
A page is said to be orphaned when it has no link leading to it. Otherwise, it is an inaccessible page in the sense that no internal link leads neither the Internet users nor the crawlers to it
Many online businesses lose potential customers because of simple SEO mistakes.
One of these mistakes is the existence of some pages that have no links that connect them to other pages on the site.
These are so-called orphan pages whose presence on a site represents a missed opportunity to reach new customers with your content. Moreover, these pages can more or less affect the SEO of your website.
Fortunately, we will show you in this article how to deal with orphan pages on your website.
Chapter 1: What meaning can you give to an Orphan Page?
Speaking of the meaning of an orphan page, we have briefly defined what it is, but in this chapter we will discover it in depth.
1.1) What does an Orphan Page mean?
As said above, an orphan page or orphan content is a page that is not linked to any other page on your website and has no links to it.
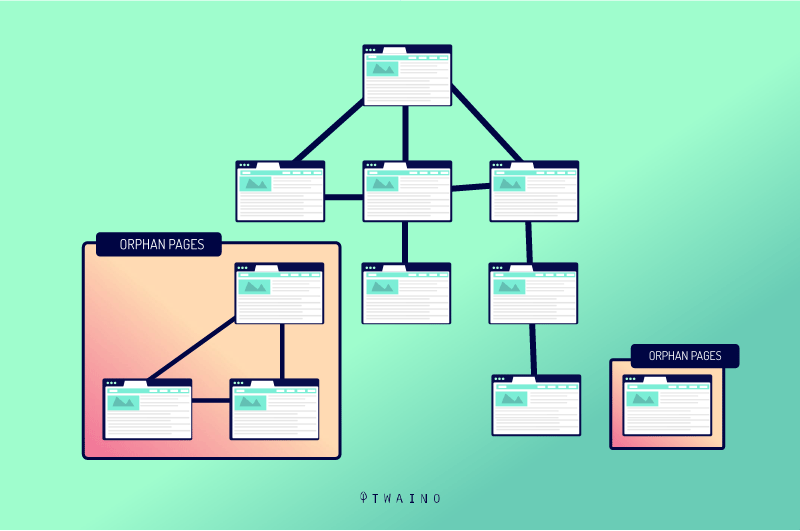
Source : affde
Indeed, the way search engines work when it comes to finding a page is quite simple. The crawlers detect a link from a page and use it to access another page
Another way is for a crawler to find the URL in your XML sitemap. But when there is no link to a page, crawlers will not be able to find it, crawl it and index it.
This hinders the appearance in the SERPs and the positioning of your website on keywords present in the content of the page.
But why such pages exist?
Indeed, webmasters create private pages to share with a specific person or it can be a seasonal promotional page
On the other hand, orphan pages can also be created by accident due to a design or publishing error.

Whatever the reason for the existence of an orphan page, it is a bad signal for the SEP of the site
So here are some cases
- Pages never added to the site structure:
Often, when a page is published, it is added to a site’s structure and linked to other pages on the site
A product page can belong to several categories and must be linked to the corresponding category and menu pages
A blog post can have different categories and tags, so this page will get links from all of them
But, if a page doesn’t have a category or isn’t added to the structure in some other way, it never gets links and is actually not accessible from anywhere. When these pages are not linked internally and are not part of your site’s architecture, search engines have no way to find them.
- Missed pages during a site migration:
No doubt, we all know how a site content migration goes. Usually, it is a bit of a complex process
And one of the most common problems with site migrations is ending up with orphaned pages.
That’s why you need an SEO expert to successfully complete the site migration process.
1.2. what are the characteristics of an orphan page?
While there are several reasons for an orphan page, you may be confused when it comes to distinguishing one on your site.
Therefore, here are some common characteristics to help you quickly identify orphan pages on your site:
An orphan page has no inbound links: This is the first characteristic of an orphan page. If your page has at least one link pointing to it, either from the home page or from an old blog post, it is not orphaned in this case
That said, if you have pages on the site that have only one link pointing to them, it is only advisable to add one.
