
Indexing in SEO refers to the procedure by which a search engine lists, stores and orders the pages of a website to quickly display them when a user launches a search. It is an essential step in natural referencing without which a website cannot be displayed in the results of a search engine
Search engines like Google or Bing are able to provide thousands of answers to a query in only a fraction of a second. But behind this speed of processing, there are many steps includingindexing
So
- What is indexing?
- How important is it for SEO ?
- And how to facilitate the indexing of a site?
Discover the answer to all these questions and more in this mini-guide entirely dedicated to indexing
Let’s get started!
Chapter 1: Indexing – How it works and why it’s important for SEO
Before we overwhelm you with technical terms, it’s appropriate that we cover how this concept works to avoid any ambiguity in the rest of the guide
1.1) How does indexing work?
When a website is newly created or a page is newly added to a site, they are not automatically accessible to search engines. The engines must first go through a number of steps before they can find them

And to reach these pages, search engines will send what is called in SEOcalled crawlers. As its name indicates, a crawler explores sites by tracing a path based on internal links and external links
Through these links, the crawler will “travel” between the pages of a site or from one site to another

During this journey of exploration, the robot will collect information, order it and store it in a database: this is the indexing stage. This database is called ” Index ”
After a request is launched, the search engines will draw on the information stored in the index to propose answers based on the keywords entered by the user in his request.
Without this indexing step, no page of a website can be displayed in the search engine results after a search. It is an essential step in natural referencing, but not sufficient, to rank a page well on search engines
That is to say that to succeed in having a good ranking on Google or any other search engine, you must gather other ranking criteria after the indexing stage of the pages
So, when a user launches a query on Google or Bing for example, he does not launch his search directly on the web, but rather in the index of the engines
If the search is related to your theme, your page will have no chance to be presented to the user if it has not been previously explored and indexed
Moreover, it must be said that search engines do not always index all the pages available on the Web. Sometimes, because of poor quality content or bad SEO practices, some pages of a site may not be indexed
We will come back in more detail in a later chapter on the factors that can prevent the indexing of a page
But once the user launches his request, what actually happens between the time that separates his request and the response of the search engine?
Well, the search engine will
- Analyze the user’s request to understand his search intention;
- Search its index and filter the information according to the user’s intention;
- Select all the pages deemed relevant to the request on the basis of several ranking criteria ;
- Then display these pages to the user in order of relevance
While some sites regularly update their pages, others end up obsolete
Also new pages are created every day, bringing if possible new information more relevant than the old contents
Faced with this continuous change of information, to remain efficient indexing robots are forced to regularly revisit the sites already indexed

The frequency of visit of a crawler on a site depends on several factors that define the Crawl budget of the site
1.2. how does indexing work with Google?
As previously explained, Google also works in the same way to index its web pages. What we must specify is that to explore the web and index the available pages, Google uses its indexing robot called Googlebot

If during the exploration, Googlebot comes across a page that is optimized for indexing, the robot can try to understand the theme it addresses
It can be a newly created page or an old page, as long as it meets the criteria for indexing optimization
To begin this indexing phase, Googlebot will analyze the page’s content, catalog the inserted visuals and any other available data that can help it understand the page’s purpose
All the information collected will then be classified by theme and stored in the Google index
This Google index is a vast database that contains several hundred billion pages. The search engine itself estimates the size of its index at over 100 million gigabytes
Now, let’s take a look at the importance of indexing for your site’s SEO.
1.3. How important is indexing to SEO?
When we explained how search engines index web pages, we mentioned the first importance of indexing for the SEO of your site
You already know that without the storage phase in the web index, the pages of your site can not be visible by Internet users on a results page of engines
And that’s not all, when Googlebot visits your site, the robot may detect malware, technical problems or poor quality content
In other words, you can take the Google index as a reliable source. If some of your pages are listed there, it is a proof that these pages are “healthy” and that they are relevant enough to be presented to Internet users
However, remember that Google also has a secondary index where it stores pages of lesser quality. These include duplicated pages or deemed “less relevant” by the search engine

