
On parle de DUST ou des URL Différentes avec du Texte Similaire lorsque plusieurs URL d’un site renvoient à une page du même site. Il s’agit souvent d’un contenu qui est accessible à divers endroits sur un même domaine ou par divers moyens. Encore appelé duplication d’URL, le DUST sème la confusion au niveau des moteurs de recherche lorsque les robots doivent explorer et indexer les URL qui sont en doublon. Le DUST réduit ainsi l’efficacité de l’exploration et dilue l’autorité de la page principale.
La création de contenu est la principale responsabilité des webmasters lorsqu’il s’agit de référencer un site web. Bien que l’idéal soit de créer des contenus uniques, il est difficile d’y parvenir sans compter les racleurs de contenus qui viendront dupliquer le vôtre.
Les contenus dupliqués représentent entre 25 à 30 % des contenus du web et ne résultent pas tous d’intention malhonnête. Ils peuvent être aussi créés de manière involontaire sur un site sans que les webmasters ne s’en rendent compte.
C’est le cas des URL Différentes avec du Texte Similaire (DUST) où une URL peut être dupliquée des centaines de fois. La grande majorité des sites web sont confrontés à ce problème et ses causes sont nombreuses.
Mais concrètement ;
- En quoi consiste le DUST ?
- Comment les URL de types DUST apparaissent-elles sur un site ?
- Quels sont les potentiels problèmes que pose le DUST ?
- Comment corriger les problèmes liés au DUST ?
À travers cet article, je vais apporter des réponses explicites à ces différentes interrogations afin de démystifier le DUST. Nous découvrons également comment empêcher ce problème de se produire sur un site.
Suivez donc !
Chapitre 1 : En quoi consiste le DUST et quels problèmes pose-t-il en termes de référencement ?
Les contenus dupliqués font partie du top 5 des problèmes de référencement auxquels les sites sont confrontés et le DUST est une forme de ce type de contenus parmi tant d’autres.
Ce chapitre aborde la définition du DUST et les problèmes auxquels il expose un site en termes de référencement.
1.1. Le DUST : De quoi s’agit-il ?
Les contenus dupliqués ou duplicate content sont courants sur le web et Google les définit comme des contenus d’un même site ou d’autres sites qui correspondent à un autre contenu ou qui sont quasiment similaires.
À travers cette définition, on note que la duplication de contenu se produit à deux niveaux : sur un même domaine ou entre plusieurs domaines.

Lorsqu’elle se produit sur un même site, elle peut se présenter sous la forme d’un contenu qui apparaît dans différentes pages d’un domaine ou une page qui est accessible à plusieurs URL.
Dans ce dernier cas, le duplicate content est appelé DUST. Alors que les autres formes de contenu dupliqué sont liées à la création de contenu, le DUST est plutôt le résultat de la duplication d’URL.

Cette duplication d’URL est très fréquente et provient souvent d’un problème technique auquel tous les sites web peuvent faire face à un moment donné. Les URL suivantes renvoient toutes à un même site et constituent un exemple de DUST.
- www.votresite.com/ ;
- votresite.com ;
- http://votresite.com ;
- http://votresite.com/ ;
- https://www.votresite.com ;
- https://votresite.com.
Bien que ces URL semblent être les mêmes et ciblent une même page, les syntaxes ne sont pas les mêmes et cela peut être source de problèmes pour un site web
1.2. Pourquoi le DUST ou l’URL dupliquée pose-t-il de problème ?
Contrairement aux autres formes de duplicate content, le DUST ne nuit pas directement au référencement d’un site web. En effet, Google comprend parfaitement que cette duplication n’est pas malveillante.

Le DUST pose cependant trois principaux problèmes avec les moteurs de recherche. Ces derniers n’arrivent pas :
- À identifier lequel des URLs inclure ou exclure de leur index ;
- À connaître l’URL auquel attribuer les mesures de liens notamment la confiance, l’autorité, l’équité…
- Identifier les ou l’URL qu’ils doivent classer pour les résultats de recherche.
Pour comprendre ces problèmes, nous allons nous intéresser au fonctionnement des moteurs de recherche. Ils arrivent à afficher les résultats de recherche grâce à trois principales fonctions à savoir :
- L’exploration ;
- L’indexation ;
- Classement.