An orphan page is also an active page: Sandboxing and test pages tend to be considered orphan pages. The main difference here is that orphan pages are online and can provide value to users. The only significant flaw is that they are inaccessible
Although they have server 200 status, the fact that users have no way to access them makes them orphaned.
An indexed page can also be orphaned: A page can be orphaned even if it is indexed or if a tool indicates that it is not. This is the most difficult feature to check, because it requires an investigative effort
Some tools may not detect the orphan nature of a page due to the inaccurate operation of some tools
1.3 Why are orphan pages a problem?
When a visitor lands on your site, whether from search results or through other channels, you certainly want them to spend enough time there.

Orphaned pages are a missed opportunity to increase your website’s traffic and revenue.
By the way, PageRank is an algorithm that Google uses to rank web pages in its search results
According to this algorithm, Google’s link juice can only reach a page if it is linked to other pages on the site
In other words, when a website has no internal links, search engine spiders will have difficulty considering it during crawling and indexing

Chapter 2: How to manage orphan pages?
Before talking about the management of orphan pages on your website, let’s see how you can detect them:
2.1. How to identify orphan pages?
There are different approaches you can take to identify orphan pages on your site.
The easiest way to identify orphan pages is to perform a full crawl of your site.

There are different crawlers developed by major web marketing companies such as
- SEMRush
- Ahrefs
- Moz ;
- And Screaming Frog.
These crawlers are capable of crawling your entire website like search engine robots do.
Following the exploration of the site, each of these tools generates reports that you can consult. These reports give you a clear idea of some valuable information about your website.
One output is the number of orphaned pages on your site and the URL of the page. Here is an example of such a report by Ahrefs.
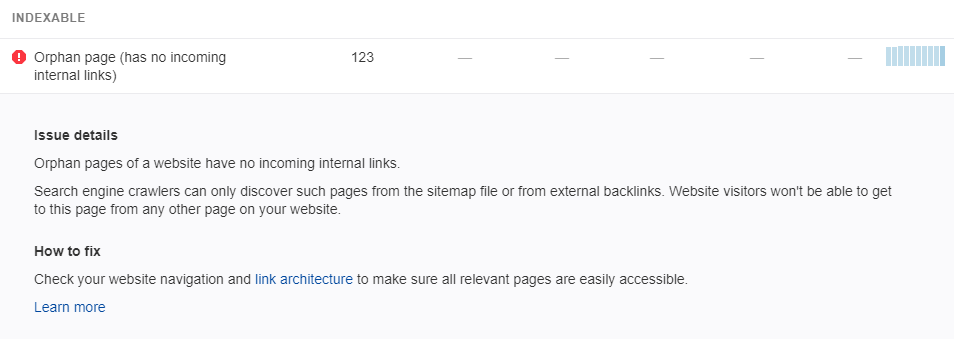
Source : i.stack
Under the heading ”Indexable”, you have a column for orphan pages. Just click on the link to see all the pages without internal links on your site.
2.2. how to avoid orphan pages?
Let’s see in this section the good ways to manage or avoid orphan pages on your website.
2.2.1. Create a sitemap
As its name indicates, a sitemap represents the map of your site. It is in fact a document in XML format that tells the crawlers where they should go.
The crawler consults your XML page to better understand your site in general and particularly:
- The size of the site
- The important pages of the site
- And the location of new content
In fact, the XML sitemap is an important element in the indexing of a site, because it constitutes a path for the search engine spiders.
Moreover, an XML sitemap allows Google to know how often it must look for modifications as well as new publications on your site
2.2.1.1. Create a sitemap with Screaming Frog
One of the best options to create an XML sitemap is to do it with the Screaming Frog tool.
To use Screaming Frog, you must first download their SEO Spider tool. You can use it for free if your site is less than 500 pages.