In principle, Google does not display the pages ranked in the secondary index in its results, because it does not give the same importance to all pages. Ideally, your web pages should be ranked in the main index
But why are some pages not indexed by search engines? We’ll talk about this in the next chapter
Chapter 2: Factors that prevent the indexation of a page
Before presenting the factors that could block the indexing of your pages, here is what you incur if it really happens
2.1. The consequences of indexing problems
The nature and the problems that affect the indexing of a page are not the same in terms of consequences on the site
If it is a page that is less important to the owner that is affected, it is certainly not the end of the world
But if on the other hand, it is an important page with a highly optimized content that is affected, it is a pity and all the SEO efforts go down the drain.
If it is an e-commerce store, the consequences will be even heavier. It is agreed that for these e-commerce sites, organic traffic is more profitable in the long run than advertisements or PPC campaigns

Imagine that a good part of the product listings of the company are not indexed by Google. Consumers will not see them and the store will see its conversion rate considerably
Now, let’s look at the actual factors:
2.2. 10 common reasons why Google does not index all links
It is true that we have defined the index as the database of the engines, but the indexing robots are very selective and do not store everything in their path
There are common reasons why search engines do not index all links
2.2.1. Pages that return response codes other than 200
You may not know this, but if the pages on your site do not return the 200 response code, there is no chance that they will be indexed or continue to be indexed if they have been indexed
The code 200 (OK) indicates a positive response from the server following a request to access a page
For reasons of redirections redirections, access to a page may return 404 errors and until the error is cleared, search engines will not index this page
You can check the status of your important pages on HTTPStatus.io. Just the URL of the page and the tool displays the status of the page

If you find pages with the 404 code, I invite you to consult my article 404 error: Why and how to correct it efficiently?
2.2.2. Indexing can also be blocked by the Robots.txt file
You may invest the same attention to write all your content, but there are probably pages that represent more interest for your business than others
Even if the challenge for search engines is to provide relevant pages to Internet users, what would be your interest if they prioritize pages that are not necessarily a priority for you?
That’s why search engines give website owners the power to indicate which content they actively want to be indexed
The robots.txt file file is located at the root of your site and allows you to make indexing recommendations to search engines. So if one of your pages is not in the Google index, the first thing to do is to consult the Robot.txt file
If it is a page already indexed by the search engine, you will receive a message notifying you that the page is no longer available and that the problem comes from the Robots.txt file:

Source Kern Media
See my article on the Robots.txt file to find out how to optimize your Robots.txt file and fix such errors.
2.2.3. The Meta Robots tag with the value “Noindex
Another one of the most common reasons why a website can end up unindexed by Google is the presence of the Meta Robots tag in the part of the page’s source code
If this tag takes the value “noindex”, it is a message to Google telling it not to index the page concerned. And indeed, Google will not index the page until the value is changed
To check the value of the meta Robots tag tag on a page, right-click on the page and click on “Inspect Element” to access the source code directly
To go fast, you can combine the keys ” Ctrl + Uto access the source code

Once in the code, replace the value of the “content” parameter with the one that suits you best. Discover the syntax of the tag as well as the different possible values to assign in this article which defines the meta Robots tag.
2.2.4. The X-Robots tag with the value “Noindex
This tag works a bit like the Meta Robots. It also allows you to control the way Google should index a page. But it must be said that the X-Robots tag is rather found in the response of the header of web pages or certain documents
These are usually non-HTML pages without the section such as PDF, DOC, etc
Unless you intentionally added “noindex” to the X-Robots tag, it is very rare for this to happen by accident. In any case, check this eventuality as well to make sure that it is not the X-Robots tag that is preventing your page from being indexed
To do this, you can use the chrome extension SEO Site Tools :

Source Kern Media
2.2.5. Duplicate content on the site
The duplicate content on the same site are very harmful for SEO in general. A content that is partially or completely duplicated on another page of the same site can prevent the others from being indexed by search engines
So if you notice duplicate content on your site, it may be the root of your indexing problem. If the number of copies is high, even the original page will be downgraded on Google SERPs
To find out if you have duplicate content on your site, you can use the Siteliner to quickly crawl the site and retrieve the URLs of duplicate pages
It’s quite simple to use, you just enter the domain name of the site and the tool will provide a graph with the percentage rate of duplicated content.

