
Le contenu dupliqué fait référence à des blocs de texte qui sont soit complètement identiques les uns aux autres (doublons exacts), soit similaires avec des différences mineures, également connus sous le nom de quasi-dupliqués. En SEO, le duplicate content se produit lorsque ce type de contenu apparaît sur plusieurs URLs ou pages Web d’un même site ou de différents sites Web.
Selon Matt Cutts de Google, 25 à 30 pourcents des contenus sont en double sur Internet. Pour rester dans la même logique, une étude récente de Raven Tools basée sur les données de leur outil d’audit nous donne un chiffre approximatif de 29 % concernant le même problème.
Bien que ce phénomène ne soit souvent pas intentionnel, Google et d’autres moteurs de recherche pénalisent de façon indirecte les sites web ayant des contenus dupliqués.
Pour comprendre au mieux cette notion, il convient d’aborder les points capitaux suivants :
- Un bref aperçu du sens de ‘’duplicate content’’ et ses différents types ;
- Les causes et moyens de les repérer ;
- Les bonnes pratiques pour les gérer.
Voilà quelques-unes des nombreuses questions phares auxquelles je vais apporter des réponses claires et précises tout au long de ce guide.
Découvrez-en !
Chapitre 1 : Que doit-on comprendre sur le thème ‘’contenu dupliqué’’ ?
Dans ce chapitre, je vous expose les points essentiels sur le contenu dupliqué tels que :
- Un bref rappel de sa définition ;
- Les différents types qui existent ;
- Son impact sur le référencement.










1.1. Le contenu dupliqué : C’est quoi ?
Le contenu dupliqué est un bloc de texte qui apparaît plusieurs fois sur le Web. Lorsqu’un texte est présent sur une URL unique, on parle de contenu unique. Dans le cas contraire, il est considéré comme dupliqué.

Pour être plus clair, c’est l’acte de copier la production d’autres personnes et de le publier sur votre site. En général, cette reproduction se fait sans l’autorisation préalable de son auteur.
Non seulement cela peut susciter des doutes sur votre capacité à produire des textes attrayants et originaux, mais aussi Google risque de pénaliser votre référencement.
1.2. Quels sont les différents types de contenu dupliqué ?










Les contenus dupliqués ne découlent pas seulement d’une copie volontaire de textes ou de parties de ceux-ci, mais très souvent aussi :
- Des causes techniques liées au fonctionnement du CMS ;
- Des raisons liées à la gestion du catalogue de produits dans le cas d’un e-commerce ;
- Etc.
De ces cas qui conduisent à la génération de doublons, on déduit deux types de duplicate content :
1.2.1. Le duplicate content interne ( sur un même site )
On parle de duplicate contente interne lorsqu’on constate une répétition d’un texte ou des parties de texte sur deux ou plusieurs pages d’un même site web.

Les contenus dupliqués internes sont généralement de bonne foi, car ils proviennent principalement :
- Des erreurs techniques ;
- Du paramétrage des URLs ;
- Etc.
Il est à noter qu’il ne s’agit pas du vol de contenu dans ce cas, mais des erreurs qui entraînent la multiplication de celui-ci sur différentes URLs.
1.2.2. Contenu dupliqué externe
Il s’agit de pages dont le texte est le même que celui présent sur d’autres sites. Ce type de duplicate contente est celui qui provoque de vrais conflits.

Ce cas se retrouve notamment dans les fiches produits e-commerce, contenant les informations techniques sur les produits et leurs fonctions d’utilisation.
Il n’est pas rare de voir dans le commerce électronique certaines personnes qui utilisent pour leurs produits les descriptions de leurs fournisseurs. Cela conduit à la présence du même contenu textuel sur plusieurs sites web.
1.3. Quel impact peut avoir la duplication de contenu sur le référencement et le classement d’un site ?









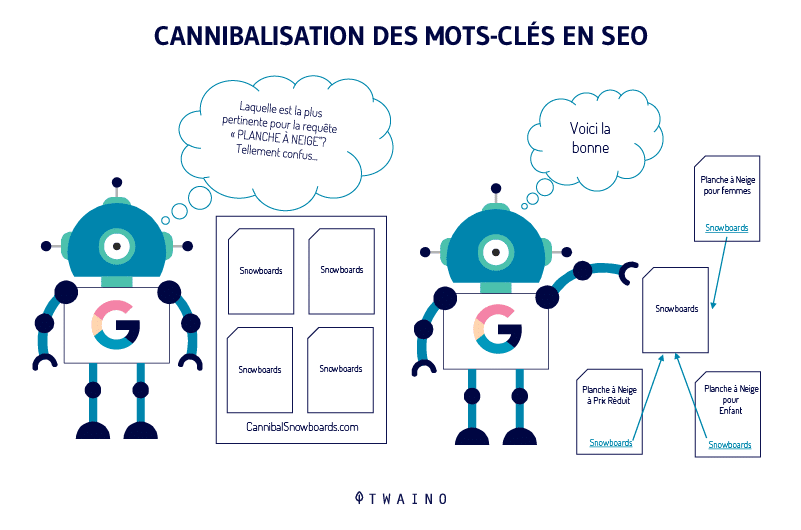
En raison de la confusion que le duplicate contente provoque chez les robots des moteurs de recherche, tout classement et notoriété peut finir par être divisé entre les URL dupliquées.
