
HTTP est l’acronyme de Hypertext Transfer Protocol ou protocole de transfert d’un hypertexte . Il s’agit essentiellement d’un protocole de communication servant de conduite des informations entre le client et un serveur web.

Le protocole HTTP a été inventé avec HTML pour créer le premier navigateur Web interactif basé sur du texte connu sous World Wide Web original.
Aujourd’hui, le protocole HTTP reste l’un des principaux moyens d’utiliser Internet, dont les utilisateurs du net ne peuvent s’en passer.
Si vous êtes un utilisateur d’internet, vous devez absolument prêter attention à cet article qui vous parle de tout ce que vous devez savoir sur le protocole HTTP.
Chapitre 1 : Que signifie le protocole HTTP ?
Parce que le protocole HTTP est l’un des éléments fondamentaux de l’internet, nous allons ensemble parler dans ce chapitre de tout ce que vous devez comprendre sur ce protocole.
1.1. Définition et historique de HTTP
Le protocole HTTP ou Hypertext Transfer Protocol est une technique de codage et de conduite des informations entre un navigateur Web et un serveur Web. HTTP est le principal protocole de transmission d’informations sur Internet.
Le protocole HTTP 0.9 a vu le jour vers la fin des années quatre-vingt, mais doté d’une faible capacité.
La combinaison de cette invention avec le langage HTML et les URL est désormais considérée comme la base de l’initiative mondiale d’information sur le Web ‘’WWW’’.
Cette innovation a été menée dans le monde du web par Tim Berners-Lee au CERN de Genève pour le partage d’informations entre la communauté des physiciens.
Vu les insuffisances du protocole HTTP 0.9, Berners-Lee a pensé aux améliorations en inventant la première version réelle HTTP/1.0 en 1991.
Cette nouvelle œuvre de l’acteur a été proposée en tant que RFC 1945 à l’organisme de réglementation de l’IETF (Internet Engineering Task Force) en 1996.
Avec la diffusion de NCSA Mosaic, un navigateur graphique facile à utiliser, le WWW a connu un succès croissant et certaines limitations de la version 1.0 du protocole sont devenues évidentes, en particulier :
- L’incapacité d’héberger plusieurs sites www sur le même serveur (Ce que l’on appelle hôte virtuel),
- Echec de réutilisation des connexions disponibles,
- L’impuissance du mécanismes de sécurité insuffisants,
- Etc.
Désormais, c’est la nouvelle version HTTP / 1.1 qui a vu le jour. Elle est présentée comme RFC 2068 en 1997 et mise à jour plus tard en 1999 comme décrite par RFC 2616.
1.2. Le fonctionnement du protocole HTTP
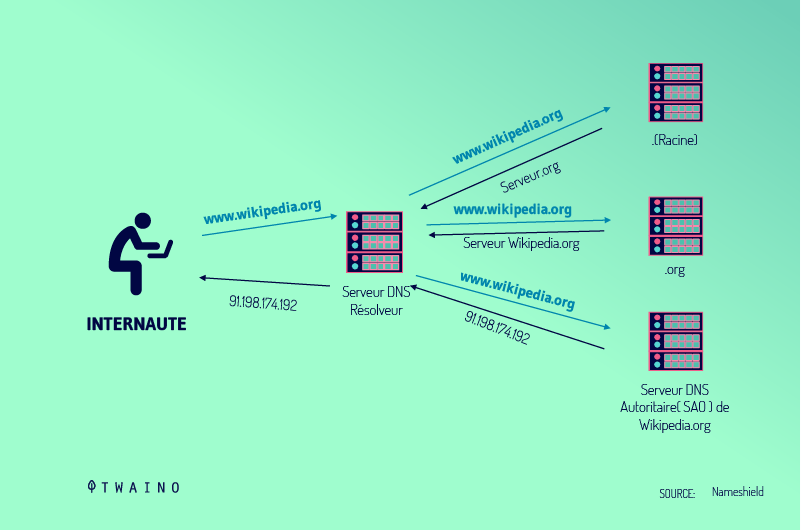
Toutes les fois qu’un utilisateur effectue une demande sur internet, il se sert sans aucun doute du protocole HTTP. Non seulement pour envoyer sa demande au serveur hébergeant la page demandée, mais aussi pour recevoir les données en réponse du serveur.
