
Une page est dite orpheline lorsqu’elle n’a aucun lien qui mène vers elle. Autrement, c’est une page inaccessible en ce sens qu’aucun lien interne ne conduit ni les internautes ni les robots d’exploration vers elle.
De nombreuses entreprises en ligne perdent de potentiels clients à cause de simples erreurs de référencement.
Une de ces erreurs est l’existence de certaines pages qui ne comportent aucun lien qui les rattache aux autres pages du site.
Il s’agit de pages nommées orphelines dont la présence sur un site représente une occasion manquée d’atteindre de nouveaux clients avec votre contenu. De plus, ces pages peuvent plus ou moins affecter le SEO de votre site web.
Heureusement, nous allons vous montrer dans cet article comment vous y prendre avec les pages orphelines sur votre site web.
Chapitre 1 : Quel sens peut-on donner à une page Orpheline ?
Parlant du sens d’une page orpheline, nous avons brièvement défini de quoi il s’agit, mais dans ce chapitre, nous allons le découvrir en profondeur.
1.1. Que veut dire une Page Orpheline ?
Comme dit plus haut, une page orpheline ou le contenu orphelin est une page qui n’est aucunement liée à d’autres pages de votre site web et qui n’a non plus aucun lien pouvant rediriger vers elle.
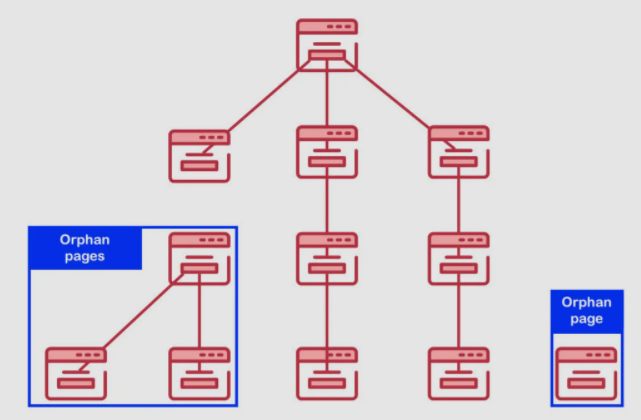
Source : affde
En effet, le fonctionnement des moteurs de recherche lorsqu’il s’agit de trouver une page est assez simple. Les robots d’exploration détectent un lien à partir d’une page et l’utilisent pour accéder à une autre page.
Un autre moyen consiste pour un robot d’exploration à trouver l’URL dans votre sitemap XML. Mais lorsqu’aucun lien n’amène vers une page, les robots d’exploration ne pourront pas la trouver, l’explorer et l’indexer.
Ce qui entrave l’apparition dans les SERP et le positionnement de votre site web sur des mots-clés présents dans le contenu de la page.
Mais pourquoi de telles pages existe ?
En effet, les webmasters créent des pages privées à partager avec une personne spécifique ou cela peut être une page promotionnelle saisonnière.
D’autre part, des pages orphelines peuvent être également créées par accident suite à une erreur de conception ou de publication.

Quelle que soit la raison d’existence d’une page orpheline, elle constitue un mauvais signal pour le SEP du site.
Voici donc quelques cas :
- Pages jamais ajoutées à la structure du site :
Souvent, lorsqu’une page est publiée, elle est ajoutée à la structure d’un site et liée à d’autres pages du site.
Une page de produit peut appartenir à plusieurs catégories et elle doit être liée aux pages de catégorie et des menus correspondants.
Un article de blog peut avoir différentes catégories et balises, cette page obtiendra donc des liens de chacune d’entre elles.
Mais, si une page n’a pas de catégorie ou n’est pas ajoutée à la structure d’une autre manière, elle n’obtient jamais de liens et n’est en fait accessible de nulle part. Lorsque ces pages ne sont pas liées en interne et ne font pas partie de l’architecture de votre site, les moteurs de recherche n’ont aucun moyen de les trouver.
- Pages manquées lors d’une migration de site :
Sans doute, nous savons tous comment se déroule une migration du contenu d’un site. Généralement, il s’agit d’un processus un peu complexe.
Et l’un des problèmes les plus courants avec les migrations de sites est de se retrouver avec des pages orphelines.