Cela se produit parce que les robots des moteurs de recherche doivent choisir la page Web qu’ils pensent devoir classer pour un mot-clé particulier.
Ainsi, chaque variante d’URL reçoit des scores d’autorité de page et une puissance de classement différente.
Mais avec le temps, Google a fini par comprendre que la plupart des contenus dupliqués ne sont pas créés intentionnellement.
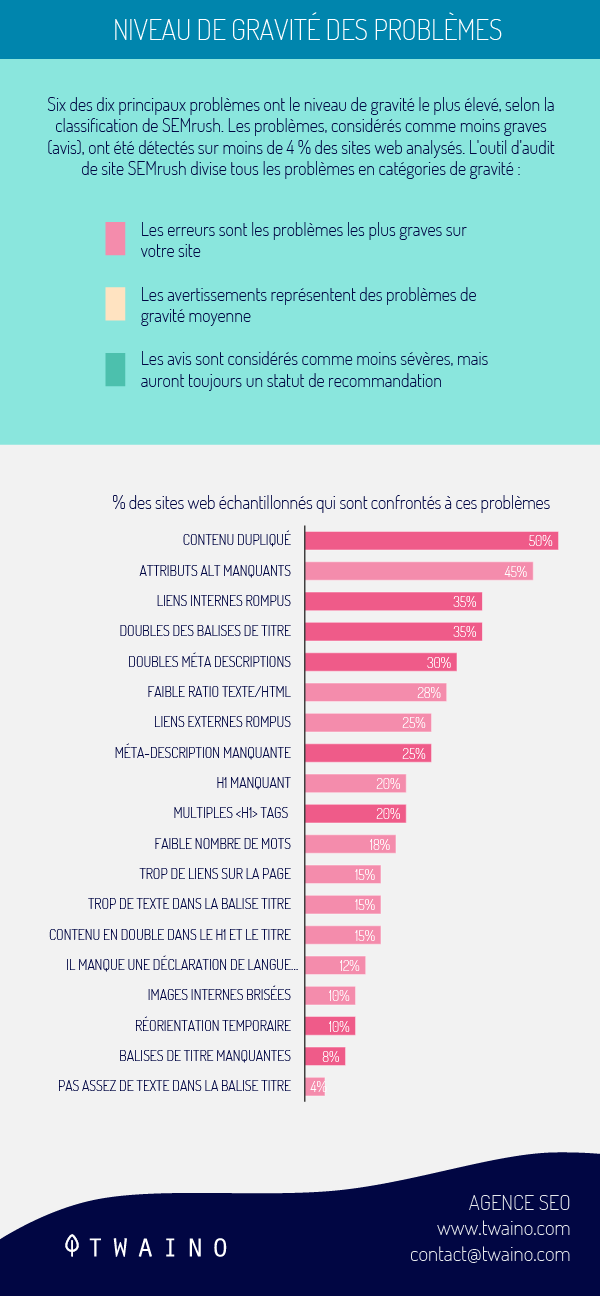
Une analyse résulte que 50% des sites Web se confrontent aux problèmes de duplication de contenu.
Le but de Google est d’afficher une diversité de sites dans les résultats de recherche. Ceci étant, les robots d’exploration des moteurs de recherche sont obligés de choisir la version de contenu à classer.
Dans ce cas, vos productions textuelles que vous considérez comme étant les plus appropriées pour des thématiques données peuvent ne pas être classées en raison de leur similitude avec d’autres existants.
En bref, on peut résumer les problèmes que rencontres les sites web liés à la duplication de contenu en 3 points :
- Difficulté de classement des résultats de recherche ;
- Affichage d’une mauvaise expérience utilisateur ;
- Et la diminution du trafic organique.
Bien sûr, ce ne sont évidemment pas les seuls problèmes liés à la duplication de contenu, mais ce sont les plus pénibles pour un site.
Chapitre 2 : Quelles sont les causes et comment repérer les contenus dupliqués ?
Comme l’annonce déjà le titre de ce chapitre, nous allons, après avoir exposé les causes de la duplication de contenus, vous montrer comment vous pouvez les détecter.










2.1. Quelles sont les causes de la duplication de contenu ?
Il existe de nombreuses raisons pour lesquelles un contenu dupliqué peut être créé, mais nous allons citer quelques unes :
2.1.1. ‘’HTTP’’ vs ‘’HTTPS’’ et ‘’WWW’’ vs sans ‘’WWW’’
Ajouter des certificats SSL à votre site Web est la meilleure ( voire seule ) manière de le sécuriser. Cela vous permet de transposer votre site web de la version HTTP en HTTPS.
Néanmoins, c’est une action qui entraîne l’existence de pages en double de votre site Web si vous n’effectuez pas des redirections.