Google remains quite firm on duplicate content and tolerates a few small passages that may be repeated
So to a certain extent, it is quite possible that pages with similar content on your site can be indexed and get a ranking on Google
But if it is a question of a large volume of content that is copied and pasted entirely onto other pages, it is likely that Google will penalize these pages and even remove them from its index
2.2.6. Duplicate contents outside the site
Even if you are careful with duplicate content on your site, duplicate content coming from outside, i.e. from other sites, can still reach you
A large amount of duplicate content on several other sites would also look bad to the search engine
Regardless of your industry or the type of site you have, Google’s penalties for duplicate content remain the same. If you suspect that some websites have plagiarized an excerpt of your content, put the excerpt between 2 quotation marks and then run a search on Google
You will get a list of websites that have used this excerpt in their content, similar to the way citations are found on Google
To be sure of the result, you can use a dedicated tool capable of spotting duplicate content, it is Copyscape. The tool provides a detailed report of the websites that have plagiarized you

You can also use the plagiarism checker Quetext plagiarism checker to find out if sites have scrupulously copied your content
Once these sites are listed, find out in this article strategies to claim your duplicated contents and ask Google to give you back the right
2.2.7. Pages that do not add value to Internet users
The first challenge of search engines is to provide results that are relevant and that respond effectively to the user’s query
Unfortunately, not all content on the Net provides real added value to Internet users.
If you think you are in the same situation, fix the quality of your content as soon as possible to offer a better experience to your users. Google will reward you by indexing your pages regularly

We have for example theaffiliation sites that usually generate ads without caring too much about the satisfaction of the user. Google’s algorithms are becoming more and more intelligent and are able to detect these pages of little value and not index them.
2.2.8. Your site has just been created
If you have just created your site, it is important to know that its indexing will not be systematic. It takes time for Google or any other search engine to discover you.
As explained above, to reach your site, Google will make its way with links. This is why it is important to have good link building strategiesespecially if it is a newly created site
2.2.9. The speed of loading your page
Beyond the quality of the textual content, a site must also improve its technical performance
In spite of its contents, a site that takes forever to load, or that chains pop-up windows in an untimely manner or that offers a bad user experience will always be badly seen by search engines
The loading time of your pages directly impacts the traffic rate. The slower the loading time, the less time users will spend on your site

And since Google always advocates user experience, the engine discourages sites that do not have a fast loading speed
If the slowness problem persists, Google may even decide to remove the affected page from its index
There are a number of tools to test the loading speed of your pages, including Page Speed Insights from Google or the tool GTMetrix
2.2.10. Orphan pages
To update its index, Google regularly explores websites, including sitemaps XML SITEMAPS. If yours is often visited by Googlebot and you meet the ranking factors, the search engine will be able to improve your positioning on its SERPs
But if during the crawl Google does not find links that redirect to a particular content on your site, that content will simply not be indexed
No matter if the link is internal or from an external site, Google needs it to reach the content, crawl it and if possible index it
These pages that have no internal link are what we call in SEO ” orphan pages “. If your site has too many orphan pages, it can discourage Google from indexing your site regularly
To detect orphan pages on your site, you can use the Screaming Frog