C’est la raison pour laquelle il faut un expert en référencement pour réussir la procédure de migration du site.
1.2. Quelles sont les caractéristiques d’une page Orpheline ?
Si plusieurs raisons peuvent justifier une page orpheline, il peut arriver que vous soyez dans la confusion lorsqu’il s’agira de distinguer une sur votre site.
Pour cela, voici quelques caractéristiques communes pour vous aider à vite identifier les pages orphelines sur votre site :
Une page orpheline n’a pas de liens entrants : C’est la première caractéristique d’une page orpheline. Si votre page a au moins un lien pointant vers elle, que ce soit depuis la page d’accueil ou sur un ancien article de blog, elle n’est pas orpheline dans ce cas.
Cela dit, si vous avez des pages sur le site qui n’ont qu’un seul lien pointant vers elles, il est simplement conseillé d’en ajouter.
Une page orpheline est aussi une page active : Le sandboxing ainsi que les pages de test ont tendance à être considérés comme des pages orphelines. La principale différence ici est que les pages orphelines sont en ligne et peuvent donner de la valeur aux utilisateurs. Le seul défaut important est qu’elles sont inaccessibles.
Bien qu’elles aient le statut de serveur 200, le fait que les utilisateurs n’aient aucun moyen d’y accéder les rend orphelines.
Une page indexée peut aussi être orpheline : Une page peut être orpheline même si elle est indexée ou si un outil indique qu’elle ne l’est pas. C’est le trait le plus difficile à vérifier, car il nécessite un effort d’investigation.
Certains outils peuvent ne pas détecter la nature orpheline d’une page en raison du fonctionnement inexact de certains outils.
1.3. En quoi les pages orphelines sont-elles un problème ?
Lorsqu’un visiteur atterrit sur votre site, que ce soit depuis les résultats de recherche ou via d’autres canaux, votre souhait serait certainement qu’il y passe assez de temps.

Les pages orphelines constituent une occasion manquée d’augmenter le trafic et les revenus de votre site web.
D’ailleurs, le PageRank est un algorithme que Google utilise pour classer les pages Web dans ses résultats de recherche.
D’après cet algorithme, le jus de lien de Google ne peut atteindre une page que si elle est liée à d’autres pages du site.
En d’autres termes, lorsqu’un site web n’a pas de liens internes, les robots des moteurs de recherche auront des difficultés à la considérer lors de l’exploration et de l’indexation.

Chapitre 2 : Comment gérer les pages orphelines ?
Avant de parler de la gestion des pages orphelines sur votre site web, voyons comment vous pouvez les détecter :
2.1. Comment identifier les pages orphelines ?
Il existe différentes approches que vous pouvez adopter pour identifier les pages orphelines sur votre site.
Le moyen le plus simple d’identifier les pages orphelines consiste à exécuter une exploration complète de votre site.

Il existe différents robots d’exploration développés par de grandes compagnies du webmarketing comme :
- SEMRush ;
- Ahrefs ;
- Moz ;
- Et Screaming Frog.
Ces robots d’exploration sont capables de parcourir l’ensemble de votre site web comme le font les robots des moteurs de recherche.
Suite à l’exploration du site, chacun de ces outils génère des rapports que vous pouvez consulter. Ces rapports vous donnent une idée claire de certaines informations précieuses sur votre site web.
Une sortie est le nombre de pages orphelines sur votre site et l’URL de la page. Voici un exemple d’un tel rapport par Ahrefs.
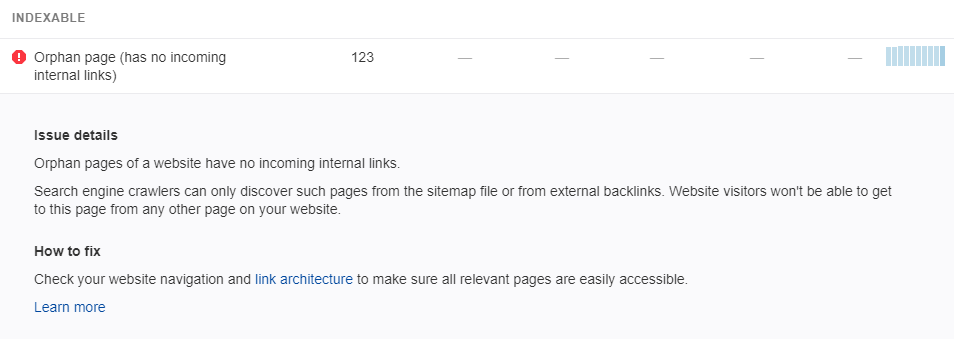
Source : i.stack
Sous la rubrique ‘’Indexable’’, vous avez une colonne pour les pages orphelines. Il vous suffit de cliquer sur le lien pour voir toutes les pages sans liens internes que comporte votre site.