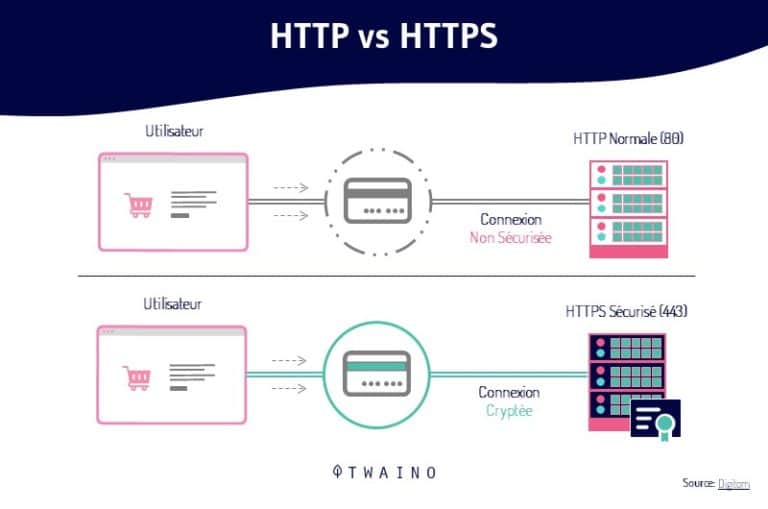
De même, étant donné que le contenu de votre site Web est accessible depuis les URLs avec ‘’WWW’’ et sans ‘’WWW’’, la duplication devient inévitable.
Les URL suivantes mènent toutes à la même page, mais seraient considérées comme des URL complètement différentes pour les robots des moteurs de recherche :
Il est donc à noter que cette situation est la cause la plus courante du problème de duplication.
2.1.2. Contenu scrappé ou copié
Lorsque d’autres sites Web « volent » du contenu sur un autre site, on parle de scraping de contenu. Si Google ou d’autres moteurs de recherche ne parviennent pas à identifier la version originale, ils peuvent finir par classer la page qui a été copiée à partir de votre site.
Ce type de duplication se produit souvent pour les sites qui ont des produits répertoriés avec des descriptions de fabricants.
Si le même produit est vendu sur plusieurs sites et que tous ces sites utilisent les descriptions du fabricant, le contenu dupliqué peut être trouvé sur plusieurs pages sur différents sites.
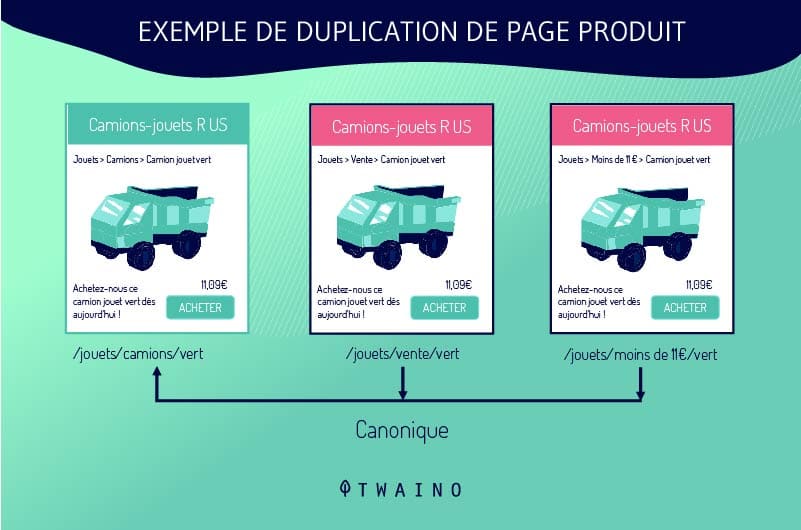
2.1.3. Variantes d’URL
Des variations dans les URL peuvent se produire à partir :
- Des ID de session ;
- Des paramètres de requête et des majuscules.
Lorsqu’une URL utilise des paramètres qui ne modifient pas le contenu de la page, elle peut finir par créer une page dupliquée.
Les identifiants (ID) de session fonctionnent de la même manière. Afin de garder une trace des visiteurs sur votre site, vous pouvez utiliser les identifiants de session pour savoir ce qu’a fait l’utilisateur lors de son parcours sur le site et où il est allé.
Pour ce faire, l’ID de session est ajoutée à l’URL de chaque page sur laquelle ils cliquent.
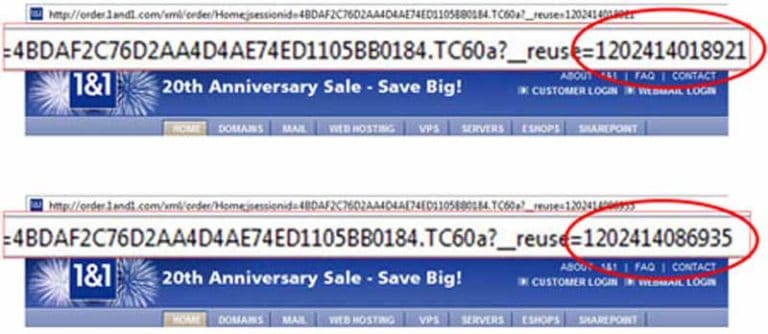
Source : Polepositionmarketing
Par conséquent, l’ID de session ajoutée dans ce cas crée une nouvelle URL vers la même page et est donc considéré comme un contenu en double.
Les majuscules ne sont souvent pas ajoutées intentionnellement, mais il est important de vous assurer que vos URL sont cohérentes et utilisent des lettres minuscules.