Cela implique une inévitable présence du protocole HTTP à la fois dans la couche application du client et dans celle du serveur, sinon la communication ne peut avoir lieu.
La demande du client s’effectue via le navigateur qui gère l’ensemble de la communication et renvoie les ressources demandées par l’utilisateur à l’écran. Le navigateur voit une page Web comme un ensemble d’objets liés entre eux par des hyperliens.
Ainsi, une page Web sera sûrement composée d’un corps HTML et d’autres ressources qui pourraient être des scripts, des images, des applets Java, etc.
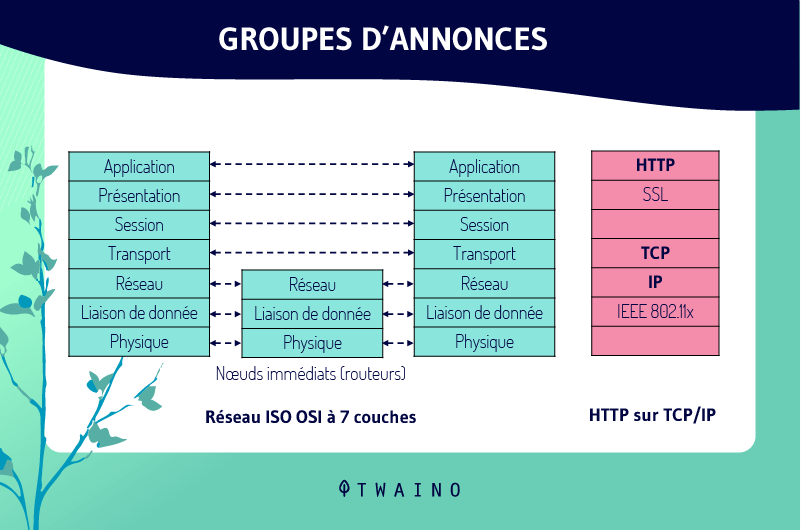
HTTP prend appuie sur le protocole TCP de la couche de transport pour assurer le transfert des données du serveur vers le client.
La principale raison d’utilisation du protocole TCP par le HTTP peut s’expliquer par le transfert des données que cela garantit, contrairement au protocole de transfert UDP.
Bien que l’utilisation de TCP présente un grand avantage de transfert fiable des données, cela implique également un temps d’attente plus long pour recevoir la ressource demandée.
Cela peut arriver seulement parce qu’avant de transmettre les données, TCP doit établir une connexion dans une opération qui s’appelle Handshake .
Un transfert de données fiable est essentiel pour HTTP, car si tout le corps HTML d’une page Web n’était pas transféré vers le navigateur, en raison d’une erreur de transmission, la page demandée serait impossible à afficher ou son contenu altéré.
Comme mentionné précédemment, HTTP appartient à la couche application tandis que TCP est un protocole de couche de transport. Cela explique un peu comment HTTP échanges des donnés avec le TCP.
Ceci est possible grâce aux douilles qui représentent le point de contact entre la couche application et la couche transport. Chaque application sur un hôte spécifique aura une prise d’interface spécifique vers la couche de transport.
Par exemple, si un utilisateur demande une page Web et envoie un e-mail en même temps, il y aura deux sockets :
- Une première qui gère les données d’échange entre HTTP et la couche de transport,
- Et l’autre entre les protocoles de messagerie électronique et la couche de transport.
Mais lorsque l’utilisateur essaye d’ouvrir deux pages web en même temps, une seule socket pourrait être créée dans ce cas.
Car la socket dans ce cas fait référence à un seul processus. La socket permet de gérer, de manière indépendante, les paquets reçus pour afficher séparément les deux pages web demandées.
1.3. Le but du protocole HTTP
Lorsqu’on parle du protocole de transfert hypertexte, nous faisons tout de suite référence au rôle de HTTP dans la transmission des données du site Web sur Internet.
Quant à l’hypertexte, il fait allusion à la forme standard de sites Web au travers laquelle une page peut renvoyer les utilisateurs vers une autre page via des hyperliens cliquables, généralement simplement appelés liens.