2.2. Comment éviter les pages orphelines ?
Voyons dans cette section les bonnes manières de gérer ou d’éviter des pages orphelines sur votre site web.
2.2.1. Créer un plan de site
Comme son nom l’indique, un sitemap représente la carte de votre site. C’est en fait un document au format XML qui indique aux crawlers où ils doivent aller.
Le robot d’exploration consulte votre page XML pour mieux comprendre votre site en général et particulièrement :
- La taille du site ;
- Les pages importantes du site ;
- Et l’endroit où se trouve le nouveau contenu.
En fait, le sitemap XML est un élément important dans l’indexation d’un site, car il constitue un chemin de parcours pour les araignées des moteurs de recherche.
De plus, un sitemap XML permet à Google de savoir à quelle fréquence il doit rechercher des modifications ainsi que de nouvelles publications sur votre site.
2.2.1.1. Créer un sitemap avec Screaming Frog
L’une des meilleures options pour créer un sitemap XML est de le faire avec l’outil Screaming Frog.
Pour utiliser Screaming Frog, vous devez d’abord télécharger leur outil SEO Spider. Vous pouvez l’utiliser gratuitement si votre site compte moins de 500 pages.
Mais si votre site est plus volumineux, vous devrez acheter une licence, ce qui pourrait en valoir la peine compte tenu du temps qu’il faudrait pour rechercher et répertorier manuellement plus de 500 URL.
Une fois que vous avez installé le programme, tapez votre URL dans la case ‘’Enter URL to spider’’ et cliquez sur ‘’Start’’.
Ensuite, vous n’avez qu’à cliquer sur l’option Plans de site > Créer un plan de site XML.
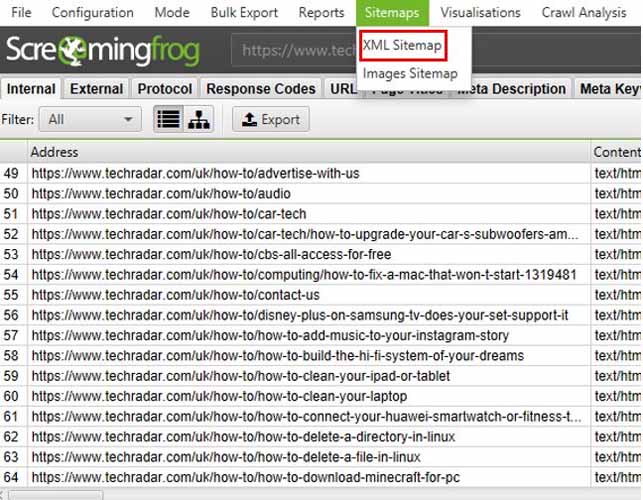
Source : tortoisedigital
Mais avant de créer votre sitemap, vous devez tenir compte de quelques paramètres que voici :
- Tout d’abord, vous devrez déterminer les pages que vous souhaitez inclure et celles que vous souhaitez exclure ;
- Par défaut, seules les pages avec une réponse ‘’200’’ OK de l’exploration seront incluses, vous n’avez donc pas à vous soucier des redirections ou des liens brisés.
Néanmoins, vous pouvez peut-être faire défiler votre liste de pages et rechercher le contenu en double. Par exemple, ce n’est pas normal d’avoir à la fois des versions WWW et non WWW d’URL dans votre sitemap.
Vous pouvez résoudre ce problème en faisant un clic droit sur la version que vous souhaitez supprimer, puis cliquer sur ‘’Supprimer’’.
