
Duplicate content refers to blocks of text that are either completely identical to each other (exact duplicates) or similar with minor differences, also known as near-duplicates. In SEO, duplicate content occurs when this type of content appears on multiple URLs or web pages on the same or different websites.
According to Matt Cutts of Google, 25 to 30 percent of the contents are duplicated on the Internet. To stay in the same logic, a recent study by Raven Tools based on data from their audit tool gives us an approximate figure of 29 % regarding the same problem
Although this phenomenon is often unintentional, Google and other search engines indirectly penalize websites with duplicate content
To better understand this concept, the following key points should be addressed:
- A brief overview of the meaning of ”duplicate content” and its different types;
- The causes and ways to spot them;
- The best practices to manage them.
These are some of the many key questions to which I will provide clear and precise answers throughout this guide.
Find out more!
Chapter 1: What should we understand about ”duplicate content”?
In this chapter, I expose you the essential points about duplicated content such as:
- A brief reminder of its definition ;
- The different types that exist;
- Its impact on SEO










1.1. Duplicated content: What is it?
Duplicated content is a block of text that appears several times on the Web. When a text is present on a single URL, it is called unique content. Otherwise, it is considered as duplicated.

To be clearer, it is the act of copying the production of others and publishing it on your site. In general, this reproduction is done without the prior permission of its author.
Not only can this raise doubts about your ability to produce attractive and original texts, but also Google may penalize your SEO.
1.2) What are the different types of duplicated content?










Duplicated content is not only the result of a voluntary copy of texts or parts of them, but very often also :
- Technical causes related to the functioning of the CMS;
- Reasons related to the management of the product catalog in the case of an e-commerce;
- Etc.
From these cases that lead to the generation of duplicates, we deduce two types of duplicate content:
1.2.1. Internal duplicate content (on the same site)
We speak of internal duplicate content when we see a repetition of a text or parts of text on two or more pages of the same website

The internal duplicate content are generally in good faith, because they come mainly
- Technical errors;
- The setting of URLs;
- Etc.
It should be noted that it is not a question of content theft in this case, but of errors that lead to the multiplication of content on different URLs.
1.2.2. External duplicate content
These are pages whose text is the same as that present on other sites. This type of duplicate content is the one that causes real conflicts.

This case is found in particular in e-commerce product sheets, containing technical information on products and their functions of use.
It is not uncommon to see in e-commerce some people who use for their products the descriptions of their suppliers. This leads to the presence of the same textual content on several websites.
1.3. What impact can duplicate content have on the SEO and ranking of a site?










Due to the confusion that duplicate content causes to search engine spiders, any ranking and awareness can end up being split between duplicate URLs
This happens because search engine spiders have to choose which web page they think should rank for a particular keyword.
Thus, each URL variant receives different page authority scores and ranking power.
But over time, Google has come to understand that most duplicate content is not created intentionally
An analysis results that 50% of websites face duplicate content problems.

Google’s goal is to display a diversity of sites in the search results. This being the case, search engine crawlers are forced to choose which version of content to rank
In this case, your textual productions that you consider to be the most appropriate for a given theme may not be ranked because of their similarity with other existing ones.

In short, we can summarize the problems faced by websites related to content duplication in 3 points:
- Difficulty in ranking search results;
- Displaying a poor user experience;
- And decreased organic traffic.
Of course, these are obviously not the only problems related to content duplication, but they are the most painful for a site.
Chapter 2: What are the causes and how to spot duplicate content?
As the title of this chapter already announces, we will, after having exposed the causes of duplicate content, show you how you can detect them.










2.1. What are the causes of duplicate content?
There are many reasons why duplicate content can be created, but we will cite a few:
2.1.1. ”HTTP” vs ”HTTPS” and ”WWW” vs without ”WWW”
Adding sSL certificates certificates to your website is the best (or only) way to secure it. This allows you to transpose your website from HTTP to HTTPS
Nevertheless, it is an action that results in duplicate pages of your website if you do not perform redirects.

Also, since the content of your website is accessible from URLs with ”WWW” and without ”WWW”, duplication becomes inevitable.
The following URLs all lead to the same page, but would be considered as completely different URLs for search engine robots :
It should be noted that this situation is the most common cause of the duplication problem.
2.1.2. Scraped or copied content
When other websites “steal” content from another site, this is called content scraping. If Google or other search engines can’t identify the original version, they may end up ranking the page that was copied from your site.
This type of duplication often occurs for sites that have products listed with manufacturer descriptions
If the same product is sold on multiple sites and all of these sites use the manufacturer’s descriptions, the duplicate content can be found on multiple pages on different sites.