For the little trick, you can export all the URLs crawled by Screaming Frog on a spreadsheet
Then compare this first list of URLs to the one available in your XML sitemap. All links that are in the sitemap and not in the Screaming Frog crawl report will be considered orphan pages
It’s good to know how to recognize the indexing problems that undermine your site and fix them.
But it’s even better to constantly keep an eye on the site to quickly spot these problems before they affect your SEO
2.3. monitor your site’s indexing status with Google Search Console
As we have seen, having indexing errors can ruin a site’s SEO and decrease its revenue
But before that happens, Google provides you with a tool to constantly monitor the indexing status of your site: it is the Google Search Console
To use this tool, first access its home page
Then in the left sidebar, click on the following options located just below the “Index” tab:
- Coverage

- Sitemaps

It is recommended to check the indexing status at least once every month or 2 months to detect errors rather
After fixing the indexing problems of their site, a question often comes up among site owners: “When will my page be indexed?”
2.4. Knowing when a page will be indexed
Many website owners worry and wonder when their page will be indexed. Well, unfortunately there is no precise answer that can be given to this question
The fact is that you don’t control everything when it comes to indexing a page. Despite your best efforts, according to Google’s guidelines, there are other external factors that do not necessarily depend on your willingness to see a page quickly indexed.
Simply because you are not the only one who wants to be indexed by Google. There are millions and millions of other pages available on the Web waiting to be explored
Your turn may be tomorrow, or next week, or in a few months, it is difficult to give an exact difficult to give an exact time frame. Everything will depend on the frequency that Google has set to explore your site.
Nevertheless, Google offers the possibility to request the crawling of your new URLs
2.5. How to request a crawl to Google ?
For any new or recently updated page on your site, you can formulate an indexing request and send it to Google by following the methods below
2.5.1. Use the URL inspection tool to request indexing of some pages
Before presenting the procedure to follow, it is important to note that without access to a Google Search Console account, you cannot request an indexation with the Google inspection tool
To do this
- Monitor the relevant URL with theuRL inspection tool inspection tool
- Select “URL Inspection”. The tool will start an online test of the URL to check if it is already indexed or not:
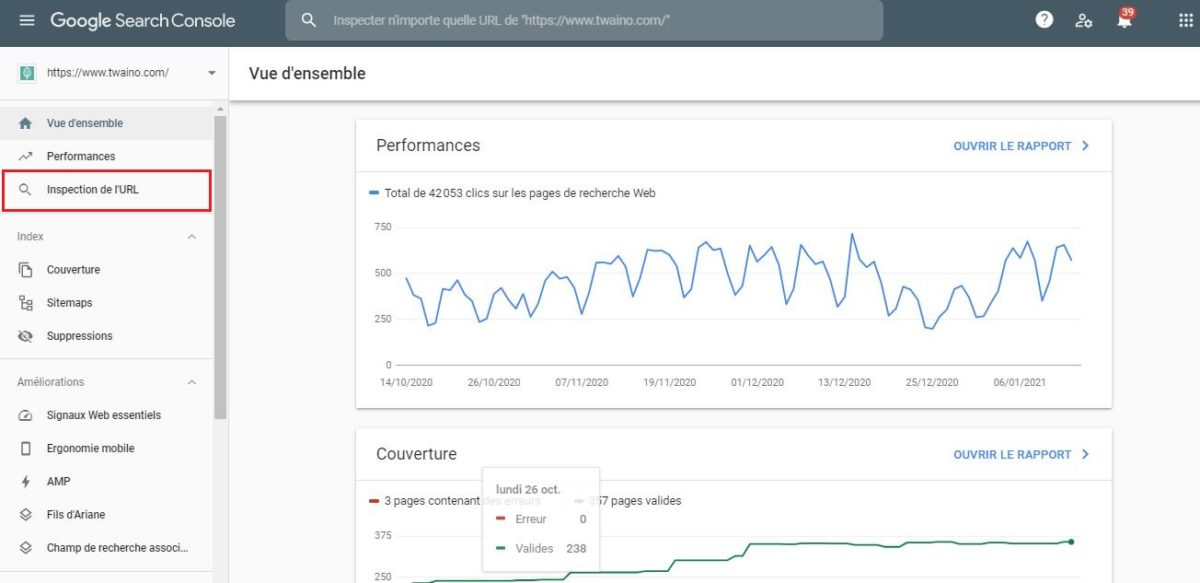
You will be notified if there is any problem or if the page is already present in the Google index:

