Le Cloaking est une technique d’optimisation Black Hat qui consiste à apprêter des contenus différents pour une même requête. Dès que la requête est sollicitée, une première réponse, bien optimisée, est présentée aux moteurs de recherche et une autre souvent spammeur est affichée aux internautes.
Avez-vous déjà connu cette situation où vous effectuez une requête sur Google et une fois sur l’une des premières pages, vous remarquez qu’elle n’a finalement aucun rapport avec votre recherche ?
Si oui, vous avez probablement estimé qu’il s’agit d’une erreur de la part de Google. Mais peut-être pas ! Il se peut que vous ayez fait l’objet du cloaking.
Alors :
- Qu’est-ce que le cloaking ?
- Comment ça marche ?
- Quelle utilisation peut-on en faire ?
- Est-ce une pratique recommandée par Google ?
Découvrez une définition complète du terme « cloaking » avec une réponse claire, explicite et précise à chacune des questions.
Chapitre 1 : Le Cloaking – Qu’est-ce que c’est exactement?










Dans ce premier chapitre nous allons ensemble, décortiquer entièrement le mot « cloaking » pour vous aider à avoir une bonne compréhension.
Pour cela, nous allons aborder :
- Son principe général ;
- Et ses objectifs.
1.1. Le principe général du Cloaking
Le principe du cloaking consiste simplement à présenter à deux visiteurs distincts, internaute et robot d’exploration des moteurs de recherche, des pages partiellement ou totalement différentes depuis une même adresse.
On peut aussi parler de ce terme lorsqu’un serveur est configuré pour afficher différents contenus pour une même page web.

1.1.1. De quoi s’agit-il concrètement ?
Traduit de l’anglais, le terme « cloaking » veut dire « dissimulation », « camouflage » ou encore « occultation ».
En d’autres termes, on peut dire qu’il s’agit d’un ensemble de manœuvres qui permet de dissimuler aux robots d’indexation la véritable page web que verra l’internaute sur son écran, en leur soumettant en parallèle une page différente, expressément optimisée pour les robots.
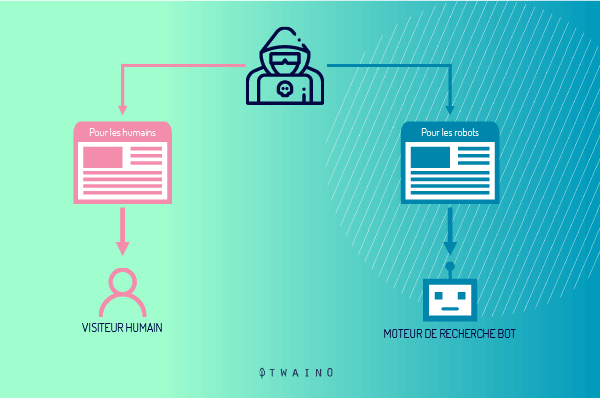
C’est une façon d’arranger le rendu d’une page web en fonction du type d’internaute qui vient consulter l’information.
Du coup, le contenu de l’URL proposée à la demande de l’internaute ne sera pas le même que celui présenté aux robots d’indexation notamment à Googlebot de Google et à Bingbot de Microsoft.
Ce contenu sera disponible alors en deux versions :
- Une version bien optimisée réservée aux moteurs de recherche ;
- Une autre soignée avec des visuelles et réservée aux cybernautes.
1.1.2. Comment le cloaking est-il né ?
C’est bien connu que l’insertion d’éléments multimédias tels que des images ou des vidéos permet de hydra renforcer la qualité générale d’un article et de l’optimiser pour le SEO.

En plus de leur importance en référencement organique, les contenus multimédias favorisent l’expérience utilisateur. La plupart des internautes comprennent facilement les visuels et sont plus enclins à les consulter plutôt qu’à lire du bloc de texte.
Par contre, un point qui semble moins évident et que vous ignorez sans doute, c’est que ces contenus multimédias (les graphiques, les vidéos ou encore les animations flash) rendent les pages web qui les contiennent, un peu difficiles à comprendre pour les robots.
En effet, bien que les moteurs de recherche soient assez doués, ils ne peuvent pas encore interpréter à 100% une image ou une vidéo.
Du coup, ils se basent sur le contenu des balises spécifiques (alt ou title) pour comprendre la thématique qu’abordent ces visuels.
Depuis bien des années maintenant, ces balises propres aux contenus multimédias et que les internautes ne voient pas sont prises en compte par les moteurs de recherche lors de l’indexation.
C’est ici qu’entre en scène le cloaking !
La description des contenus multimédias est alors présentée sous forme de contenus textuels aux robots d’indexation des moteurs de recherche qui peuvent les lire dans leur entièreté sans aucune difficulté.
C’était la petite histoire autour du cloaking pour comprendre son origine.
1.2. Les objectifs du Cloaking










Avec le cloaking, il vous est possible d’accroître votre rang dans les SERPs, mais en étant malhonnête.
Et la faute est bien là : Leurrer les moteurs de recherche dans le but d’obtenir sournoisement une meilleure place dans les SERP.
Généralement utilisé à des fins SEO, le cloaking est une technique qui sert résolument bien en Black Hat, où elle permet d’améliorer malhonnêtement la position des sites internet dans les SERP.