L’exploration des sites web est le processus par lequel les moteurs de recherches découvrent les nouveaux contenus du web et ceux qui sont mis à jour récemment. Ils envoient des robots appelés araignées qui se déplacent de sur un site de URL en URL.
Lorsque plusieurs URL mènent à une même page, les robots les considèrent comme des URL différentes et effectuent l’exploration pour chacune d’elles. Ils découvrent ensuite que les contenus de ces différentes URL sont les mêmes et les traitent comme du contenu dupliqué.
Au cours de l’exploration, les robots sont capables d’ajouter les nouvelles ressources intéressantes qu’ils trouvent dans l’index, une énorme base de données d’URL.
Bien que cela puisse arriver, les robots évitent d’indexer une même page plusieurs fois et s’attèlent à indexer seulement les pages qui proposent des contenus uniques. Ainsi, les araignées peuvent être amenées à faire des choix quant aux URL qui seront indexées.

Ils peuvent ainsi inclure dans l’index une quelconque URL qui peut s’avérer ne pas être la bonne ou celle que vous souhaitez indexer.
Par ailleurs, c’est parmi les contenus indexés que les moteurs de recherche choisissent les contenus pertinents lorsqu’un internaute effectue une requête. Il est donc évident qu’une page qui n’existe pas dans l’index ne peut pas apparaître dans les résultats de recherche.
1.3. Comment le DUST peut-il nuire à votre référencement ?
Les URL dupliquées peuvent nuire au référencement d’un site de plusieurs manières.
1.3.1. Réduire l’efficacité de l’exploration
Le fait que les URL dupliquées renvoient toutes à une même page et que les robots vont quand même explorer chacune d’elles peut réduire l’efficacité de l’exploration des robots.
En effet, Google alloue un budget d’exploration à tous les sites. Ce budget représente le nombre d’URL que les robots explorateurs peuvent suivre sur un site. Plus les URL sont nombreuses, plus le budget d’exploration est susceptible d’être épuisé.

Cela dit, les robots ne seront pas en mesure d’explorer toutes les pages lorsque le budget est épuisé et il peut arriver qu’ils n’arrivent pas à explorer toutes les pages pertinentes du site.
Il est donc crucial que les propriétaires de sites œuvrent pour l’optimisation du budget d’exploration afin de permettre aux robots de suivre l’ensemble des URL pertinentes.
1.3.2. Perte de trafic et dilution de l’équité
Lorsque les moteurs de recherche indexent parmi les URL dupliquées une URL dont la structure est bizarre, les internautes peuvent avoir des doutes lorsqu’elle apparaît dans les résultats de recherche. Cela peut faire perdre du trafic malgré qu’il soit bien classé.
Il peut aussi arriver que les robots indexent plusieurs URL parmi les doublons. Même dans ce cas, les URL sont considérées différemment. Chacune d’elles obtient des autorités et des classements différents.

Cet état de choses dilue la visibilité de tous les doublons. Cela résulte du fait que chacune des URL dupliquées peut capter des backlinks alors que ces liens peuvent tous se pointer vers l’URL principale.
1.4. Comment les URL dupliquées apparaissent-elles ?
Les webmasters ne dupliquent pas les URL intentionnellement. Le DUST apparaît souvent lorsque les sites utilisent un système qui crée plusieurs versions de la même page. Cette situation est fréquente sur les sites d’e-commerce notamment sur les fiches de produits.
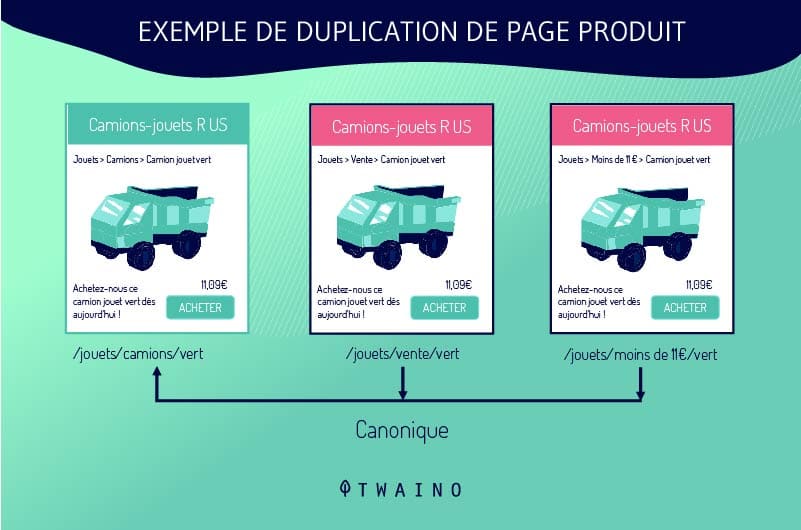
Les fiches de produits sont configurées d’une manière qui permet aux clients de choisir entre plusieurs tailles ou couleurs tout en restant sur la même page. Le système de gestion de contenus génère donc plusieurs URL de type DUST qui renvoient à une seule page.