2.1.3. URL Variations
Variations in URLs can occur from
- Session IDs
- Query parameters and capitalization
When a URL uses parameters that do not change the content of the page, it can end up creating a duplicate page.
Session IDs work the same way. In order to keep track of visitors to your site, you can use session IDs to track what the user did while on the site and where they went
To do this, the session ID is added to the URL of each page they click on

Source Polepositionmarketing
Therefore, the session ID added in this case creates a new URL to the same page and is therefore considered duplicate content.
Capitalization is often not added intentionally, but it’s important to make sure your URLs are consistent and use lowercase letters
For example, twaino.com/blog and twaino.com/Blog would be considered duplicate pages.
Now that you are fully aware of some of the causes of duplicate content, let’s move on to detecting them.
2.2 How to spot duplicate content?
In this section, we will first see the free ways to find duplicate content, then the detection tools.
2.2.1. Free ways to recover duplicate content
Here are some free ways that will allow you:
- Find duplicate content;
- Track which pages have multiple URLs;
- And find out what problems are causing duplicate content to appear on your site.
2.2.1.1. Google Search Console
Google Search Console is a powerful free tool at your disposal. Configuring your console will help you gain visibility into the performance of your web pages in search results
Using the Coverage tab under Index, you can find URLs that may be causing duplicate content issues.
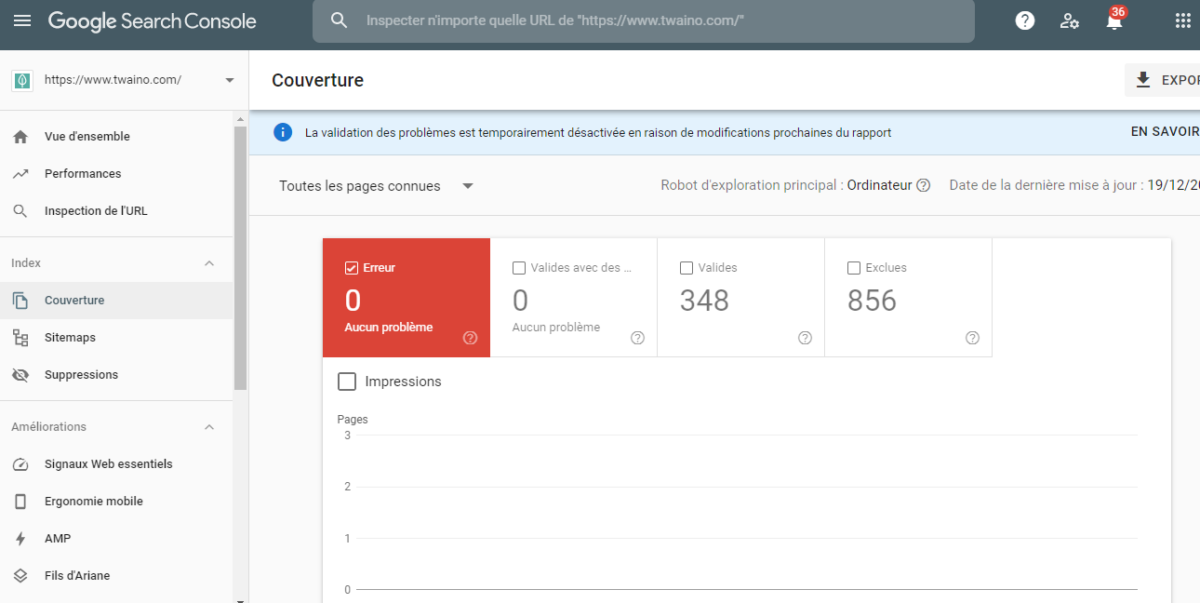
Look for the most common issues such as:
- HTTP and HTTPS versions of the same URL;
- Www and non-www versions of the same URL;
- URLs with and without a slash “/” ;
- URL with and without query parameters;
- URLs with and without capital letters;
- Long tail queries with multiple page rankings.
Keep track of URLs you discover with duplication problems so you can review them
2.2.2.2. Duplicate Content Checker
SEO Review Tools has created this duplicate content checker to help websites combat content theft. By entering your URL into their checker tool, you can get an overview of external and internal URLs that duplicate the URL entered.
Here is what was found when I plugged “https://www.twaino.com/” into the checker:

Finding external duplicate content is very important. As a reminder, external duplicate content occurs when someone else steals content from your site.
Once discovered, you can submit a removal request to Google and remove the duplicate page.
2.2.2. Tool to find duplicate content
Here is an overview of the main tools, free and paid, to detect internal and external duplicate content.
2.2.2.1 Copyscape
Launched in 2004, Copyscape is the best-known tool to fight against plagiarism and content theft attempts. This tool offers a free and paid service.