Mais quand on y pense, le but du cloaking ne se limite pas uniquement à la tromperie !
Il existe aussi d’autres raisons, éthiques cette fois-ci, de recourir au cloaking.
Dans cette série de bonnes intentions, on peut citer :
- Le désir de présenter aux utilisateurs une page web attrayante et bien illustrée avec si possible des vidéos développées dans leur langue natale ;
- Protéger l’accès d’une page web aux robots collecteurs de mails ;
- La présentation de publicités ciblées ;
- L’adaptation du design et du mode d’affichage de la page web en fonction du navigateur utilisé (Mozilla Firefox, Chrome, Explorer, à titre d’exemple) ;
- Et bien d’autres.
En récapitulatif, le cloaking est l’une de ces pratiques aux multiples facettes, dont les objectifs varient en fonction de vos intentions et des utilisations que vous en faites.
Ceci étant, comment fonctionne-t-il techniquement ?
Chapitre 2 : Comment fonctionne techniquement le cloaking ?
Dans ce deuxième chapitre, je vais d’abord aborder les notions basiques du fonctionnement de la technique de camouflage et ensuite parler de ses multiples variantes.
2.1. Les bases du fonctionnement de la technique du Cloaking
Comme rappel, le cloaking permet de présenter une page aux utilisateurs et une autre suffisamment optimisée pour plaire aux robots de Google.
Mais comment expliquer ce petit jeu habile de passe-passe ?
Eh bien, tout se joue sur l’identification d’un certain nombre de paramètres tels que :
- Le user agent ;
- L’hôte ;
- L’adresse IP ;
- Et bien d’autres.
En fonction du paramètre qui sert de support, le type de cloaking peut être différent.
Quand un utilisateur se rend sur un site web, son navigateur envoie systématiquement une demande au serveur qui héberge le site.
Cette requête est rendue possible grâce au protocole HTTP (Hypertext Transfer Protocol) qui renseigne de nombreux éléments sur l’utilisateur y compris les paramètres d’identification suscités.
Ces paramètres permettent au serveur hébergeant le site internet d’identifier et de distinguer les divers types de visiteurs du site web. À partir du moment où le serveur constate la présence d’un visiteur, il adapte automatiquement le contenu du site réservé pour ce type de visiteur.
Le serveur est programmé de telle sorte que lorsqu’il se rend compte que le visiteur n’est pas un internaute humain et qu’il s’agit plutôt d’un robot d’indexation, le script (en langage serveur PHP, ASP…) qui est proposé change et est différent de celui de la page officielle, réservé pour les visiteurs humains.
On comprend facilement comment les administrateurs d’un site arrivent intentionnellement à vous faire parvenir la page de leur choix grâce à vos paramètres d’identification transmis lors de votre requête.
C’est le même scénario qui est aussi utilisé pour les moteurs de recherche.
Une pratique générale de par son principe, mais qui se veut être unique dans ses formes.
Le fonctionnement proprement dit du cloaking sera détaillé de manière spécifique dans chacune de ses nombreuses déclinaisons dans la section suivante.
2.2. Les multiples variantes de la technique du cloaking
Quels sont les différents types de cloaking ?
C’est de cela que nous discuterons dans cette section. J’aborderai ici chacune des variantes les plus fréquemment rencontrées, dans leur forme, leurs particularités et leur mécanisme.










2.2.1. Le Cloaking « Agent Name Delivery » axé sur un user agent
Le cloaking basé sur l’user agent est de loin la forme la plus répandue de la technique. Et pour cause, l’accès au web se fait usuellement via un navigateur, et qui dit navigateur, dit forcément user agent.
L’user agent est alors devenu le paramètre d’identification préféré des administrateurs de site web.