Supposons qu’un site propose une chemise de couleur bleue de trois déférentes tailles, le système peut générer les URL suivantes :
- boutiqueenligne.com/chemisebleue-A ;
- boutiqueenligne.com/chemisebleue-B ;
- boutiqueenligne.com/chemisebleue-C.
Les URL dupliquées résultent aussi des filtres que les sites proposent pour faciliter la recherche à leurs visiteurs. Les différentes combinaisons génèrent toutes des liens de types DUST que les moteurs de recherche considèrent malheureusement différemment.
Les sites créent aussi des URL en double lorsqu’ils publient une version imprimable d’une page. De la même manière, les URL dupliquées proviennent également :
- Des URL dynamiques ;
- Les versions anciennes et oubliées d’une page ;
- Les ID de session.
Notez aussi que les URL sont sensibles à la présence ou l’absence de la barre oblique (/) à la fin. Par exemple, Google considéra différemment les URL exemple.com/page/ et exemple.com/page.
Ainsi, ces deux URL seront traitées comme des URL dupliquées malgré qu’elles permettent d’accéder à un même contenu.
Chapitre 2 : Comment identifier les URL de type DUST et par quels moyens les corriger ?
La correction des URL de type DUST peut avoir des effets significatifs sur le référencement d’un site web. Nous découvrons dans ce chapitre comment détecter ces URL et les différents moyens par lesquels elles peuvent être traitées.
2.1. Comment trouver les URL dupliquées ?
Il est essentiel de détecter les URL de type DUST pour pouvoir corriger ce problème. Il existe heureusement des astuces et des outils en ligne qui permettent de vérifier les URL dupliquées sur un domaine.
2.1.1. Les outils de vérification d’URL dupliquée
Parmi les outils de vérifications d’URL dupliquées, je vous propose Seo Review Tools. Il suffit d’inscrire l’URL ciblée dans la barre réservée à cet effet et de cliquer sur « Effectuer la vérification ». L’outil vous indique le nombre de doublons de l’URL que vous avez renseignée.
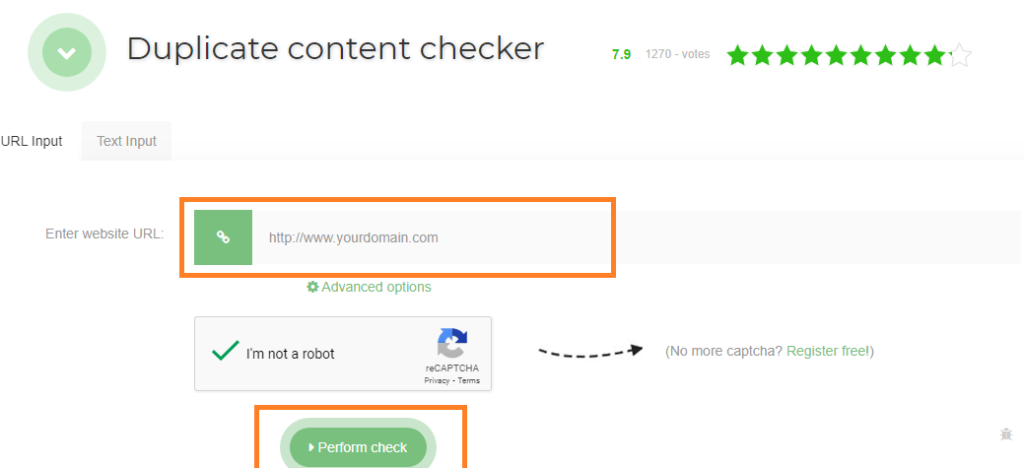
Siteliner est aussi un outil puissant pour trouver les URL dupliquées sur un domaine. Il examine votre domaine et vous montre un rapport des liens dupliqués de votre site.