Le but du protocole HTTP est de fournir un moyen standard pour les navigateurs Web et les serveurs de communiquer entre eux.
Les pages Web sont conçues en utilisant le langage de balisage hypertexte, ou HTML, mais HTTP est utilisé aujourd’hui pour transférer plus que simplement HTML et les feuilles de style en cascade, ou CSS, utilisées pour indiquer comment les pages doivent être affichées.
HTTP est également utilisé pour transférer d’autres contenus sur des sites Web, notamment des images, des fichiers vidéo et audio.
Les ordinateurs peuvent se connecter à des serveurs Web en utilisant HTTP simplement pour demander les fichiers à des adresses Web particulières.
Lorsqu’un ordinateur récupère simplement des données, il envoie généralement un message HTTP appelé requête GET, et lorsqu’il envoie des données de formulaire ou télécharge un fichier, il utilise d’autres formats de messages appelés requêtes PUT ou POST.
Vous pouvez voir les messages HTTP que votre navigateur Web envoie dans de nombreux navigateurs via les outils de développement intégrés.
Aujourd’hui, HTTP est utilisé par de nombreuses applications autres que les navigateurs Web pour envoyer des messages aux serveurs.
Les personnes qui créent des applications choisissent volontairement HTTP parce qu’il est bien compris par de nombreux développeurs.
Une autre raison est que HTTP n’est généralement pas filtré par les pare-feu réseau conçus pour permettre le trafic Web, ce qui signifie que les messages HTTP peuvent passer sans problème sur la plupart des réseaux domestiques et professionnels.
1.4. Les avantages du protocole HTTP
La première chose que vous devez savoir est que HTTP utilise un schéma d’adressage avancé. Il attribue une adresse IP avec des noms reconnaissables afin qu’on puisse facilement la repérer sur le World Wide Web.
Par rapport à la procédure standard d’adresse IP avec une série de chiffres, en utilisant cela, le public peut facilement interagir avec Internet.
Toutes les fois qu’une application a besoin de capacités supplémentaires, HTTP peut lui octroyer de surplus de fonctionnalités en téléchargeant des extensions ou des plugins et d’afficher les données pertinentes.
Avec le protocole HTTP, chaque fichier est téléchargé à partir d’une connexion indépendante, puis se ferme. Pour cette raison, pas plus d’un élément d’une page Web n’est transféré. Par conséquent, le risque d’interception pendant la transmission est donc faible.
De plus, lorsque la page est chargée pour la première fois, toutes les pages HTTP sont stockées dans les caches Internet appelés cache de page.
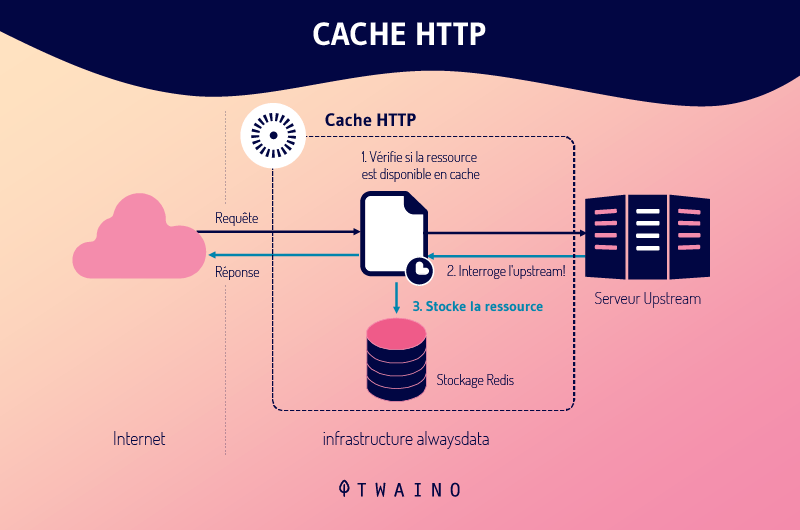
Par conséquent, une fois la page visitée à nouveau, le contenu sera chargé plus rapidement.