But if the page is not yet indexed, you can ask for an indexing:

Note : Requesting crawling does not guarantee that the URL will automatically be stored in Google’s index. In some cases, the indexation may not even take place. The case of a content of bad quality for example
2.5.2. Ask the indexation of a large number of URLs with the sitemap
The sitemap is a file in which Google gets an idea of the URLs that your site has. If you do not know how to create a sitemap, you can consult this article proposed by Google
If a sitemap has not been modified since the last exploration of Google, it is useless to send it again to the search engine. But if you have added pages to your sitemap, take care to tag it with the attribute
Here are the different steps to follow to alert Google of changes made to the sitemap
- Send a sitemap thanks to the sitemap report
- With your browser or the command editor, you can send a GET request to the following address by informing the complete link of the sitemap : http://www.google.com/ping?sitemap=
Example:
- Then, go to your Robots.txt file and add the following code
Sitemap: http://example.com/my_sitemap.xml
With the following steps, Google will be able to crawl the pages added to the sitemap the next time it visits
Chapter 3: Other questions about indexing
3.1) What does indexed by Google mean?
A page is said to be indexed by Google when it :
- Has been visited by the Google crawler (“called Googlebot”) ;
- Is the subject of a complete exploration
- Finally, stored in the Google index.
While the vast majority of web pages go through the crawling stage before indexing, Google may also index pages without accessing their content. For example, when a page is blocked by a robots.txt file.
3.2. What is web crawling and indexing?
Crawling: This is a stage of the Internet journey by crawlers in search of content, exploring the code/content of each URL they discover
Indexing: This is the step of storing and organizing the content found during the crawling process. Once a page is stored in the index, which is the large database, it is waiting to be displayed in response to relevant queries.
3.3) Why is web indexing useful?
Search engines index websites in order to answer search queries with relevant information as quickly as possible. For this reason, they store information about the indexed web pages, for example: keyword, title or description in a database. This way, search engines will be able to easily and quickly identify the relevant pages for a search query.
3.4. What are indexing errors?
If you get the message “the URL is not on google: indexing errors”, it means that Google has either removed the URL from its index because it could not access it, or that it was not in its index because it was not available during its first attempt.
3.5. Why is my site not on Google?
If your site does not appear on Google, it is probably for one of the following reasons:
- Google has not yet indexed your website
- Google considers that your site is not “trustworthy” or “relevant” enough to be displayed for the keywords you want to rank for
- You have blocked the Googlebot crawler in your robots file.
To resolve this issue, run a live inspection, resolve any issues you may have and submit the page for indexing.
3.6. How do I stop Google from indexing my site?
To prevent one of your pages from appearing in Google search, simply include a noindex meta tag in the HTML code of the page or by returning a noindex header in the HTTP response.
3.7. How to check if your page is indexed by Google?
To see if search engines such as Google and Bing have indexed your site, enter : ” site:URL of your domain ”
The results show all the pages of your site that have been indexed and the current Meta tags recorded in the index of the search engine.
It is important to know that the exploration of your site by search engines can sometimes take some time.
3.8. How much of the Internet is indexed by Google in 2020?
Google has stored in its index about 35 trillion web pages on the Internet worldwide. While this is an amazing statistic, believe it or not, 35 trillion is just the tip of the iceberg. Google’s index only represents about 4% of the information that exists on the net.
Conclusion
In short, indexing is an essential step for the referencing of a web page and is part of a process ensured by the indexing robots
After having newly created a website or published a new page, fully optimized for SEO, the best way to help its page to be indexed would be to wait
Although for some reasons, one may sometimes be forced to use methods to indicate some recommendations to search engines
I hope that this definition on “Indexing” has been useful and will add to your knowledge in SEO
If you have other questions, don’t hesitate to ask me in the comments
Thanks and see you soon!