Par exemple, twaino.com/blog et twaino.com/Blog seraient considérés comme des pages dupliquées.
Maintenant que vous avez une parfaite connaissance de quelques causes de la duplication de contenu, passons à leur détection.
2.2. Comment repérer les contenus dupliqués ?
Dans cette section, nous allons d’abord voir les manières gratuites de trouver les contenus doubles, ensuite les outils de détection.
2.2.1. Les manières gratuites de récupérer du contenu dupliqué
Voici quelques façons gratuites qui vous permettront :
- De trouver le duplicate contente ;
- De suivre quelles pages ont plusieurs URL ;
- Et de découvrir quels problèmes entraînent l’apparition de doublons sur votre site.
2.2.1.1. Google Search Console
Google Search Console est un puissant outil gratuit à votre disposition. La configuration de votre console vous aidera à avoir une visibilité sur les performances de vos pages Web dans les résultats de recherche.
À l’aide de l’onglet Couverture sous Index, vous pouvez trouver les URL susceptibles de provoquer des problèmes de contenu en double.
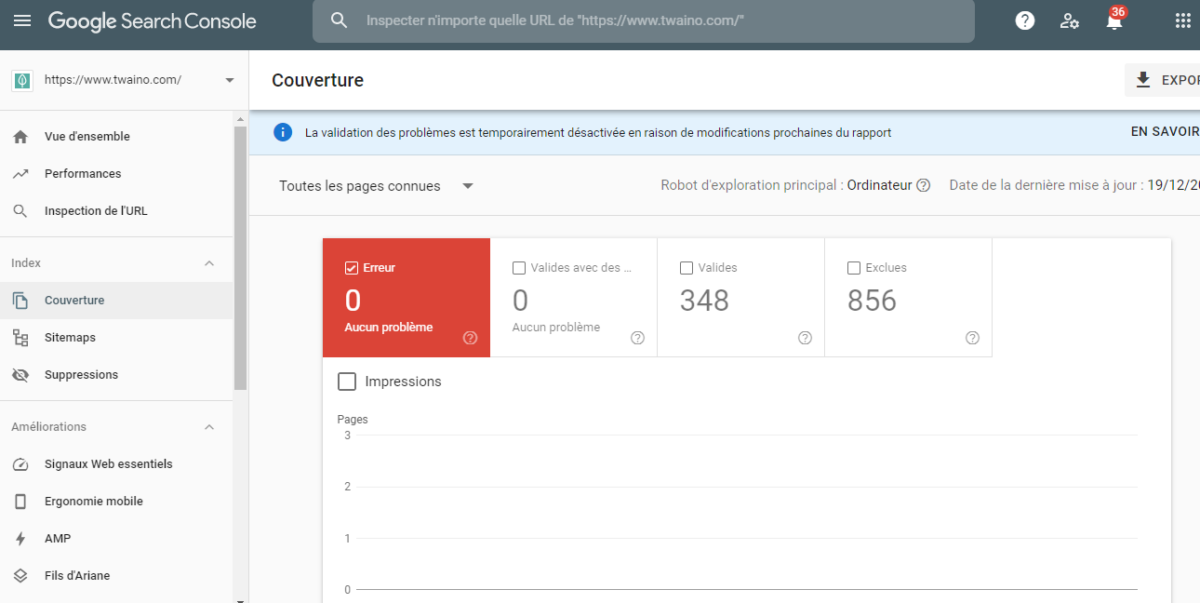
Recherchez les problèmes les plus courants tels que :
- Versions HTTP et HTTPS de la même URL ;
- Versions www et non www de la même URL ;
- URL avec et sans barre oblique « / » ;
- URL avec et sans paramètres de requête ;
- URL avec et sans majuscules ;
- Requêtes à longue traîne avec classement sur plusieurs pages.
Gardez une trace des URL que vous découvrez avec des problèmes de duplication afin de les revoir.
2.2.2.2. Vérificateur de contenu en double
SEO Review Tools a créé ce vérificateur de duplicate contente gratuit pour aider les sites Web à lutter contre les vols de contenu. En entrant votre URL dans leur outil de vérification, vous pouvez obtenir un aperçu des URL externes et internes qui dupliquent l’URL entrée.