1.5. Les inconvénients du protocole HTTP
Étant donné que le protocole HTTP ne s’exécute pas à base du cryptage des données, il est fort possible que votre contenu soit modifié par quelqu’un d’autre.
C’est la raison pour laquelle HTTP est considéré comme une méthode non sécurisée et qui affiche à l’intégrité des données. Cela rend les données vulnérables aux attaques.
La confidentialité est un autre problème rencontré dans une connexion HTTP. Si un pirate parvient à intercepter la demande, il peut afficher tout le contenu présent dans la page Web.
En outre, ils peuvent également recueillir très facilement des informations confidentielles telles que le nom d’utilisateur et le mot de passe.
Par ailleurs, même si HTTP reçoit toutes les données dont il a besoin, les clients ne prennent aucune mesure pour fermer la connexion. Par conséquent, pendant cette période, le serveur ne sera pas présent.
De plus, une fois que HTTP doit créer plusieurs connexions pour transmettre une page Web, cela entraîne une surcharge administrative dans la connexion.
1.6. En quoi HTTP et HTTPS sont-ils différents ?
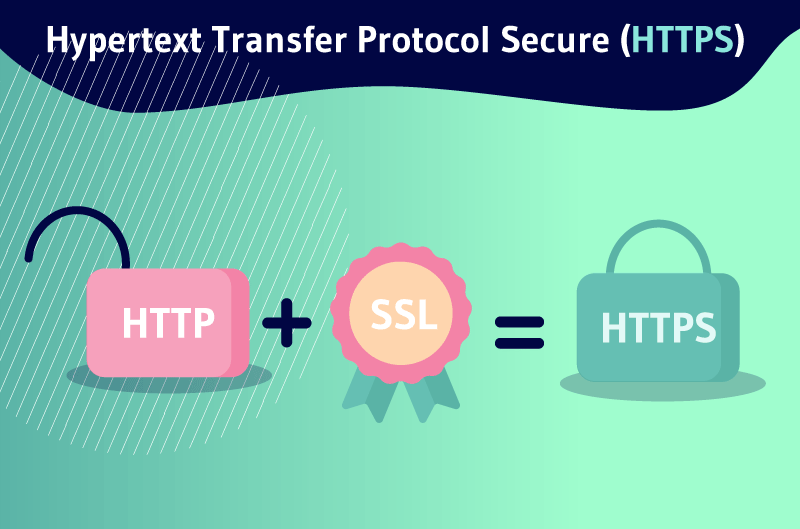
Si HTTP signifie Hypertext Transfer Protocol, HTTPS signifie aussi simplement Hypertext Transfer Protocol Secure.
Vous allez remarquer que certaines URL commencent par HTTP et d’autres par HTTPS, le ‘’S’’ se traduit par le cryptage sécurisé, qui est garanti avec un certificat.
HTTPS désigne tout simplement une clé publique déchiffrée du côté du destinataire. Et cette clé publique est obtenue dans un certificat SSL.
Le certificat SSL représente une pièce d’identité en ligne, indiquant que le site Web est protégé et exempt de menaces externes.
Les sites Web qui collectent les informations sensibles des personnes, y compris les adresses personnelles et les numéros de carte de crédit, doivent acheter une licence SSL.
Le cryptage SSL présente de nombreux avantages, tant pour les clients que pour les sites Web. Les principaux avantages comprennent:
- Protection contre les pirates : Comme le certificat protège les informations sensibles, les pirates et les voleurs d’identité seront confrontés à une haute sécurité des données.
- Authenticité et fiabilité : Les gens veulent faire des affaires avec un site Web sécurisé et digne de confiance. Ils n’effectuent aucun achat sur des sites Web qui ne sont ni vérifiés ni chiffrés.
- Augmentation du taux de conversion : Selon les résultats d’une analyse, les sites Web de commerce électronique protégés verront rapidement une augmentation de 18 à 87% du taux de conversion.
Quant au protocole HTTP, il se limite à une transmission de messages sans un cryptage de sécurité. Ce qui rend les données très vulnérables aux attaques.
Chapitre 2 : Qu’est ce qu’un code d’état HTTP ?