Lorsqu’un visiteur humain ou un robot se connecte à un site web, l’user agent fait partie intégrante de l’en-tête HTTP (l’ensemble des méta-informations et des données réelles échangées via une requête HTTP) qui est envoyé au serveur du site.
Encore intitulé agent name, le user agent est effectivement un identifiant, une signature qui est spécifique à tous les visiteurs d’un site internet.
Ainsi donc, que ce soit un internaute qui accède au site internet depuis un navigateur (Safari, Opéra, Chrome, Explorer…), ou un programme automatisé (les spiders, les bots, les crawlers et tout autre robot des moteurs de recherche), chacun possède son agent name spécifique.
Comme expliqué un peu plus haut, à chaque visite sur un site web, votre navigateur transmet une requête HTTP au serveur Web. Dans cette requête, le user agent apparaît comme suit :
USER-AGENT=Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 10.0; WOW64; Trident/6.0)
Dans notre exemple, le navigateur web avec lequel vous vous êtes connecté est Internet Explorer 10 utilisé sous Windows 10 dans la version 6.0 de son moteur d’affichage de page web.
Cela mis de côté, l’identification de l’agent name permet aussi au serveur de “cloaker“ (moduler, dissimuler ou encore adapter) les contenus de la page web en question.
Le serveur peut également peaufiner l’ergonomie de la page web grâce à des feuilles de style optimisées (CSS).
L’agent name delivery sert donc ici de base au cloaking. Eh oui, c’est de lui que partiront toutes les modifications aboutissant à l’affichage des différents contenus réservés à chaque partie, internaute et robot.
Dès la réception de la demande du navigateur, le serveur du site s’occupera de charger (pour les pages HTML) ou de générer (pour les pages PHP), la page web que vous avez sollicitée dans sa forme “humanisée“ (textes et images, vidéos…).
D’un autre côté, à la réception d’une demande provenant d’un robot, le serveur du site se chargera d’afficher la page web dans sa forme ultra optimisée et remplie de contenus textuels pour les robots.
On retiendra que le cloaking axé sur le user agent est un classique. Ce que je ne vous ai pas dit par contre, c’est que ce type de cloaking est résolument l’une des formes les plus risquées de la technique.
Étant facilement détectable par les moteurs de recherche, elle tend tout de même à s’effacer au profit des autres types.
2.2.2. Le Cloaking « IP Delivery » portant sur l’adresse IP
Le cloaking portant sur l’adresse IP (Internet Protocol) est une forme de cloaking assez similaire au précédent.
Ici également, il s’agit de classer les visiteurs du site en humains et en non-humains (robots d’indexation) afin de leur offrir un contenu distinct et adapté.
À contrario de la forme vue précédemment, ce type de cloaking est souvent utilisé avec de bonnes intentions.
En effet, cette pratique est souvent employée dans le cadre du Geotargetting (géolocalisation de l’internaute) où elle permet au serveur du site web, d’adapter la langue des pages web et/ou les publicités aux visiteurs du site web en fonction de leur région.
Loin de se limiter à ces utilisations pour le moins pacifistes, le cloaking basé sur l’adresse IP intervient également dans les manœuvres de référencement abusif. Notamment lorsque les administrateurs du site web fournissent des contenus strictement dédiés à l’adresse IP standard connue des robots d’exploration.
L’adresse IP est en réalité une suite de chiffres (192.153.205.26 par exemple) disponible dans les logs. Ces derniers sont des fichiers d’un serveur internet qui contient les informations comme la date et l’heure de connexion, mais également l’adresse IP des visiteurs.
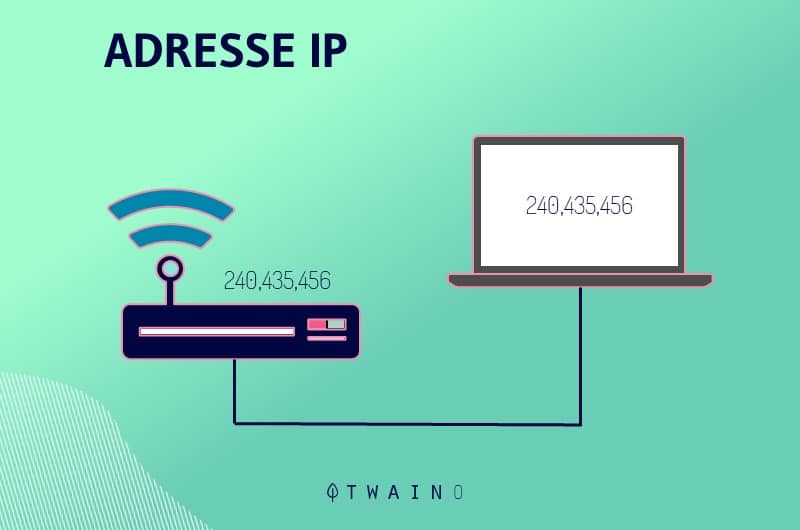
Cette suite de chiffres qui est propre à chaque appareil connecté à internet, renseigne notamment sur la localisation géographique et le service internet des utilisateurs.
Il est important de le souligner, les serveurs internet sont parfaitement capables de segmenter leurs visiteurs (robots et humains) simplement à partir de leur adresse IP.
Le cloaking basé sur l’adresse IP consiste alors à repérer une adresse IP et en fonction de la nature humaine ou non de son détenteur, à modifier le contenu de la page web en conséquence.
Cette variante de la technique présente toutefois une sérieuse insuffisance. Elle ne saurait fonctionner que si les robots des moteurs de recherche utilisaient pour un même site, la même adresse IP.
Bien heureusement ou malheureusement, la grande majorité des moteurs de recherche optent pour des adresses IP changeantes.
Un moyen simple d’éviter d’être l’objet de manipulation.
2.2.3. Le Cloaking par JavaScript, Flash ou DHTML
D’abord, notons-le :
- Le JavaScript (abrégé en JS) est un langage de programmation de scripts léger, créé pour rendre les pages web dynamiques et interactives.
- Le DHTML ou HTML dynamique de l’anglais Dynamic HTML, représente l’ensemble des techniques de programmation utilisées pour qu’une page web HTML soit capable de se transformer elle-même lors de sa consultation dans le navigateur web.
- Flash ou Adobe Flash, anciennement appelé Macromedia Flash, est un logiciel de manipulation de graphiques vectoriels, d’images matricielles et de scripts ActionScript afin de créer des contenus multimédias à l’intention du web.