Voici ce qui a été trouvé lorsque j’ai branché « https://www.twaino.com/ » dans le vérificateur :
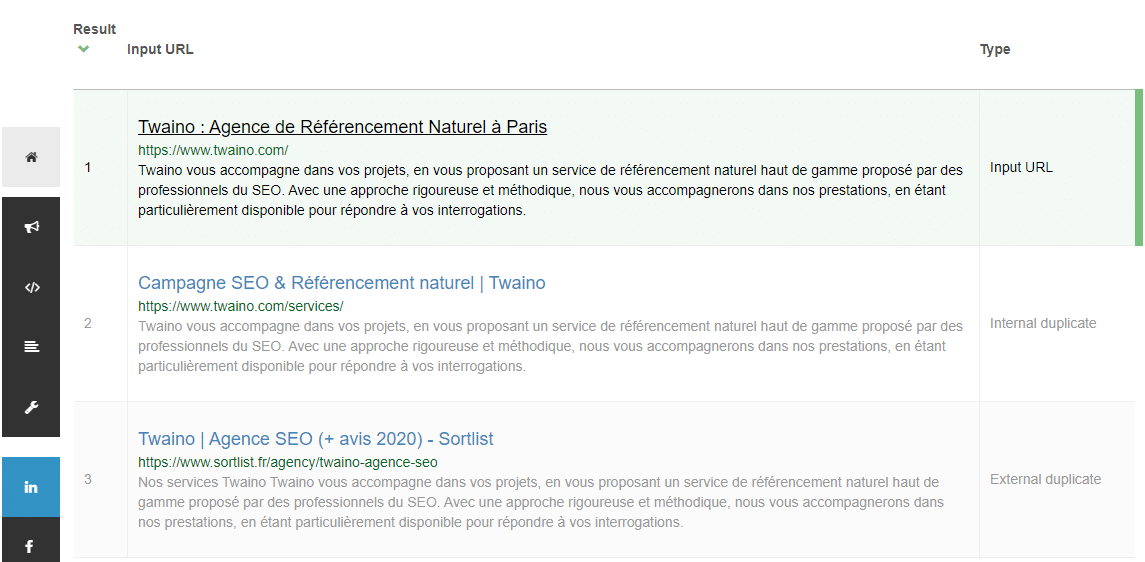
La découverte du duplicate content externe est très importante. Comme rappel, un contenu externe en double se produit lorsqu’un autre vole le contenu de votre site.
Une fois découverte, vous pouvez soumettre une demande de suppression à Google et retirer la page dupliquée.
2.2.2. Outil pour trouver du contenu en double
Voici un aperçu des principaux outils, gratuits et payants, pour détecter le duplicate content interne et externe.
2.2.2.1. Copyscape
Lancé en 2004, Copyscape est l’outil le plus connu pour lutter contre les tentatives de plagiat et de vol de contenu. Cet outil offre un service gratuit et payant.
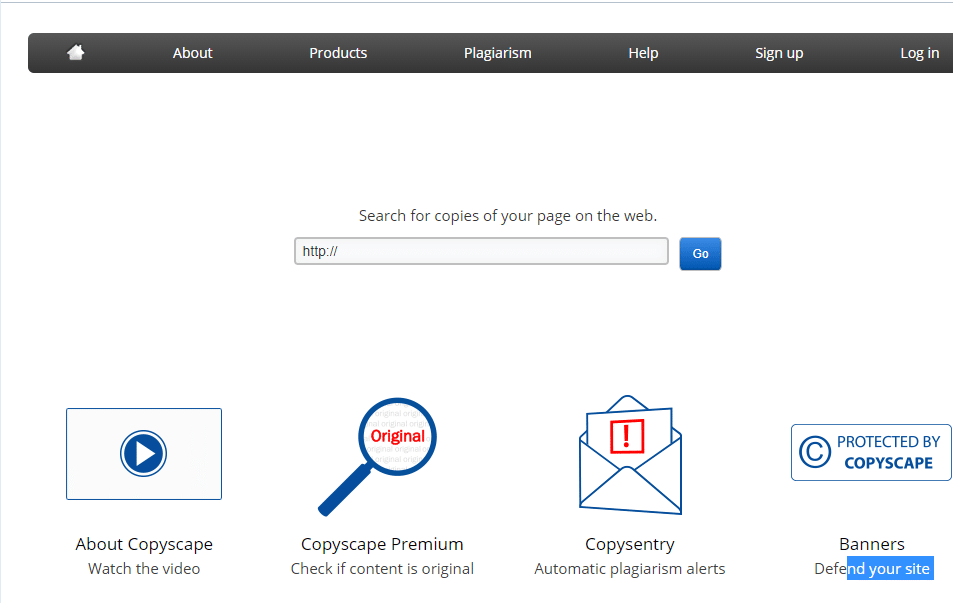
Il n’est pas obligatoire de s’inscrire pour utiliser la version gratuite, il suffit de saisir l’URL de la page à vérifier et de cliquer sur ‘’Go’’.
Mais l’insuffisance de cet outil dans sa version gratuite est qu’il ne peut pas reconnaître les utilisateurs, étant donné qu’il n’est pas obligatoire de s’inscrire avant l’utilisation.
Par conséquent, vous n’aurez pas de résultats si quelqu’un avait déjà fait la même recherche.
La version payante de cet outil permet :
- De saisir le texte à vérifier ;
- De lancer la recherche sur plus de 10 000 pages ;
- D’exclure certains domaines de la recherche.
Le coût est de 0,05 USD par recherche.