You don’t have to register to use the free version, you just have to enter the URL of the page you want to check and click on ”Go”.
But the shortcoming of this tool in its free version is that it cannot recognize users, since it is not mandatory to register before using it
Therefore, you won’t get any results if someone had already done the same search.
The paid version of this tool allows:
- Enter the text to be checked;
- Search over 10,000 pages;
- Exclude certain fields from the search
The cost is 0.05 USD per search.
2.2.2.2 Dupli Checker

Dupli Checker allows you to check the text entered manually or loaded from a file. It is then possible to make a comparison with the detected results, finding out the percentage of the same text.
2.2.2.3 Plagiarisma

Plagiarisma allows you to check only Bing in the free version. You just have to paste the text to be checked or the URL of the page to start the verification
There is a paid version that gives you access to additional functions at a cost of $0.05 per search.
2.2.2.4 Plagium

Plagium has two versions: free and paid. The first one offers a limited number of searches and works only by entering the text you want to check
The second one has a cost of $0.07 per search and allows you to get a larger number of results, since a more in-depth search is performed. With the paid version, you can also check documents in Word or PDF format.
2.2.2.5 PlagScan

PlagScan is a very comprehensive, but paid service, with packages starting at $4.99 for 5000 word searches
In addition to identifying pages with duplicate text, you can also see where it is located and compare different pages.
2.2.2.6 Quetext
It would be almost impossible to make a list of plagiarism detection tools without mentioning Quetext, which has significant popularity.
It is a well developed and efficient tool for detecting web pages with similar content to yours.
You can also select the option ”calculate similarity score” to get more accurate results.
Once the duplicates on your site are detected, it will be easy for you to remove them.
Chapter 3: How to remove or prevent duplicate content?










Removing duplicate content will help ensure that the correct page is accessible and indexed by search engine spiders
However, you may not remove all duplicate content, but point search engines to the original version to be indexed
Here is how you can do it:
3.1. rel = “canonical” tag
This is thanks to the attribute Rel = canonical tag attribute that search engine robots recognize the duplicate version of a page’s URL
Search engines will then send all links and ranking power to the specified URL, as they will consider it as the original version.
The use of the rel = canonical tag will not remove the duplicate page from the search results. It simply lets the search engine spiders know the original page that should benefit from any link equity in real time

These Rel = canonical tags are useful when the duplicate version does not need to be removed, such as URLs with parameters or trailing slashes.
3.2. 301 redirects
The use of a 301 redirect redirect is the best option if you don’t want the duplicate page to be accessible
When you set up a 301 redirect, it tells the search engine’s crawler which page is receiving all the traffic and SEO values.

When deciding which page to keep and which pages to redirect, look for the best performing and most optimized page
When you combine several pages that are competing for ranking positions into one piece of content, you will create a stronger, more relevant page that search engines as well as users will prefer.
3.3. Meta Noindex robots
The noindex tag tag is a snippet of code that you add to the HTML header of the page you want to exclude from search engine indexes
When you add the code “content = noindex, follow”, you are telling search engines to crawl the links on the page, but it prevents them from adding that content to their indexes.

The noindex tag is also useful in managing duplicate content in pagination. Pagination occurs when content spans multiple pages, resulting in multiple URLs
3.4. Self-referential canonical tag
To avoid content scraping, you can add the meta tag rel = canonical which points to the URL where the page is already located, this creates a self canonical page.
Adding this tag will tell search engines that the current page is the original.
When a site is copied, the HTML code is extracted from the original content and added to a different URL
If the canonical tag is included in the HTML code, it will probably also be copied to the duplicated site, thus preserving the original page as the canonical version

It is important to note that this is an additional protection that will only work if text scrapers copy this part of the HTML code.
Chapter 4: Other questions about duplicate content
4.1. What is duplicate content?
Duplicate content is when there are two or more identical or similar contents inside or outside a website.
4.2. How bad is duplicate content for SEO?
Duplicate content is bad for two main reasons:
When there are multiple versions of content available, it reduces the performance of all versions of the content because they are competing with each other.
It also makes it difficult for search engines to determine which version to index and then display in their search results
4.3. What are the different types of duplicate content?
There are two types of duplicate content:
- Internal duplicate content occurs when a domain creates duplicate content via multiple internal URLs (on the same website).
- External duplicate content, also known as cross-domain duplication, occurs when two or more different domains have the same page copy indexed by search engines.
External and internal duplication can occur as exact duplicates or near duplicates.
4.4. What are the risks of duplicate content for SEO?
Technically, duplicate content can still have an impact on search engine rankings. When there is more than one very similar piece of content, search engines have a hard time trying to decipher the best version.
Some of the problems that websites can encounter related to duplicate content include: Difficulty ranking in search results, decreased organic traffic, etc.
4.5. How to avoid duplicate content on your site?
To avoid duplicate content, you have two options:
- Use GSC to see the URLs with duplicate content on your site;
- Use a paid plagiarism detection tool.
4.6. What is copy and paste in web writing?
Copy and paste is the practice of copying the full text of an internal or external page of a site to produce new content. This practice is also referred to as plagiarism and poses a great threat to the website owner.
4.7. Does Google penalize duplicate content?
YES! Copying someone else’s production without taking precautions can not only affect the SEO ranking of your site, but can also cause its de-indexation from the Google index.
In summary
Even though duplicate content is often not created intentionally, it can indirectly hurt your SEO value and ranking potential if left unattended.
When you know how to deal with duplicate content on your website, search engine spiders will have an easier time playing their role in indexing and ranking your website.
That’s why we have taken the time to detail each of the points announced in the introduction of this article
It’s up to you to see to what extent these different concepts will allow you to effectively optimize your website.
And if you have other tips to fight against duplicate content, feel free to share them with us in the comments.
See you soon!