Il convient aussi de le rappeler, à l’instar des contenus multimédias pris en exemple dans le chapitre précédent, les moteurs de recherche semblent également avoir du mal à cerner et comprendre les codes JavaScript, Flash ou DHTML.
Une limitation des plus épineuses pour les moteurs de recherche, car elle sert de porte d’entrée et permet indirectement la pratique du cloaking sous cette forme.
Il suffit donc que le cloaker (personne pratiquant le cloaking) crée une page web truffée de mots clés où figure une redirection dans l’un de ces langages (JS, FLash, DHTML) vers une page “convenable”.
Par l’intermédiaire de son navigateur qui suivra la redirection, l’internaute accèdera à la page bourrée de mots clés tandis que les robots indexeront le leurre “convenable” qu’ils afficheront dans leur SERP.
On peut le dire, cette variante de la technique est bien simple à établir. En outre, elle est plus ardue à repérer pour les moteurs de recherche puisqu’elle associe l’utilisation de codes qui leur sont assez difficiles à interpréter.
Cette forme particulière de la technique est la plus employée par les cloakers. Bien qu’étant facile à mettre en œuvre, le cloaking via JS, Flash ou DHTML reste de la pure et simple tricherie.
Ses objectifs sont clairs et il n’en saurait être autrement, il s’agit de duper les moteurs de recherche et les utilisateurs, sur la nature réelle de la page web.
2.2.4. Le Cloaking « Old school » à travers un texte ou un bloc invisible
Eh oui, on retourne aux fondamentaux. Le cloaking du texte ou du bloc invisible est un peu comme une pratique de la vieille école.
Il s’agit en effet de la forme la plus ancienne de sa catégorie, la plus fallacieuse et la plus risquée du cloaking (premier du nom). Désormais, facilement repérable (et sanctionnée), elle ne semble même plus duper les utilisateurs, encore moins les robots de moteurs de recherche.
Concrètement, cette variante de la technique consiste simplement à mettre ici et là sur la page web un contenu invisible (un texte blanc sur fond blanc, ou un texte noir sur fond noir ou encore un frame aux dimensions microscopiques) pour les internautes.

Source : Javatpoint
Ce contenu, bien qu’invisible pour l’internaute, sera tout de même considéré et valorisé par certains moteurs de recherche.
Ainsi le texte invisible va être un listage brut de mots clés ou tout autre élément capable d’améliorer la pertinence de la page web et donc sa position dans les résultats des moteurs de recherche.
Par ailleurs, il est possible d’ajouter le bloc invisible sur un bloc parfaitement visible pour l’utilisateur, en s’aidant du CSS (Cascading Style Sheets ou Feuilles de style en cascade en français).