Si vos pages varient en importance, vous pouvez choisir de définir des valeurs de priorité pour différentes URL. Vos URL peuvent aller de 0,0 à 1,0, la valeur par défaut étant 0,5.
Cela indique à Google les pages les plus importantes, afin qu’il puisse les indexer plus souvent.
2.2.1.2. Créer un sitemap avec Google XML
Google XML Sitemaps est un autre plugin gratuit pour les sites WordPress. Si vous n’utilisez pas Yoast, c’est aussi un moyen simple de générer un sitemap avec des paramètres personnalisés.
Tout comme sur Screaming Frog, vous pouvez arriver à définir aussi ces paramètres.
2.2.2. Soumettez votre sitemap à Google Search Console
Maintenant que vous avez créé un sitemap, vous devez le soumettre à la Search Console.
C’est ce qui permettra à Google de connaître toutes vos pages et trouver les plus importantes grâce à ses robots.
Pour commencer, allez sur votre page d’accueil Search Console, puis dans la barre latérale de gauche, cliquez sur ‘’Index’, puis sur ‘’sitemaps’’.
Cliquez sur le bouton Ajouter/Tester le sitemap en haut à droite et entrez l’URL de votre sitemap.
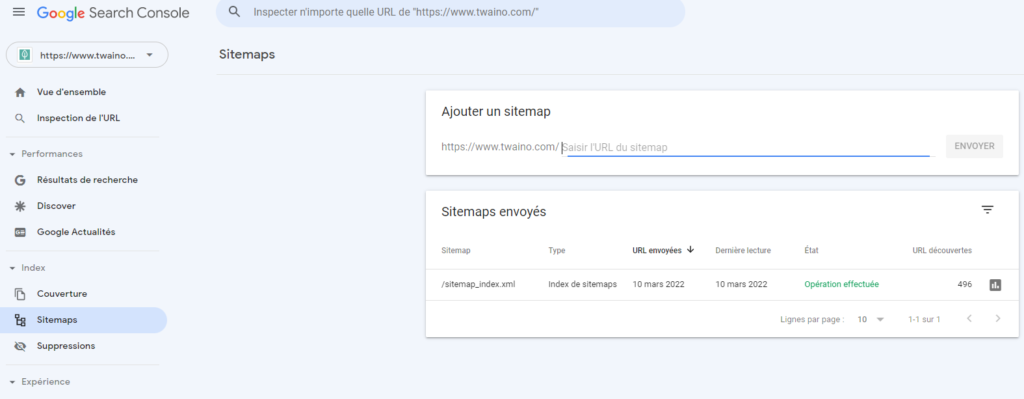
Dans la plupart des cas, l’URL de votre sitemap sera simplement http://votreurl.com/sitemap.xml. Si vous utilisez un plugin WordPress, l’URL sera dans les paramètres du plugin.
Après avoir cliqué sur ‘’Soumettre’’, vous verrez que votre sitemap restera en attente.
Une fois qu’il est approuvé, vous pouvez voir le nombre de pages que vous avez soumises par rapport au nombre qui a été indexé.
Cela peut vous donner une bonne idée de la quantité d’informations de votre site que Google stocke.
Il est aussi possible de trouver exactement où se trouve votre sitemap en la saisissant dans un navigateur web, elle devrait ressembler à ceci :

2.2.3. Créez un fichier robots.txt
Parlant du robots.txt, il s’agit d’un fichier qui oriente les moteurs de recherche sur les pages qu’ils doivent indexer et ceux qu’ils doivent ignorer.
Autrement le fichier robots.txt. définit les directives que chaque robot authentique doit suivre sur le site web.
