéder à la page https://www.seoclarity.net/blog/keyword-research depuis le navigateur Google Chrome.
Le code “200” est mis pour signifier que le serveur a bel et bien accédé au fichier et que le fichier pèse 182 octets.
Chapitre 6 : Autres questions posées sur le Budget Crawl
6.1. Qu’est-ce que le budget d’exploration ?
Le budget d’exploration correspond au nombre d’URL sur un site Web qu’un moteur de recherche peut explorer au cours d’une période donnée en fonction du taux d’exploration et de la demande d’exploration.
6.2. Qu’est-ce que le taux d’exploration et la limite de vitesse d’exploration ?
Le taux d’exploration est défini comme le nombre d’URL par seconde qu’un moteur de recherche peut explorer sur un site. La limite de vitesse d’exploration peut être définie comme le nombre maximal d’URL qui peut être exploré sans perturber l’expérience des visiteurs d’un site.
6.3. Qu’est-ce que la demande d’exploration ?
En plus du taux d’exploration et des limites de vitesse d’exploration spécifiées par le webmaster, la vitesse d’exploration varie d’une page à l’autre en fonction de la demande pour une page spécifique.
Les pages les plus populaires seront probablement explorées plus souvent que les pages rarement visitées, celles qui ne sont pas mises à jour ou qui ont peu de valeur.
6.4. Pourquoi le budget d’exploration est-il limité ?
Le budget d’exploration est limité afin de garantir que le serveur d’un site Web n’est pas surchargé par trop de connexions simultanées ou une demande importante de ressources serveur, ce qui pourrait avoir un impact négatif sur l’expérience des visiteurs du site.
6.5. À quelle fréquence Google explore-t-il un site ?
La popularité, la capacité d’exploration et la structure d’un site Web sont tous des facteurs qui déterminent le temps qu’il faudra à Google pour explorer un site. En général, Googlebot peut prendre plus de deux semaines pour parcourir un site. Cependant, il s’agit d’une projection et certains utilisateurs ont prétendu être indexés en moins d’une journée.
6.6. Comment définir un budget d’exploration ?
- Autorisez l’exploration de vos pages importantes pour les robots ;
- Méfiez-vous des chaînes de redirection ;
- Utilisez le HTML chaque fois que possible ;
- Ne laissez pas les erreurs HTTP consommer votre budget d’exploration ;
- Prenez soin de vos paramètres d’URL ;
- Mettez à jour votre plan de site ;
- Les balises Hreflang sont vitales ;
- Etc.
6.7. Quelle est la différence entre l’exploration et l’indexation ?
L’exploration ainsi que l’indexation sont deux choses distinctes et cela est souvent mal compris dans l’industrie du référencement. L’exploration signifie que Googlebot examine tout le contenu ou le code de la page et l’analyse.
L’indexation par contre signifie que Google a fait une copie du contenu dans son index et que la page peut apparaître dans les SERPs de Google.
6.8. Noindex économise-t-il le budget d’exploration ?
La balise meta Noindex n’économise pas votre budget d’exploration Google. C’est une question SEO assez évidente pour la plupart d’entre vous, mais John Mueller de Google a confirmé que l’utilisation de la balise meta noindex sur votre site ne vous aidera pas à économiser votre budget d’exploration. Cette balise meta empêche uniquement l’indexation de la page et non l’exploration.
Conclusion
En somme, le budget crawl regroupe les ressources que Google réserve à chaque site pour l’exploration et l’indexation de ses pages.
Même si le budget d’exploration n’est pas en soi un facteur de référencement, son optimisation peut contribuer au référencement des pages du site, notamment les pages les plus importantes.
Pour cela, nous avons présenté tout au long de ce guide un certain nombre de pratiques à prendre en compte.
J’espère que cet article vous a aidé à mieux comprendre le concept de budget crawl et surtout comment l’optimiser.
Si vous avez d’autres questions, n’hésitez pas à me les faire savoir dans les commentaires.
Merci et à bientôt !