Au final, une partie de la page web (optimisée pour les robots) est dissimulée à l’internaute.
Enfin, cela c’était il y a 10 ou 15 ans. Aujourd’hui, cette variante de la pratique est obsolète et clairement proscrite.
La grande majorité des moteurs de recherche ne se laissent plus prendre au jeu de cache-cache. Même le CSS est accessible aux bots des moteurs de recherche qui ont tôt fait de percer à jour la ruse.
Comme si cela ne suffisait pas, les utilisateurs les plus malins sont également capables juste en sélectionnant à la souris les régions suspectes de la page, de mettre à découvert le contenu masqué.
Une technique simple et ingénieuse devenue révolue et vulnérable.
2.2.5. Les autres formes de Cloaking
À part ces 4 formes de cloaking précitées, il existe d’autres formes que nous allons aborder pour boucler cette section.
2.2.5.1. Le cloaking à travers le HTTP_Referer et le HTTP Accept-Language
Il s’agit de deux variantes similaires de par la technique. Elles se basent sur des paramètres compris dans l’en-tête HTTP.
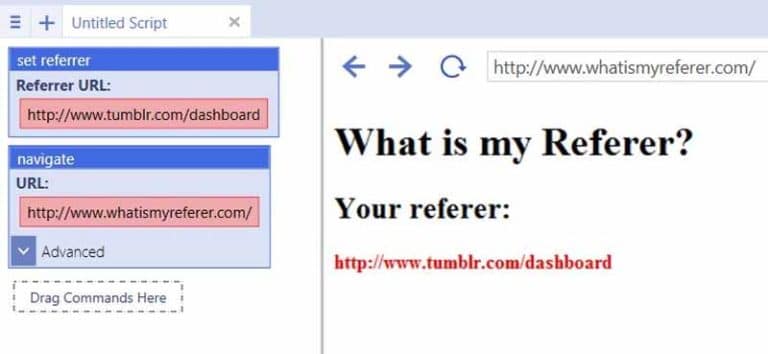
Le Referer ou Referrer apparaît sous la forme d’une URL :
Source: ubotstudio
C’est l’adresse complète ou partielle de la page web d’où l’utilisateur a lancé sa requête pour accéder à la page courante où il se trouve. Sa syntaxe est :
REFERRER=https://www.twaino.com/definition/a/above-the-fold/
Dans cet exemple, l’internaute à lancer une requête depuis la page “Définition” du site Twaino.com pour accéder à la page proposant la définition de “Above the fold”
Quant au paramètre Accept-Language de la requête HTTP, il indique les diverses langues que le client est capable de comprendre ainsi que les variantes locales préférées de cette langue. Le contenu d’Accept-Language ne dépend pas de la volonté de l’utilisateur.
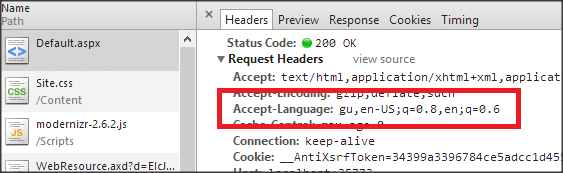
Source : dotnetexpertguide
Le cloaking à travers le HTTP_Referer consiste véritablement à vérifier l’en-tête HTTP_Referer du visiteur et en fonction de l’identité du demandeur, à proposer une version différente de la page web.
C’est pareil pour le cloaking via le HTTP Accept-Language. Après identification de l’en-tête HTTP Accept-Language de l’utilisateur, en fonction des correspondances réalisées, une forme spécifique de la page web sera affichée.
2.2.5.2. Le cloaking axé sur l’hôte
Host en anglais, l’hôte est également une composante de l’en-tête HTTP. Il renseigne sur le nom du site sur lequel se trouve la page que consulte l’internaute.
Il se présente comme suit :
HOST: www.twaino.com
Il s’agit ici de s’attaquer directement au serveur à partir duquel l’utilisateur se connecte sur internet. Il est ainsi possible de directement identifier les différents serveurs des moteurs de recherche.
Plus efficace et plus redoutable que la forme portant sur l’adresse IP, cette forme de cloaking est difficilement détectable.
Chapitre 3 : Quelques cas d’usage du Cloaking
Ça y est, on a vu le cloaking en détail dans ses principes de fonctionnement. Mais quand n’est-il de son utilisation ? Quels sont les divers cas d’usage de cette technique ?
Dans ce chapitre, je vous décris quelques applications connues et relativement acceptées de cette pratique. Des cas d’usages particuliers montrant le cloaking comme vous le connaissez maintenant, sous un nouveau jour.










3.1. Le Cloaking dans l’optimisation du crawl budget
Le crawl budget ou budget de crawl (ou encore budget d’exploitation en français) est globalement la quantité de temps que Google s’accorde à passer sur un site web.

De manière pratique, cela correspond au nombre de pages limites que le bot de Google va explorer/crawler sur votre site web selon le temps qu’il passera sur celui-ci.
Cette exploration tient compte d’un bon nombre de critères.
On peut entre autres citer :
- La rapidité du serveur à répondre : La vitesse de chargement du site est également prise en compte ;
- La profondeur de la page : C’est-à-dire le nombre total de clics nécessaires pour atteindre une page du site depuis la page d’accueil ;
- La fréquence des mises à jour : Soit la qualité, l’unicité et la pertinence du contenu du site ;
- Et plus encore.
Pour bien comprendre l’intérêt du cloaking dans l’amélioration et l’augmentation du crawl budget de votre site, il est important d’avoir une idée générale sur le fonctionnement des robots d’exploration. Que viennent-ils faire concrètement sur votre site web ?
Ce n’est rien d’extraordinaire. Les crawlers sont en réalité programmés pour accomplir un certain nombre de tâches après avoir accéder à votre site internet.
Ils parcourent un grand nombre d’URLs pour lesquelles ils indexent individuellement les contenus.