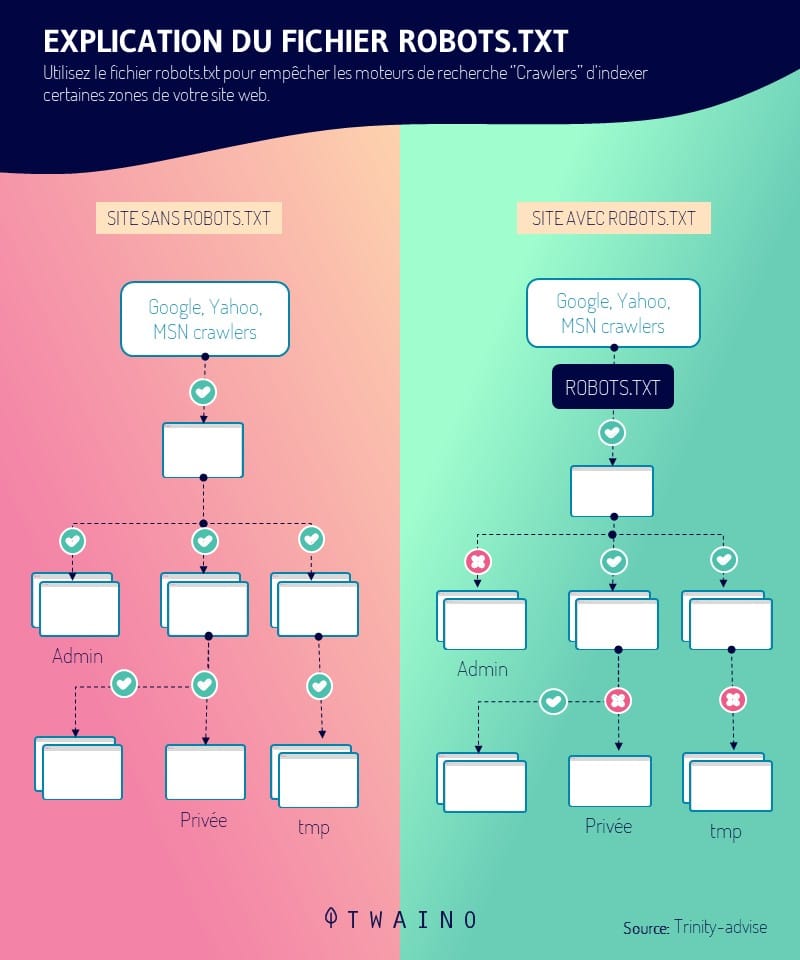
Il est donc très important que votre fichier robots.txt autorise Google à explorer le site.
La création d’un fichier robots.txt est encore plus facile lorsque vous utilisez des éditeurs par défaut de votre ordinateur, comme le Bloc-notes pour les utilisateurs Windows et TextEdit pour les utilisateurs Mac.
Avant de commencer, vérifiez votre FTP (File Transfer Protocol ) pour voir si vous avez déjà un fichier robots.txt.
Si vous en aviez, il devrait être stocké dans votre dossier racine sous quelque chose comme http://votredomaine.com/robots.txt.
Il suffit maintenant de le télécharger pour un point de départ, sinon, vous pouvez commencer à créer un fichier robots.txt à partir de zéro.
Google dispose d’une ressource robots.txt utile pour cela :

Pour créer votre fichier, vous devez connaître quelques éléments comme :
- User-agent : Le bot auquel la règle suivante s’applique ;
- Disallow : Ceci indique que vous voulez bloquer un chemin de l’URL ;
- Allow : Chemin d’URL dans un répertoire bloqué que vous souhaitez débloquer.
Il est également important de noter qu’un astérisque fait que la commande ‘’User-agent’’ s’applique à tous les robots d’exploration Web.
Ainsi, si vous créez des règles à l’aide de ‘’User agent : *’’, elles s’appliqueront aux robots d’exploration de Google, Bing et de tous les autres robots qui explorent votre site.
2.2.4. Créez des liens internes
L’un des moyens les plus efficaces d’encourager l’exploration et d’augmenter l’indexation de votre site consiste à utiliser des liens internes.
Les liens sont les chemins empruntés par les araignées sur Internet, lorsqu’une page est liée à une autre page, les araignées suivent les liens.
Naturellement, les liens se créent lorsque vous organisez de façon correcte l’architecture de votre site web.