But if your site is larger, you’ll need to purchase a license, which might be worth it considering the time it would take to manually search and list over 500 URLs.
Once you have installed the program, type your URL in the box ”Enter URL to spider” and click on ”Start”.
Then, simply click on the option Sitemap > Create XML Sitemap.
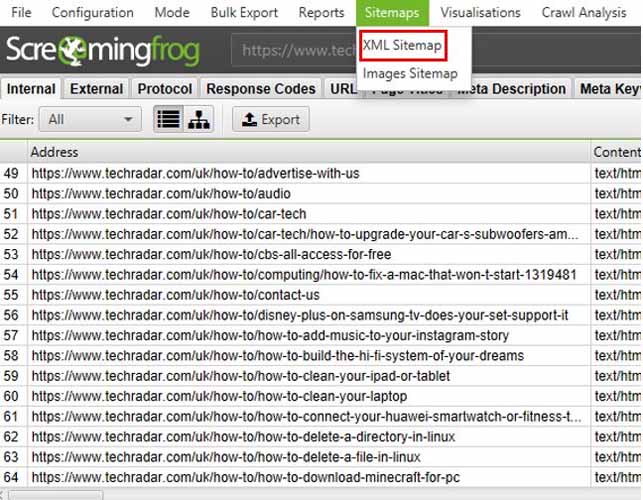
Source : tortoisedigital
But before creating your sitemap, you must take into account a few parameters that here :
- First, you will need to determine which pages you want to include and which you want to exclude;
- By default, only pages with a ”200” OK crawl response will be included, so you don’t have to worry about redirects or broken links.
However, you may want to scroll through your list of pages and look for duplicate content. For example, it’s not normal to have both WWW and non-WWW versions of URLs in your sitemap.
You can solve this problem by right-clicking on the version you want to delete, then click ”Delete”.
If your pages vary in importance, you can choose to set priority values for different URLs. Your URLs can range from 0.0 to 1.0, the default value being 0.5.
This tells Google which pages are most important, so that it can index them more often.
2.2.1.2. Creating a sitemap with Google XML
Google XML Sitemaps is another free plugin for WordPress sites. If you don’t use Yoast, it’s also an easy way to generate a sitemap with custom settings.
Just like on Screaming Frog, you can manage to define these parameters as well.
2.2.2. Submit your sitemap to Google Search Console
Now that you have created a sitemap, you must submit it to the Search Console.
This is what will allow Google to know all your pages and find the most important ones thanks to its robots.
To start, go to your Search Console homepage, then in the left sidebar, click on ”Index”, then on ”sitemaps”.
Click on the Add/Test Sitemap button on the top right and enter the URL of your sitemap.
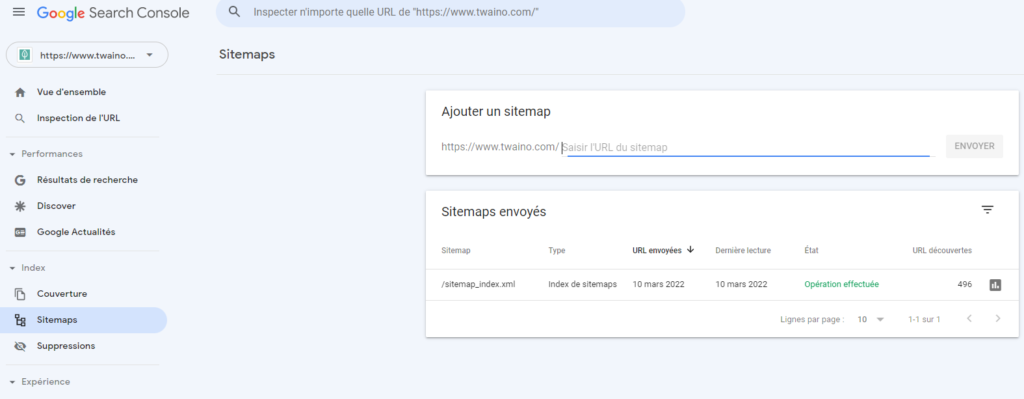
In most cases, the URL of your sitemap will simply http://votreurl.com/sitemap.xml. If you use a WordPress plugin, the URL will be in the plugin settings
After clicking on “Submit”, you will see that your sitemap will remain pending.