Pour optimiser son crawl budget, il s’agira donc de faire en sorte que le crawler ne soit pas distrait et occupé par des éléments impertinents et/ou inutiles.
Dans un premier temps, il est conseillé d’analyser les fichiers de logs, puis de supprimer les URL non pertinentes pour votre SEO.
Évidemment, il vaut mieux que tout ce qui est fichiers JavaScript ou encore CSS soit tenu en retrait pour que les bots se concentrent plus sur vos pages HTML.
Il est de ce fait recommandé de cloaker (dissimuler ou rediriger) les fichiers JS ou CSS afin de réserver la grande majorité de votre crawl budget au crawling des contenus de première importance.
Voilà autant d’astuces pour mieux exploiter son crawl budget grâce au cloaking.
3.2. Le Cloaking en rapport avec le comportement des visiteurs
Ce cas d’usage, il faut le notifier, est une application très particulière de la technique.
À première vue, cela ne frappe pas aux yeux et pour cause, il ne s’agit pas vraiment du cloaking tel que nous le connaissons, mais plutôt d’une forme assez ambiguë traitée à tort ou à raison pour du cloaking.
Pour étayer cette utilisation et faciliter sa compréhension, créons un contexte.
Supposons donc que vous possédez un site web sur lequel vous avez prévu un dispositif d’accueil itératif et changeant pour les visiteurs en provenance de Google.

C’est-à-dire, un système qui reçoit les utilisateurs de manière différente. Par exemple, vous aménagez un bloc à cet effet en haut de page, où vous proposer selon la requête de l’internaute, un message de bienvenue associé soit à :
- Une demande d’abonnement aux flux RSS et/ou à la newsletter ;
- Une suggestion de quelques articles complémentaires à lire ;
- Et bien d’autres choses encore.
Voilà, du fait que le moteur de recherche n’a pas droit à tout ou partie de ces propositions tandis que l’internaute en a l’accès est considéré comme étant du cloaking.
Pour Google, le traitement que vous réservez aux utilisateurs n’est assurément pas le même que celui qui est proposé aux robots d’exploration.
Il en va de même pour les pages web où les utilisateurs sont systématiquement redirigés vers des pages autres que celles initialement retrouvées dans les SERP de Google.
3.3. Le Cloaking dans les tests A/B ou les tests multivariables
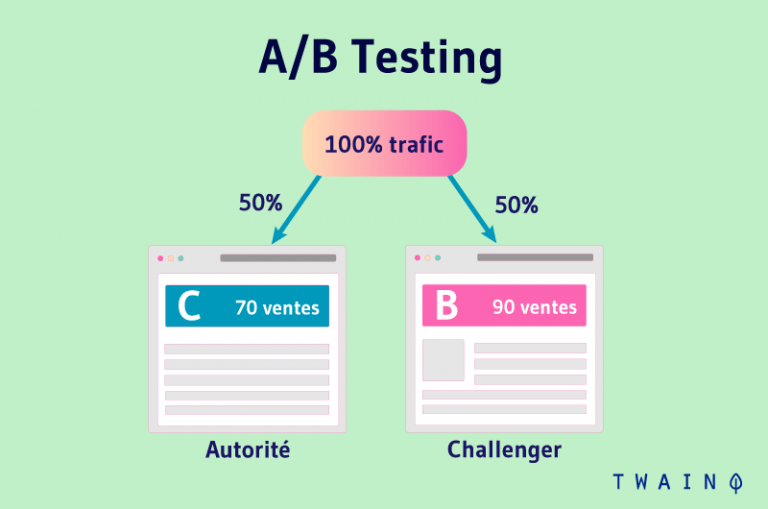
Un test A/B ou A/B testing est une démarche marketing qui permet de tester plusieurs mises en forme des composantes d’une page web. Pour ce faire, il est proposé aux internautes des variantes modifiées de ladite page web.
Par exemple, le site affiche une page d’achat A à un visiteur 1 et une page d’achat B à un visiteur 2. Ce test permet notamment d’évaluer la productivité et le rendement des différentes pages.
En ce qui concerne les tests multivariables ou multivariate testing (MVT), il s’agit de dérivés du test A/B. Un MVT consiste à créer un nombre colossal de versions d’une seule et même page qui sera renvoyé à plusieurs catégories de visiteurs.