En plus de vous éviter les pages orphelines, une bonne architecture offre plusieurs avantages sur les points suivant :
- Expérience utilisateur : Du point de vue de l’utilisateur, une architecture de site et une navigation cohérente rendent votre site beaucoup plus facile à parcourir. Un utilisateur ne devrait pas avoir à deviner où se trouve l’information qu’il recherche, il devrait les trouver en suivant vos liens. C’est aussi une bonne idée de garder la structure de votre site aussi simple que possible. Les méga-menus complexes peuvent sembler fantaisistes et sont parfois nécessaires pour les sites extrêmement volumineux ;
- Chemin pour les Crawlers : Au-delà de vos utilisateurs humains, une bonne structure du site facilite l’accès et l’indexation de votre contenu par les crawlers. Une architecture de site bien planifiée établit une hiérarchie entre vos pages. Cela aide les crawlers à saisir les pages les plus importantes du site et comment elles sont liées les unes aux autres. Les liens internes envoient les robots d’exploration vers d’autres pages de votre site et les aident à découvrir de nouveaux contenus.
2.2.5. Gagnez des liens entrants
Liens internes aident les araignées à comprendre la structure de votre site et à trouver de nouvelles pages, mais les liens les plus importants sont ceux qui proviennent d’autres sites.
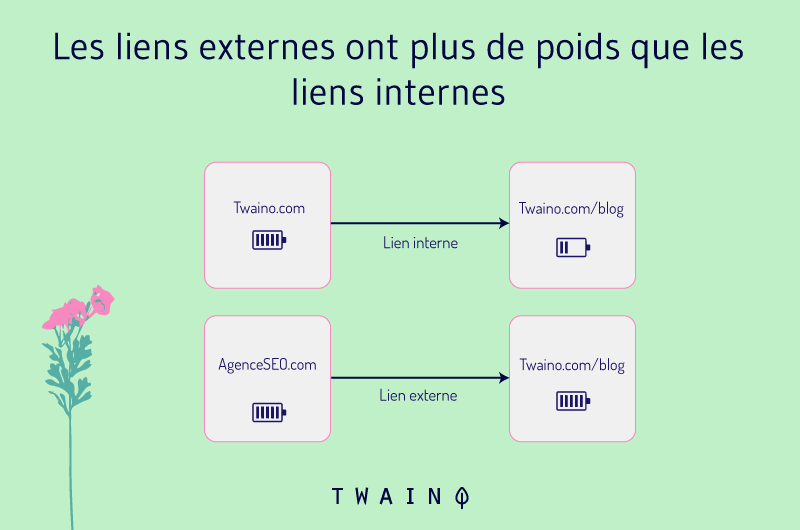
Plus vous avez de liens provenant de sites crédibles, plus vous apparaissez crédible aux yeux de Google et plus ils seront susceptibles de bien classer votre site.
Les liens d’autres sites envoient des robots d’exploration vers vos pages. Ainsi, si un autre site renvoie à l’une de vos nouvelles pages, cette page sera probablement explorée et indexée beaucoup plus tôt.
Et bien que certains de ces liens puissent se produire naturellement, il est préférable d’adopter une approche plus proactive.
Bien sûr, si vous avez de l’expérience dans la création de liens, vous savez que gagner des liens est souvent plus facile à dire qu’à faire.
Mais si vous créez une stratégie de promotion à l’avance, vous saurez exactement quoi faire une fois que votre nouveau contenu sera publié et vous aurez de meilleures chances que cette page soit rapidement indexée.
Si vous pouvez trouver des endroits pour syndiquer votre contenu, c’est l’un des moyens les plus simples d’assurer un public pour chaque nouveau contenu que vous publiez.
La syndication est le processus par lequel votre contenu est republié sur d’autres sites, avec un crédit accordé à votre site.
Dans certains cas, les propriétaires de sites trouvent même des versions syndiquées de leur contenu surclassant leur propre site.
Mais lorsqu’il est bien fait, cela peut vous aider à améliorer votre portée et à gagner plus de liens à partir de vos publications.
Conclusion
En général, les pages orphelines nuisent à votre classement et vous font perdre de l’argent, c’est pourquoi il est important de les trouver et de les corriger.
Dans cet article, nous avons développé non seulement le concept général des pages orphelines, mais aussi les bonnes manières de les gérer.
Si vous avez d’autres moyens d’éviter les pages orphelines sur le site, n’hésitez pas à les partager avec nous en commentaire.
A bientôt !