Once it is approved, you can see the number of pages you submitted versus the number that were indexed.
This can give you a good idea of how much information about your site Google is storing.
It is also possible to find out exactly where your sitemap is by typing it into a web browser, it should look like this:

2.2.3. Create a robots.txt file
Speaking of robots.txt, this is a file that directs search engines on which pages they should index and which they should ignore.
In other words, the robots.txt file defines the guidelines that each authentic robot must follow on the website
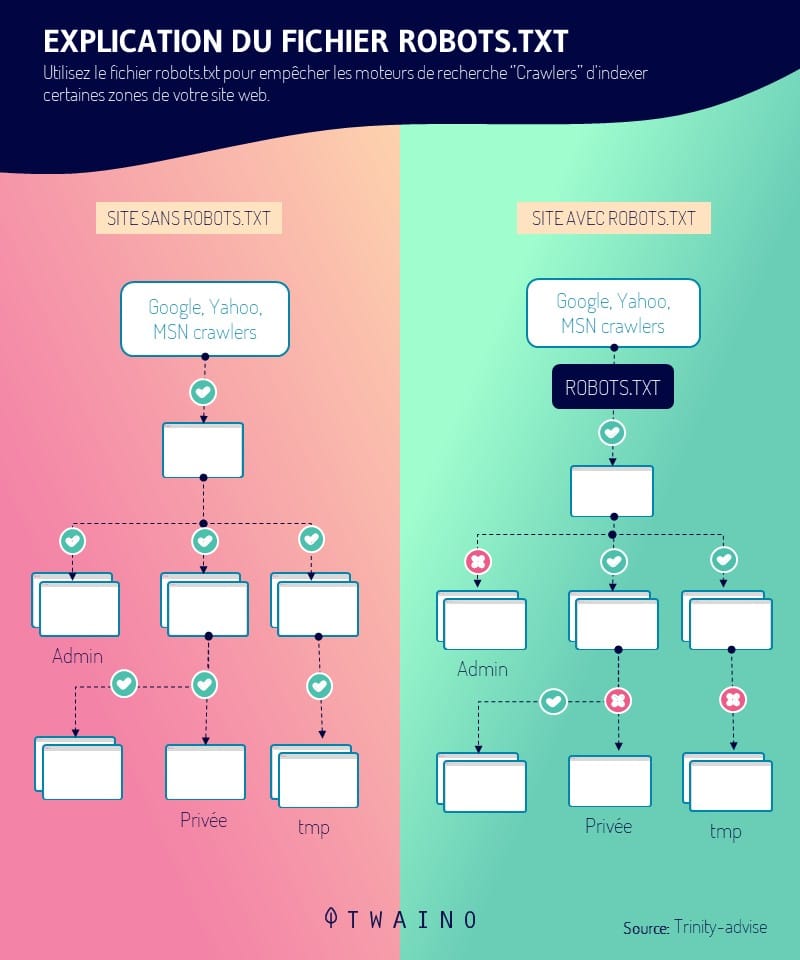
It is therefore very important that your robots.txt file allows Google to crawl the site
Creating a robots.txt file is even easier when you use your computer’s default editors, like Notepad for Windows users and TextEdit for Mac users.
Before you start, check your FTP (File Transfer Protocol) to see if you already have a robots.txt file
If you do, it should be stored in your root folder under something like http://votredomaine.com/robots.txt.
Now just download it for a starting point, otherwise you can start creating a robots.txt file from scratch.