Par exemple, en mettant en place un test à plusieurs variables, vous serez en mesure de tester à la fois 3 en-têtes différents, 5 publicités différentes ainsi que 2 images différentes.
Chaque association sera mise en ligne de façon aléatoire, ainsi vous obtiendrez pour votre test au total 3 x 5 x 2 = 30 différentes variantes pour la même page. L’objectif étant de définir la combinaison (en-tête + publicité + image) parfaite pour votre page.

Ne vous inquiétez pas, les techniques de test A/B ou multivariables, lorsqu’elles sont appliquées de façon standard, respectent les directives de Google.
En effet, Google à minutieusement et rigoureusement codifié la réalisation des tests à plusieurs variables.
Pour le moteur de recherche, l’utilisation éthique d’outils de test à plusieurs variables n’est pas une forme de cloaking.
Nous recommandons les tests constructifs : L’optimisation des pages d’un site arrange d’une part les annonceurs, puisque le nombre de conversions augmente et d’autre part les utilisateurs, qui retrouvent des informations efficaces.
Le moteur de recherche renseigne par ailleurs sur les mesures générales à respecter pour que les tests A/B ou multivariables ne soient pas considérés comme du cloaking et traités comme tels.
Ainsi, Google recommande que :
- Les variantes respectent l’essence même du contenu de la page d’origine de manière à ce que ni le sens, ni l’impression générale qu’en ont les utilisateurs ne soient modifiés.
- Le code source se doit d’être régulièrement actualisé. Bien entendu, le test doit être stoppé immédiatement après la collecte suffisante des données.
- La page d’origine doit toujours être celle proposée à la majorité des utilisateurs. Vous pouvez recourir à un optimiseur de site pour exécuter brièvement la combinaison victorieuse à la fin du test, mais il faut veiller au code source de la page de test pour vite reconnaître la combinaison gagnante.
Le moteur de recherche se réserve également le droit de prendre des mesures à l’encontre des sites web ne respectant pas ses instructions et de ceux dont il a le sentiment que les utilisateurs sont abusés et/ou trompés.
Chapitre 4 : Le Cloaking en SEO : Une fausse bonne idée ?
Jusqu’ici, la technique de camouflage vous est maintenant compréhensible dans son ensemble. Toutefois des zones d’ombre perdurent.
- Le cloaking est-il une technique conseillée en SEO ?
- Quelle est sa place selon Google ?
- En définitive, est-ce une technique recommandable ?
Dans ce chapitre, il s’agit d’éclairer tous ces points d’ombres propres à la technique.
4.1. Le Cloaking selon Google : Une technique controversée ?
Avec le moteur de recherche, tout est un peu plus clair, le cloaking est inadmissible.
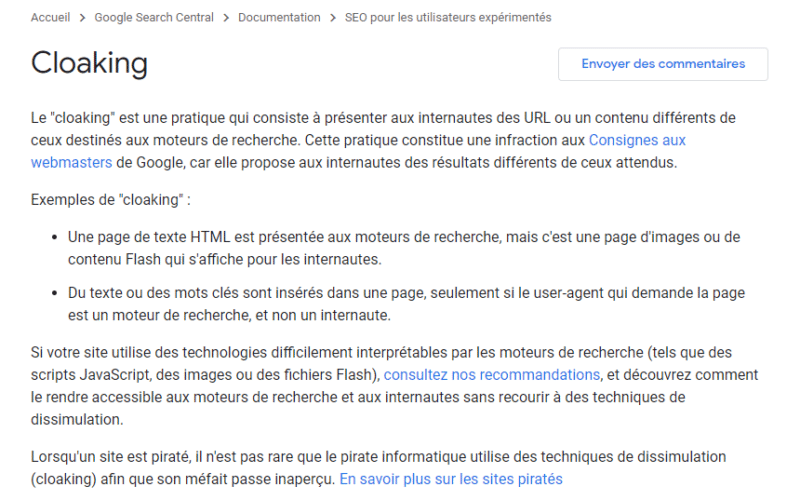
Google dit officiellement :
“Le « cloaking » est une technique qui consiste à offrir aux utilisateurs des URL ou un contenu différent de ceux destinés aux bots des moteurs de recherche. Cette pratique représente une infraction aux guidelines de Google, car elle propose aux utilisateurs des résultats distincts de ceux attendus.”
4.2. Cloaking : SEO White ou Black Hat ?










Faisons un petit rappel. En matière de référencement naturel (SEO), l’on distingue généralement deux grandes familles de pratiques : le SEO white hat et le SEO black hat.