Pour utiliser cet outil, vous n’aurez qu’à inscrire votre domaine dans la barre de recherche. Lorsque Siteliner vous montre l’analyse de votre site, cliquez sur « content duplicate » pour afficher les URL dupliquées.
2.1.2. Utilisation de l’opérateur de recherche site:exemple.com intitle :
Vous pouvez également vérifier les URL de votre site qui sont doubles à l’aide des opérateurs de recherche site:example.com intitle : “votre mot-clé”. Google vous montre les URL de votre domaine (example.com) qui contiennent le mot-clé ciblé.
Vous n’aurez qu’à consulter les URL affichées par Google pour voir les URL qui renvoient à la même page. Maintenant que vous pouvez trouver les doublons d’URL sur votre site, passons aux actions correctives que vous pouvez apporter.
2.2. Comment corriger les URL de type DUST ?
2.2.1. La redirection 301
La redirection 301 est un moyen qui consiste à envoyer les utilisateurs et les moteurs de recherche vers une adresse différente de ce qu’il demande de façon permanente. Dans le cas des URL de types DUST, elle consiste à rediriger les doublons vers l’URL originale.
De cette manière, ces différentes URL qui sont susceptibles d’être classées différemment sont regroupées en une et cessent d’être en concurrence. De plus, toutes les URL transmettent la totalité de leur équipée à l’URL principale.

Cette URL bénéficie ainsi de la puissance de référencement de ses doublons. Ceci aura naturellement un impact significatif sur le référencement de la page concernée. Notez cependant que la redirection 301 ne supprime pas les doublons de DUST.
2.2.2. La balise rel=canonical
La balise rel=canonical reste l’un des meilleurs moyens pour transférer le potentiel de référencement d’une page dupliquée vers une autre page. C’est une balise HTML qui indique tout simplement aux moteurs de recherche l’URL qu’ils doivent ajouter à leurs indexes.

Google définit l’URL canonique comme l’URL la plus représentative d’un groupe de contenu dupliqué. Cette URL est celle que les robots explorateurs vont suivre régulièrement afin d’optimiser le budget d’exploration d’un site. Les autres seront consultés moins fréquemment.
Google et les autres moteurs de recherche attribuent tout le potentiel de référencement des doublons d’URL à l’URL canonique. La balise rel=canonical s’ajoute à l’entête d’une page HTML.
Les moteurs de recherche considèrent les autres pages comme étant des duplicatas de l’URL canonique et ne les font pas disparaître. Ceci est très avantageux d’autant que vous ne souhaitez certainement pas que tous les doublons soient supprimés.
2.2.3. Utilisation de méta robots
L’utilisation des méta robots est à la fois simple et efficace quand il s’agit d’empêcher des pages d’apparaître dans les résultats de recherche. Elle consiste à ajouter au code HTML d’une page les balises Noindex et Nofollow.

La balise Noindex indique aux moteurs de recherche que vous ne désirez pas qu’ils ajoutent une URL à leurs index et conséquemment de ne pas l’afficher dans les résultats de recherche.
Il suffit donc d’ajouter la balise Noindex aux URL dupliquées pour les empêcher de concurrencer l’URL principale.
La balise Nofollow quant à elle indique à Google de ne pas suivre un lien et de ne pas transmettre son autorité aux pages auxquelles elle renvoie. Ainsi, les araignées vont ignorer tous les liens qui comportent la balise Nofollow.
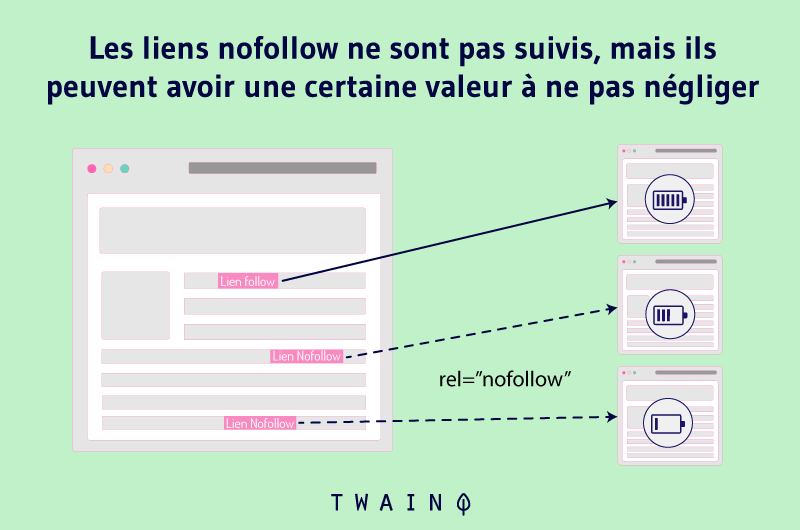
L’ajout de cette balise aux URL dupliquées peut donc vous aider à corriger les problèmes liés à la duplication d’URL.