2.2.2.2 Dupli Checker
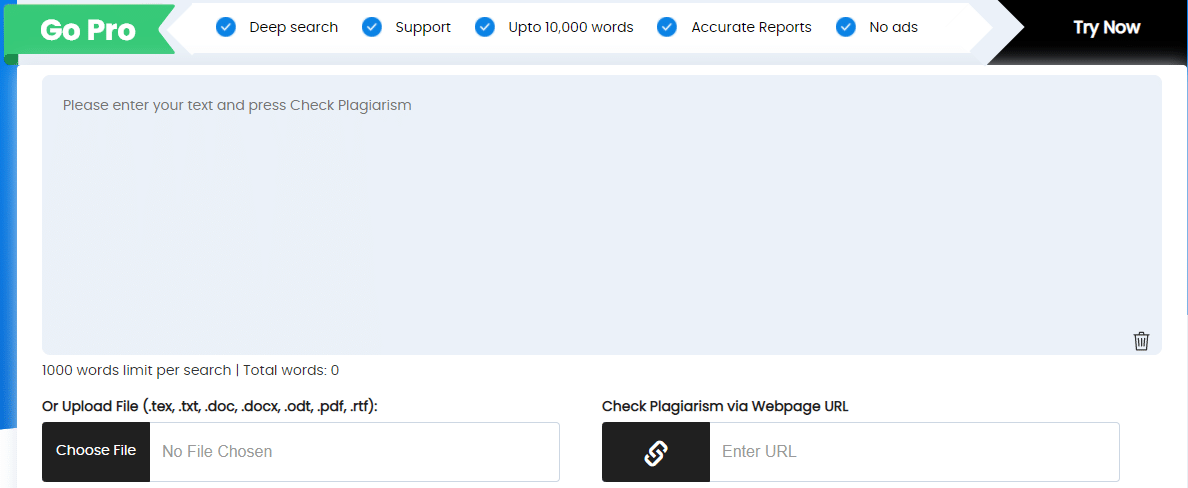
Dupli Checker vous permet de vérifier le texte saisi manuellement ou chargé à partir d’un fichier. Il est alors possible de faire une comparaison avec les résultats détectés, en découvrant le pourcentage du même texte.
2.2.2.3. Plagiarisma
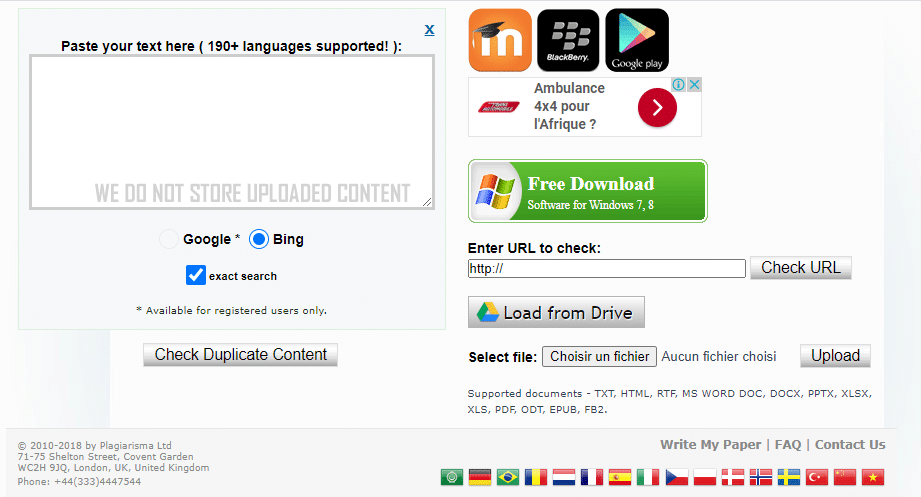
Plagiarisma vous permet de vérifier uniquement Bing en version gratuite. Il suffit de coller le texte à vérifier ou l’URL de la page pour lancer la vérification.
Il existe une version payante qui donne accès à des fonctions supplémentaires dont le coût est de 0,05 $ par recherche.
2.2.2.4. Plagium
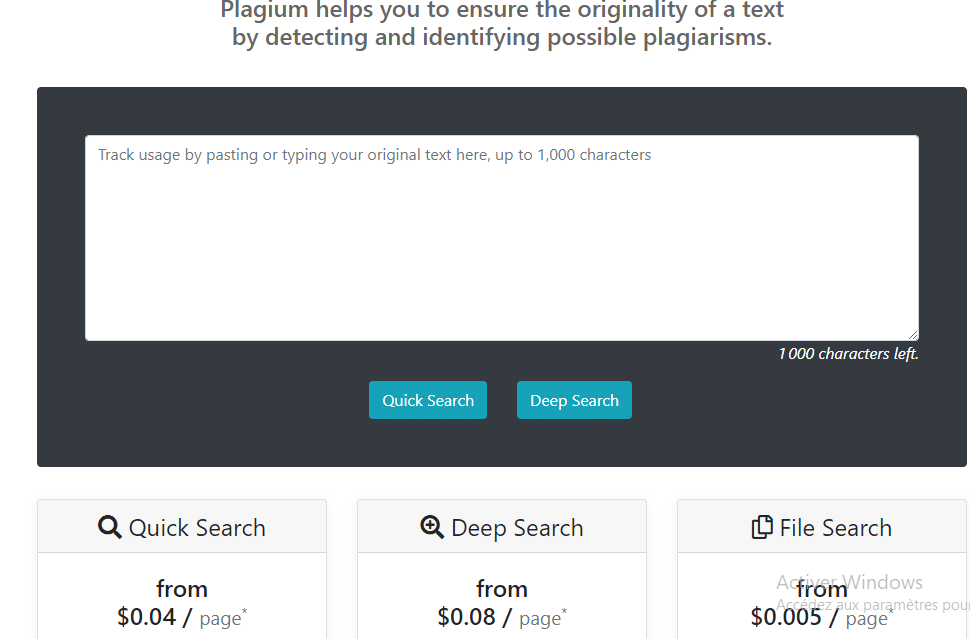
Plagium a deux versions : gratuite et payante. Le premier qui offre un nombre limité de recherches et ne fonctionne qu’en entrant le texte que vous souhaitez vérifier.