Il peut arriver que le client puisse lancer des requêtes auprès du serveur, et en retour, le serveur répond avec des codes d’état et des charges utiles de message. Le code d’état est important et indique au client comment interpréter la réponse du serveur.
La spécification HTTP définit certaines plages de nombres pour des types spécifiques de réponses :
2.1. 1xx : Messages d’information
Tous les clients HTTP / 1.1 doivent accepter l’en- Transfer-Encoding Tête. Cette classe de codes a été introduite dans HTTP / 1.1 et est purement provisoire.
Le serveur peut envoyer un Expect : 100-continue message, disant au client de continuer à envoyer le reste de la demande, ou ignorer s’il l’a déjà envoyée. Les clients HTTP / 1.0 sont censés ignorer cet en-tête.
2.2. 2xx : Réussi
Cela indique que la demande du client a été bien traitée. Très souvent, vous verrez affiché 200. Pour une GET demande, le serveur envoie les données dans le message. Il existe d’autres codes moins fréquemment utilisés :
- 202 Accepté : La demande a été acceptée, mais peut ne pas inclure la ressource dans la réponse. Ceci est utile pour le traitement asynchrone côté serveur. Le serveur peut choisir d’envoyer des informations pour la surveillance.
- 205 Réinitialiser le contenu : Indique au client de réinitialiser sa vue de document.
- 206 Contenu partiel : Indique que la réponse ne contient qu’un contenu partiel. Des en-têtes supplémentaires indiquent la plage exacte et les informations d’expiration du contenu.
2.3. 3xx : Redirection
- 303 Voir Autre : La ressource est temporairement localisée à une nouvelle URL.
- 304 Non modifié : Le serveur a déterminé que la ressource n’a pas changé et le client doit utiliser sa copie mise en cache. Cela repose sur le fait que le client envoie des informations ETag (Entity Tag) qui sont un hachage du contenu. Le serveur compare cela avec son propre calcul ETag pour vérifier les modifications.

2.4. 4xx : Erreur client
Ces codes sont utilisés lorsque le serveur pense que le client est en faute, soit en demandant une ressource invalide, soit en faisant une mauvaise demande.
Le code le plus populaire de cette classe est 404 Not Found, auquel je pense que tout le monde s’identifie. 404 indique que la ressource n’est pas valide et n’existe pas sur le serveur. Les autres codes de cette classe comprennent :
- 400 Bad Request : La requête a été mal formée.
- 403 Interdit : Le serveur a refusé l’accès à la ressource.
- 404 indique que la ressource n’est pas valide et n’existe pas sur le serveur. Cela oblige le client à prendre des mesures supplémentaires. Souvent, il est obligé d’accéder à une URL différente pour récupérer la ressource.
- 405 Méthode non autorisée : Verbe HTTP non valide utilisé dans la ligne de requête, ou le serveur ne prend pas en charge ce verbe.
- 409 Conflit : Le serveur n’a pas pu terminer la requête, car le client tente de modifier une ressource plus récente que l’horodatage du client. Les conflits surviennent principalement pour les demandes PUT lors des modifications collaboratives sur une ressource.
2.5. 5xx : Erreur de serveur
Cette classe de codes est utilisée pour indiquer une défaillance du serveur lors du traitement de la demande. Le code d’erreur le plus couramment utilisé est 500 Internal Server Error. Les autres de cette classe sont :
- 501 Non implémenté : Le serveur ne prend pas encore en charge la fonctionnalité demandée.
- 503 Service indisponible : Cela peut se produire si un système interne sur le serveur est en panne ou si le serveur est surchargé. En règle générale, le serveur ne répond même pas et la demande expire.
Conclusion
HTTP est depuis sa première version jusqu’à la récente le principal protocole de transmission des données sur Internet. C’est un inévitable moyen qu’emprunte n’importe quel utilisateur d’Internet pour avoir une réponse à sa requête.
C’est alors une nécessité pour toute personne utilisant le Net de bien connaître les essentiels sur HTTP. Pour cela, nous avons abordé les points qui peuvent vous sembler complexes sur le concept de HTTP.
J’espère que cet article vous a été utile, n’hésitez pas à me laisser des commentaires si vous avez des questions.