2.2.4. Réglage dans Google Search Console
L’insertion des balises canoniques et des métas robots à des centaines de pages de type DUST représente souvent un énorme travail. Heureusement, les réglages de Google Search Console peuvent être une partie de solution aux URL de type DUST.
2.2.4.1. La définition de la version d’URL de votre site
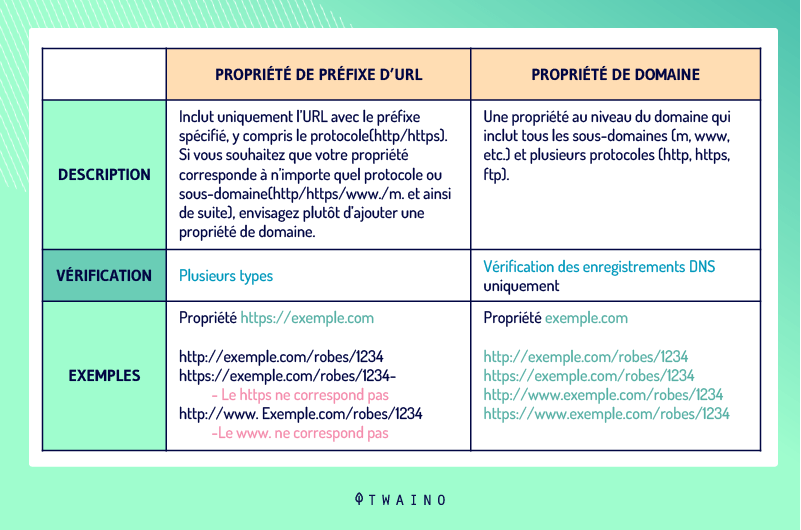
La définition de l’adresse d’un domaine peut aussi aider à résoudre les problèmes liés au DUST. En effet, les webmasters peuvent définir dans cet outil une préférence pour leur domaine et préciser si les araignées doivent explorer certaines URL.
Au lieu de http://www.votresite.com, ils peuvent préciser que c’est http://votresite.com l’adresse de leur domaine. Remarquez l’absence des www et il en est de même pour les protocoles HTTP et HTTPS avec l’absence de S.
Pour procéder à la définition de la version de l’URL de votre site, allez dans Google Search Console et choisissez « Ajouter propriété ».
2.2.4.2. La gestion des paramètres d’URL
La configuration des paramètres d’URL dans Google Search Console permet d’indiquer les paramètres d’URL qu’il doit ignorer. Cependant, vous devez être prudent pour ne pas ajouter des URL incorrectes au risque de porter préjudice à votre site.
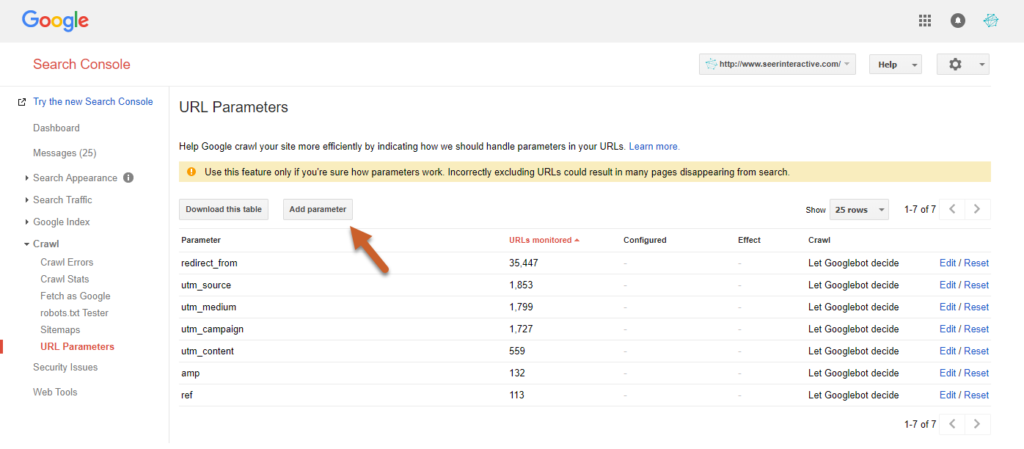
Pour le faire, cliquez sur Crawl dans l’outil et cliquez sur « Configurer les paramètres d’URL ». Le bouton “Configurer un paramètre URL” vous permet d’entrer vos paramètres.