Comme vous vous en douter, le white hat fait référence à l’ensemble des bonnes pratiques SEO à l’opposé du black hat qui associe l’ensemble des pratiques SEO douteuses et interdites.
En effet, le propre du SEO white hat est le respect des directives des moteurs de recherche (principalement Google) en toute transparence dans l’optimisation des sites web.
Ici la qualité, la pertinence ainsi que la valeur ajoutée du contenu sont la pierre angulaire de tout bon référencement organique.

À contrario, le SEO black hat consiste globalement à leurrer, tromper et détourner les algorithmes des moteurs de recherche pour une seule et même raison : Obtenir un meilleur positionnement dans les classements.
La quasi-totalité des moyens privilégiés en SEO black hat relève de l’interdit (des techniques formellement proscrites par les moteurs de recherche).
Qu’en est-il du cloaking ?
Nous l’avons vu, le principe premier du cloaking est de présenter des contenus différents en fonction du type de visiteurs (un internaute humain ou un robot). Le plus souvent, une partie du contenu est occulté soit chez les utilisateurs ou chez les robots d’indexation.
Cette tactique de dissimulation est clairement considérée comme étant du black hat.
En fin de compte, le cloaking est une méthode black hat dépourvue d’éthique, contraire au guideline Google et dûment prohibée. Il vise à rapidement et frauduleusement obtenir une meilleure position dans les SERP.
Il n’empêche que toutes les techniques et utilisations du cloaking ne sont pas mal intentionnées, vous le savez !
4.3. Le Cloaking : Est-ce vraiment une pratique recommandable ?
Au vu de tout ce qui a précédemment été développé, la réponse logique et justifiée serait : NON !
Le cloaking en plus de ses diverses utilités peut également permettre de gagner des places dans les SERP.










Pour se protéger du cloaking, Google et les autres moteurs de recherche prennent des mesures sévères :
- Pénalités ;
- Robots d’exploration masqués ;
- Système de dénonciation ;
- Webspam Team ;
- Etc.
Les sanctions algorithmiques et manuelles du moteur de recherche sont notamment redoutables.
Elles intéressent tout ou partie du site web et peuvent aller jusqu’à la suppression définitive du site de l’index Google. Et pour cause, en 2006 certains sites (cloakés) de la marque BMW en ont fait les frais.
Dans les mains d’experts et de professionnels, appliqué en adéquation aux prescriptions des moteurs de recherche et avec de bonnes intentions, le cloaking revêt de sérieux atouts.
Chapitre 5 : Autres questions posées sur le Cloaking
5.1. Qu’entend t-on par le cloaking ?
Le cloaking est une mauvaise technique d’optimisation des moteurs de recherche qui consiste à présenter aux utilisateurs humains et aux moteurs de recherche, des contenus ou URLs différents. Cette pratique est considérée comme une violation des consignes de Google, car elle fournit aux visiteurs des résultats différents de ceux auxquels ils s’attendaient.
5.2. Le cloaking est-il illégal ?
Le cloaking est considéré comme une pratique SEO Black Hat, donc illégal (selon la loi ‘’ Google’’). Le moteur de recherche peut sanctionner, voire bannir définitivement de son index tout site qui se livre à cette pratique.
5.3. Quels sont les différents types de cloaking ?
Nous avons le cloaking :
- « Agent Name Delivery » axé sur un user agent ;
- « IP Delivery » portant sur l’adresse IP ;
- Par JavaScript, Flash ou DHTML ;
- « Old school » à travers un texte ou un bloc invisible ;
- À travers le HTTP_Referer et le HTTP Accept-Language ;
- Axé sur l’hôte.
5.4. Qu’est-ce que le cloaking sur Facebook ?
Le camouflage est une technique utilisée pour contourner les processus de révision de Facebook, afin de montrer aux utilisateurs un contenu qui n’aurait pas été conforme aux normes des directives de la communauté.
5.5. Comment vérifier le cloaking ?
Dans l’outil cloaking checker, entrez l’URL du site Web à vérifier. Cliquez sur le bouton « Vérification du cloaking », et il testera l’URL. S’il détecte ou non le camouflage, cela apparaîtra dans les résultats. Si vous trouvez du camouflage sur votre site Web, vous devriez vous inquiéter, car votre site Web peut-être sanctionné par les moteurs de recherche.
En résumé
Le cloaking est une technique non recommandée par Google et dont l’application n’est pas sans conséquence.
Grâce à cet article, vous en savez suffisamment sur cette pratique et ses multiples aspects. Il vous revient maintenant de vous faire votre propre opinion et/ou expérience sur le sujet.
Si vous connaissez d’autres techniques ou applications de cloaking, n’hésitez pas à les partager avec nous dans les commentaires.
A bientôt !



1 réflexion au sujet de « Définition Cloaking »