Google has a useful robots.txt resourcefor this:

To create your file, you need to know a few things like:
- User-agent: The bot to which the following rule applies;
- Disallow : This indicates that you want to block a path of the URL ;
- Allow: URL path in a blocked directory that you want to unblock.
It is also important to note that an asterisk makes the command ”User-agent” applies to all web crawlers
Thus, if you create rules using ”User agent : *”, they will apply to crawlers of Google, Bing and all other robots that explore your site.
2.2.4. Create internal links
One of the most effective ways to encourage crawling and increase indexing of your site is to use internal links.
Links are the paths taken by spiders on the Internet, when a page is linked to another page, the spiders follow the links.
Naturally, links are created when you organize the architecture of your website correctly.
In addition to avoiding orphan pages, a good architecture offers several advantages on the following points:
- User experience: From the user’s point of view, a consistent site architecture and navigation makes your site much easier to navigate. A user should not have to guess where the information they are looking for is, they should find it by following your links. It’s also a good idea to keep the structure of your site as simple as possible. Complex mega-menus can look fancy and are sometimes necessary for extremely large sites;
- Path for Crawlers: Beyond your human users, a good site structure makes it easier for crawlers to access and index your content. A well-planned site architecture establishes a hierarchy between your pages. This helps crawlers understand the most important pages of the site and how they relate to each other. Internal links send crawlers to other pages on your site and help them discover new content.
2.2.5. Earn inbound links
Internal links help spiders understand the structure of your site and find new pages, but the most important links are those from other sites.
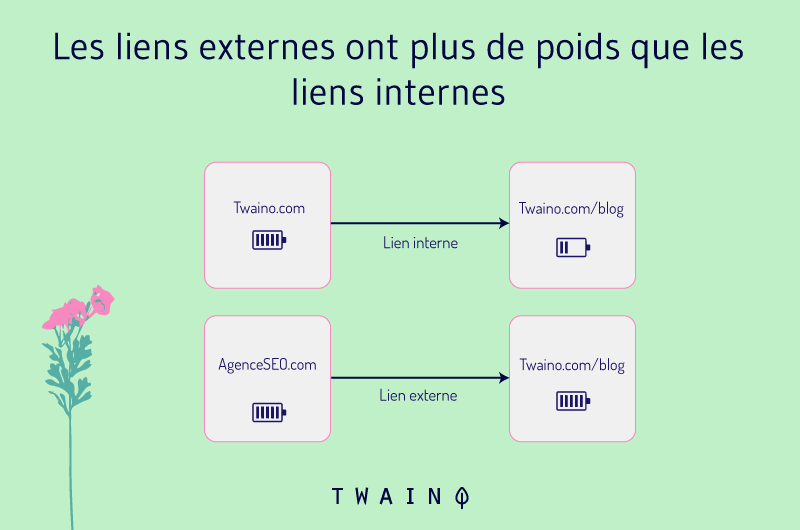
The more links you have from credible sites, the more credible you appear to Google and the more likely they will rank your site well.
Links from other sites send crawlers to your pages. So if another site links to one of your new pages, that page will likely be crawled and indexed much sooner.
And while some of these links may occur naturally, it’s best to take a more proactive approach.
Of course, if you have any experience in link building, you know that earning links is often easier said than done.
But if you create a promotion strategy ahead of time, you’ll know exactly what to do once your new content is published and you’ll have a better chance of getting that page indexed quickly.
If you can find places to syndicate your content, it’s one of the easiest ways to ensure an audience for every new piece of content you publish.
Syndication is the process by which your content is republished on other sites, with credit given to your site.
In some cases, site owners even find syndicated versions of their content outranking their own site.
But when done right, it can help you improve your reach and earn more links from your posts.
Conclusion
In general, orphan pages hurt your rankings and cost you money, so it’s important to find and fix them.
In this article, we have developed not only the general concept of orphan pages, but also the right ways to manage them.
If you have other ways to avoid orphan pages on the site, feel free to share them with us in comments.
See you soon!