Source : seerinteractive
Source : seerinteractive
Afin d’enregistrer le paramètre, sélectionnez si le paramètre modifie ou pas la façon dont le contenu sera vu par les utilisateurs.
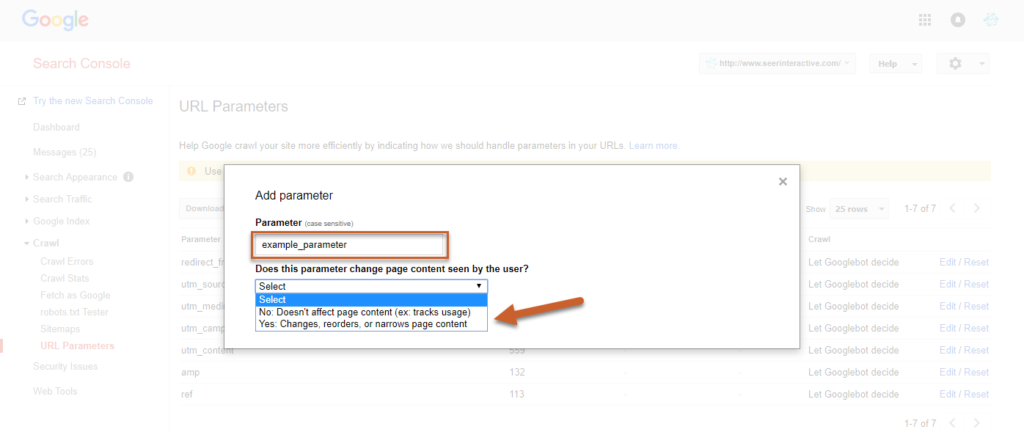
Source : seerinteractive
À ce stade, choisissez OUI pour définir la manière dont le paramètre peut affecter le contenu.
2.2.4.3. La déclaration des URL passives
La gestion des paramètres d’URL permet également de définir certaines URL comme passives afin que les Googlebots les ignorent pendant l’exploration d’un site.
C’est probablement la technique la plus efficace pour supprimer les URL encombrantes des résultats de recherche.
Il est recommandé d’appliquer cette technique de manière temporaire le temps que votre équipe puisse ajouter des balises canoniques et mettre en place la redirection 301 pour les doublons.
Pour déclarer certaines de vos URL passives, vous n’aurez qu’à suivre les mêmes étapes et cliquer sur NON avant d’enregistrer. En conséquence, elles n’apparaîtront plus sur les SERP. Cependant cette technique ne reste pas sans inconvénient.

Contrairement à la balise canonique, la principale URL qui est gardée après la définition des doublons dans les paramètres de Google Search Console ne bénéficie d’aucun avantage de ces dernières en termes de référencement.
Toutefois, les problèmes ne se posent pas lorsque les URL marquées passives sont nouvelles ou ont très peu d’autorité de page. Nous vous proposons donc de vérifier l’autorité des pages que vous désirez ajouter dans les paramètres.
Vous pouvez utiliser par exemple l’outil de vérification de Ahrefs pour procéder à cette vérification. Lorsque l’autorité d’une page est élevée, vous ne devez pas marquer son URL comme passive au risque de perdre de précieux avantages SEO.
Chapitre 3 : Autres questions fréquemment posées à propos de DUST
Ce chapitre est consacré aux questions qui sont souvent posées sur les URL de type DUST.
3.1. Comment éviter les doublons d’URL ?
Bien qu’il y ait des URL de type DUST qui sont inévitables dans certains cas, il est possible d’éviter bon nombre des doublons. Les webmasters doivent toujours utiliser un format d’URL cohérents pour l’ensemble des liens internes de leurs domaines.