Le second a un coût de 0,07 $ par recherche et permet d’obtenir un plus grand nombre de résultats, puisqu’une recherche plus approfondie est effectuée. Grâce à la version payante, vous pouvez également vérifier les documents au format Word ou PDF.
2.2.2.5. PlagScan
PlagScan est un service très complet, mais payant, avec des forfaits allant à 4,99 $ pour 5000 recherches de mots.
En plus d’identifier les pages contenant du texte en double, vous pouvez également voir où il se trouve et comparer les différentes pages.
2.2.2.6. Quetext
Il serait presque impossible de faire une liste des outils de détection de plagiat sans mentionner Quetext, qui a une popularité importante.
C’est un outil bien élaboré et efficace pour détecter des pages web avec des contenus similaires au vôtre.
Vous pouvez également sélectionner l’option ‘’ calculer le score de similarité’’ pour obtenir des résultats plus précis.
Une fois que les doublons sur votre site sont détectés, il vous sera donc facile de les supprimer.
Chapitre 3 : Comment supprimer ou empêcher le contenu en double ?










La suppression du contenu en double vous aidera à vous assurer que la bonne page est accessible et indexée par les robots des moteurs de recherche.
Cependant, vous pouvez ne pas supprimer tous les contenus dupliqués, mais indiquer aux moteurs de recherche la version originale à indexer.
Voici comment vous pouvez faire :
3.1. Rel = balise « canonique »
C’est grâce à l’attribut Rel = balise canonique que les robots des moteurs de recherche reconnaissent la version dupliqué de l’URL d’une page.
Les moteurs de recherche enverront ensuite tous les liens et la puissance de classement à l’URL spécifiée, car ils la considéreront comme la version originale.
L’utilisation de la balise rel = canonical ne supprimera pas la page dupliquée des résultats de recherche. Cela fait tout simplement connaître aux robots des moteurs de recherches la page originale qui doit en temps réel bénéficier de toute équité de lien.
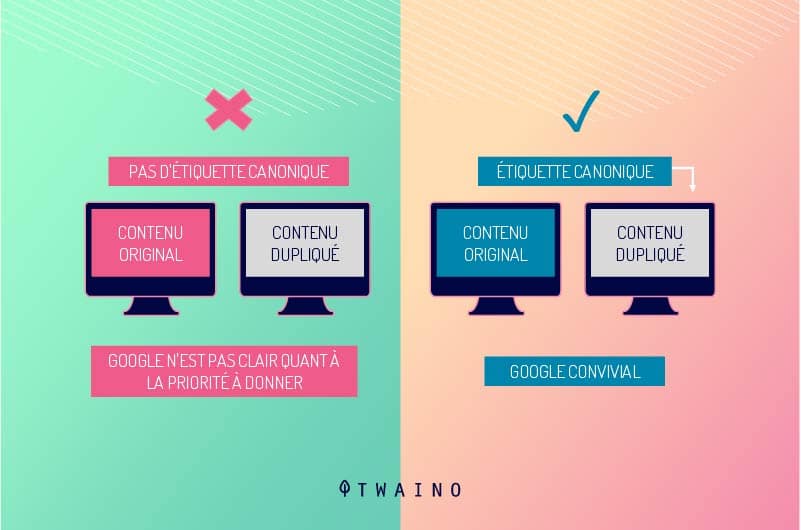
Ces balises Rel = canonical sont utiles lorsque la version dupliquée n’a pas besoin d’être supprimée, comme les URL avec des paramètres ou des barres obliques de fin.
3.2. Redirections 301
L’utilisation d’une redirection 301 est la meilleure option si vous ne souhaitez pas que la page dupliquée soit accessible.
Lorsque vous enclenchez une redirection 301, cela indique au robot d’exploration du moteur de recherche la page destinataire de tout le trafic et les valeurs de référencement.

Lorsque vous décidez de la page à conserver et les pages à rediriger, recherchez la page la plus performante et la plus optimisée.
Lorsque vous combinez plusieurs pages qui se disputent des positions de classement en un seul contenu, vous créerez une page plus forte et plus pertinente que les moteurs de recherche ainsi que les utilisateurs préféreront.
3.3. Robots Meta Noindex
La balise noindex est un extrait de code que vous ajoutez dans l’en-tête HTML de la page que vous souhaitez exclure des index des moteurs de recherche.
Lorsque vous ajoutez le code « content = noindex, follow», vous indiquez aux moteurs de recherche d’explorer les liens sur la page, mais cela les empêche d’ajouter ce contenu à leurs index.

La balise noindex est également utile dans la gestion du duplicate content de pagination. La pagination se produit lorsque le contenu s’étend sur plusieurs pages, ce qui entraîne plusieurs URL.
3.4. Balise canonique auto-référentielle
Pour éviter le scraping de contenu, vous pouvez ajouter la balise meta rel = canonical qui pointe vers l’URL sur laquelle se trouve déjà la page, cela crée une page auto-canonique.