Par exemple, un webmaster doit définir la version canonique de son site web et s’assurer que toutes les personnes qui ajoutent des liens internes à son site web respectent ce format.
Lorsque la version canonique du site en question est www.example.com/, tous les liens internes doivent aller à http://www.example.com/ plutôt qu’à http://example.com/. La différence fondamentale résulte de la présence de (www) dans la version canonique du site.
3.2. Peut-on utiliser à la fois toutes les stratégies ci-dessus pour le DUST ?
En réalité, il n’y a pas de solution unique pour traiter les URL dupliquées. Les solutions mentionnées précédemment ont leurs avantages et leurs inconvénients. La redirection 301 peut par exemple réduire l’efficacité de l’exploration.
C’est le même principe pour la balise canonique. En effet, les robots explorent quand même les URL dupliquées afin d’identifier l’URL canonique pour l’indexer. Quant aux méta robots, ils ne transmettent pas l’autorité des URL dupliquées à l’URL originale.

En ce qui concerne la déclaration des URL passives dans les paramètres de Google Search Console, elle est spécifique à Google et ne concerne pas les autres moteurs de recherche.
Par conséquent, le problème persiste sur les autres moteurs de recherche comme Bing si ce n’est plus le cas pour Google.
Au vu de tout ceci, il est raisonnable de chercher à utiliser l’ensemble de ces solutions de manière appropriée pour couvrir tous les problèmes potentiels. Cependant, vous devez analyser chacune de ces solutions pour déterminer celles qui répondent au mieux à vos besoins.
3.3. Qu’est-ce que l’URL dynamique
L’utilisation des URL dynamiques est l’une des principales causes du DUST. En général, l’URL dynamique est générée à partir d’une base de données lorsqu’un internaute soumet une requête de recherche.

Les contenus de la page ne changent pas lorsqu’un utilisateur veut choisir une couleur d’un article sur une boutique en ligne par exemple. Les URL dynamiques contient souvent des caractères comme : ?, &, %, +, =, $.
Au contraire, les URL statiques ne changent pas et ne contiennent pas de paramètres d’URL. Ces URL ne posent pas de problème au cours de l’exploration d’un site comme c’est le cas pour les URL dynamiques.
3.4. Qu’est-ce que le paramètre d’URL ?
Les paramètres d’URL sont l’une des causes des URL dupliquées. Encore appelés variables URL, les paramètres URL sont les variables qui viennent après un point d’interrogation dans une URL.
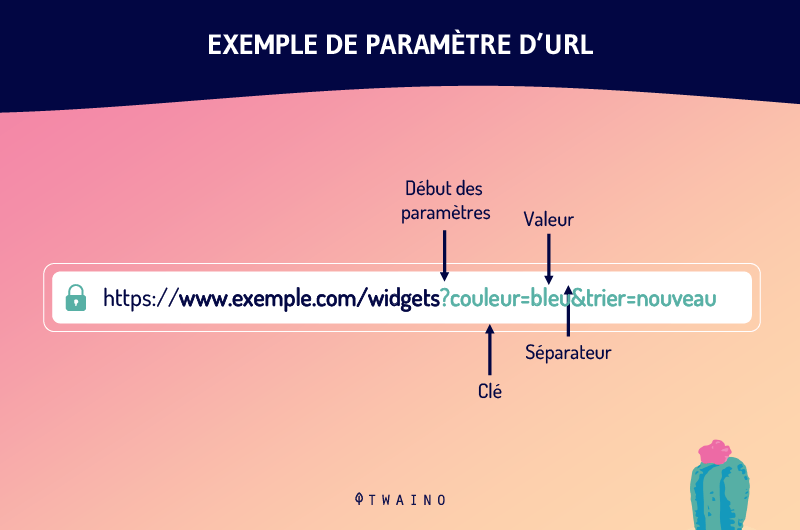
Il s’agit des éléments d’information qui définissent différentes caractéristiques et classifications d’un produit ou d’un service. Ils peuvent déterminer également l’ordre dans lequel les informations s’affichent pour un spectateur.
Les cas d’utilisations les plus courants des paramètres d’URL sont entre autres :
- Filtrage – Par exemple, ? type=taille, colour=reg ou ? price-range=25-40
- Identifier - ? product=big-reg, categoryid=124 ou itemid=24AU
- Traduire – Par exemple, ? lang=fr, ? language=de.
3.5. Qu’est-ce que l’ID de session
Les sites web souhaitent souvent garder en souvenir l’activité des utilisateurs afin de leur permettre d’ajouter des produits dans un panier par exemple. Le moyen pour y arriver est d’attribuer à chacun des visiteurs un identifiant de session.
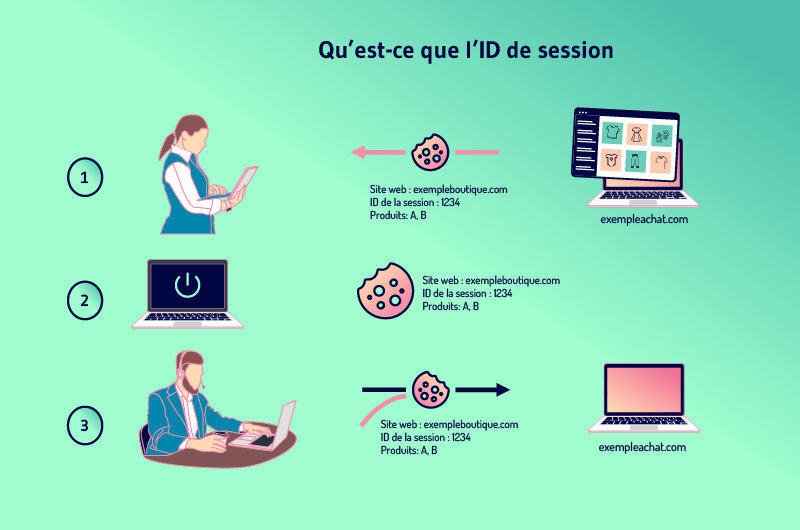
La session n’est rien d’autre que l’historique de ce qu’un internaute fait sur un site et l’ID est spécifique à chaque visiteur. Afin de garder la session lorsqu’un internaute quitte une page pour une autre, les sites web ont besoin de stocker l’ID quelque part.
Pour cela, les sites utilisent généralement des cookies qui stockent l’ID sur l’ordinateur de l’internaute.
Mais lorsqu’un visiteur a désactivé au préalable le stockage des cookies, l’ID de session peut être transféré du serveur au navigateur en tant que paramètre joint à l’URL de la page.
Cela dit, tous les liens internes du site se voient ajouter l’ID de session à son URL. De nouvelles URL sont ainsi créées à mesure que le visiteur visite plusieurs pages. Ces nouvelles URL sont des doublons d’URL principale et créent ainsi le problème de DUST.
3.6. Google pénalise-t-il les URL dupliquées ?
Google ne pénalise ni les contenus dupliqués ni les URL dupliquées et les employés de Google le rappellent à chaque fois. John Muller a par exemple déclaré :
“Nous n’avons pas de pénalité pour contenu dupliqué. Nous ne rétrogradons pas un site pour avoir assez de contenu dupliqué.”
Cependant, Google s’emploie à décourager les duplications qui résultent d’une manipulation et procèdent à des ajustements dans son classement.
Bien qu’on pourrait penser que les pénalités ne concernent pas implicitement les URL de type DUST, ces dernières nuisent au référencement d’un site web comme évoqué précédemment
Conclusion
Somme toute, le DUST est un problème courant que la plupart des sites web rencontrent. C’est un ensemble d’URL qui donne accès à une même page sur un domaine.
Le plus souvent, le DUST ne pose pas de grands problèmes au référencement d’un site. Cependant, les erreurs techniques qui conduisent à la duplication des milliers de pages d’URL épuisent le budget d’exploration d’un site et peuvent impacter sur ses efforts SEO.
Fort heureusement, ces problèmes peuvent être évités et la duplication d’URL peut être corrigée par :
- La redirection 301 ;
- La mise en place de méta robots ;
- La balise rel=canonical
- La définition des URL passives dans les paramètres de Google Searche Console.
La correction des URL de type DUST peut demander assez de temps et une planification minutieuse. Il est donc conseillé au webmaster d’éviter autant que possible les situations d’URL dupliquées.
Et maintenant, dites-nous lequel des moyens cités dans cet article vous a déjà permis de corriger la duplication d’URL.