L’ajout de cette balise indiquera aux moteurs de recherche que la page actuelle est l’original.
Lorsqu’un site est copié, le code HTML est extrait du contenu d’origine et ajouté à une URL différente.
Si la balise canonical est incluse dans le code HTML, elle sera probablement également copiée sur le site dupliqué, préservant ainsi la page d’origine comme version canonique.
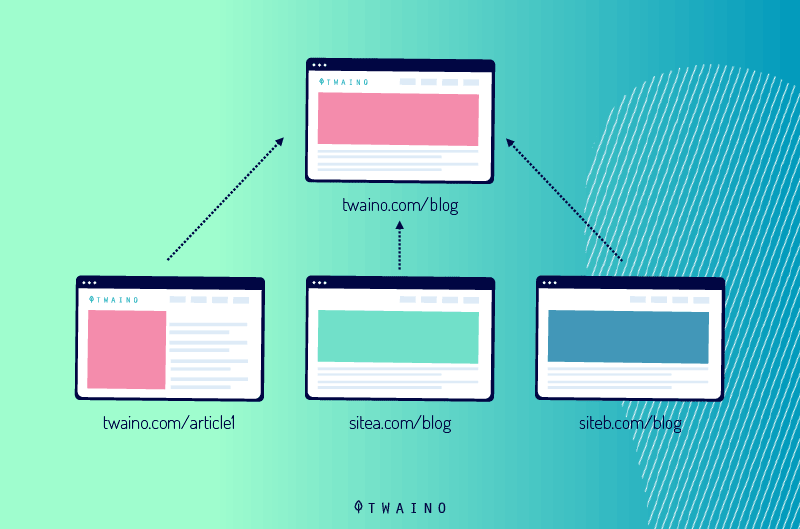
Il est important de noter qu’il s’agit d’une protection supplémentaire qui ne fonctionnera que si les scrapers de texte copient cette partie du code HTML.
Chapitre 4 : Autres questions posées sur le contenu dupliqué
4.1. Qu’est-ce que le duplicate content ?
On parle de duplicate content lorsqu’il y a deux ou plusieurs contenus identiques ou similaires à l’interne ou à l’externe d’un site Web.
4.2. À quel point le contenu dupliqué est-il mauvais pour le référencement ?
Le duplicate content est mauvais pour deux principales raisons :
Lorsqu’il existe plusieurs versions de contenu disponibles, cela réduit les performances de toutes les versions du contenu, car elles sont en concurrence les unes avec les autres.
Il est également difficile pour les moteurs de recherche de déterminer la version à indexer, puis de l’afficher dans leurs résultats de recherche.
4.3. Quels sont les différents types de contenu dupliqué ?
Il existe deux types de doublons :
- Le contenu en double interne se produit lorsqu’un domaine crée du contenu en double via plusieurs URL internes (sur le même site Web).
- Le contenu en double externe, également appelé doublons interdomaines, se produit lorsque deux ou plusieurs domaines différents ont la même copie de page indexée par les moteurs de recherche.
La duplication externe et interne peut se produire sous forme de doublons exacts ou de quasi-doublons.
4.4. Quels sont les risques du contenu dupliqué pour le SEO ?
Techniquement, le contenu dupliqué peut toujours avoir un impact sur le classement des moteurs de recherche. Lorsqu’il y a plus d’un contenu très similaire, les moteurs de recherche ont du mal à essayer de déchiffrer la meilleure version.
Parmi les problèmes que peut rencontrer les sites web liés à la duplication de contenu, il y a : Difficultés de classement dans les résultats de recherche, diminution du trafic organique, etc.
4.5. Comment éviter le contenu dupliqué sur son site ?
Pour éviter le duplicate content, vous avez deux possibilités :
- Utiliser GSC pour voir les URL avec des contenus dupliqués sur votre site ;
- Utiliser un outil payant de détection de plagiat.
4.6. Qu’est-ce que le Copier-coller en rédaction web ?
Le copie-coller est une pratique qui consiste à copier le texte intégral d’une page interne ou externe d’un site pour produire un nouveau contenu. Cette pratique est également qualifiée de plagiat et représente une grande menace pour le propriétaire du site web.
4.7. Google sanctionne-il le contenu dupliqué ?
OUI ! La copie de la production d’autrui sans une prise préalable de précautions peut non seulement agir sur le positionnement SEO de votre site, mais peut également causer sa désindexation de l’index de Google.
En résumé
Même si le contenu dupliqué n’est souvent pas créé intentionnellement, cela peut indirectement nuire à votre valeur SEO et à votre potentiel de classement, s’il est laissé sans surveillance.
Lorsque vous savez comment gérer les doublons sur votre site web, les robots des moteurs de recherche auront plus de facilité à jouer leurs rôles d’indexation et de positionnement de votre site web.
C’est pour cela que nous avons pris le temps de détailler chacun des points annoncés dans l’introduction de cet article.
A vous de voir dans quelle mesure ces différentes notions pourront vous permettre d’optimiser efficacement votre site web.
Et si vous avez d’autres astuces pour lutter contre le duplicate content, n’hésitez pas à les partager avec nous dans les commentaires.
A bientôt !


