
If you are a website or web page developer, you should know that it is essential for you to have the robots.txt file.
Many may wonder what I mean, especially if they have no knowledge of SEO or in web development.
Remember that this is a very important text file. It is involved in the management of requests for exploration of your site by Google crawlers.

This mini guide will allow you to have a more in-depth knowledge of what is meant by robots.txt.
You will also find the process of creation and implementation, but also the best practices for its handling.
Chapter 1: What is a robots.txt file and what is its purpose?
In this first chapter, you will learn the real meaning of robots.txt as well as their usefulness.
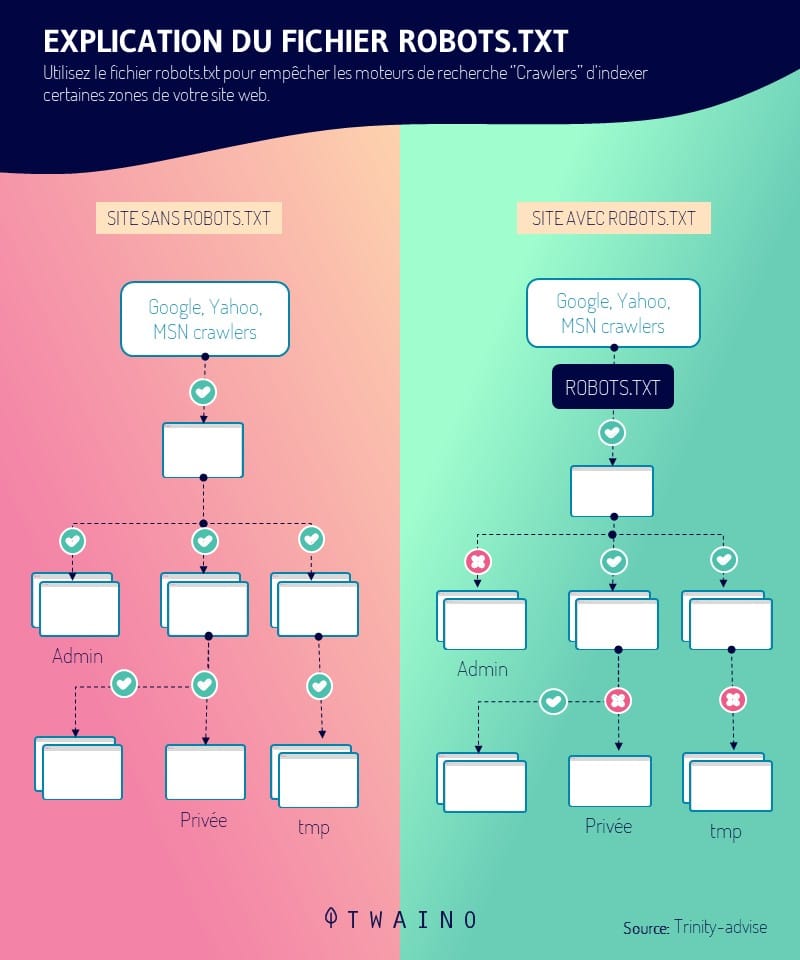
1.1 What is a robots.txt and what does it look like?
The robot.txt represents a computer data. More precisely, it is a text file that is used on websites to tell crawlers (mainly those of search engines) how they should crawl the pages of websites.
More technically, they are part of an exclusion protocol and represent the standards that govern how crawlers browse the web, access and index content
It is included in the root of your website so that if your website address is: www.monsite.com, the URL leading to the robots.txt is www.monsite.com/robots.txt.
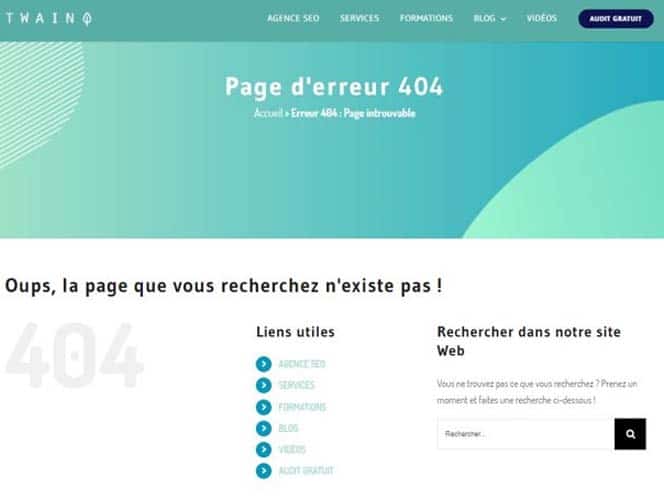
- If robots.txt is present on your site, when you enter the URL www.monsite.com/robots.txtyou will see a window like :

On the other hand, if it is not present you will get an error message like 404.
1.2) What is the importance of the robots.txt file for a website?
As you may have guessed, robots.txt play an important role in your website by controlling the way it is browsed by the crawlers
It can thus :
- Prevent Google robots from browsing duplicate content;
- Refuse the display of a private part of the site in the SERPs;
- Refuse the display of internal search results pages of the site in Google Search Results;
- Refuse the indexation by search engines of certain elements of your site;
- Specify a crawl time to avoid overloading your site;
- Optimize the use of your server’s resources by preventing bots from wasting your site’s resources.
Now that you know what a robot.txt is and why it is important, let’s see how to create and implement it on a website
Chapter 2: How to create the robots.txt file for your website?
After explaining the process of creating the robots.txt file for a website, I will explain how to proceed to know if its file works or not.
2.1. Create the robots.txt file for your website
The robots.txt file can be created manually or generated automatically on most CMS like WordPress
We will go through these two creation processes. However, before you try to install the robots.txt file, make sure your site does not already have one
2.1.1. Creating your own robot.txt file
To create your own robot.txt file, you need a text editor (this is a program for creating and editing text files) Notepad and sublime text are examples.
Once you have chosen and downloaded your editor, to create your robot.txt file, you will need to follow certain rules. These rules concern:
The location and format of the robots.txt file
- Your file must be named robots.txt ;
- You are allowed only one robots.txt file on your site;
- Your robots.txt file must be located at the root of your site.
The syntax of your robots.txt file
- The robots.txt file must respect the UTF-8 encoding;
- The file is composed of one or more groups of instructions;
- The rule, one instruction per line and per empty line must be respected.
The commands (instructions or directives) to use to build your robots.txt file:
- User-agent it is the first line and it contains the name of the search engine robot. You can consult the robots database to find the name of the robot you want to ban;
- Disallow: In this command, you have to put the URL of the page or the folder you want to forbid the access to the robots;
- Allow : Allows you to authorize the exploration of a URL or a folder by robots;
- Sitemap this optional instruction allows you to indicate to Google robots, the parts that they must explore on your site.
For more information on these different rules, please visit the google support.
Here is an example of robots.txt file

source anthedesign
Once your text file is ready, the next step would be to install it on your website.
To do this, simply access the root of your site from your FTP client software and drop the robots.txt file in the www directory
Source Web-eau
That’s it, your robots.txt file is created and installed on your site.
2.1.2. Creating the robots.txt file with WordPress
In WordPress, a robots.txt file is automatically created for your site
If you are using a WordPress site, then simply type in the search bar the URL of your site followed by: /robots.txt to check for the robots.txt file.
Anyway, you can create your own robots.txt file using plugins like SEO YOAST or ALL IN SEO.
To create your robots.txt file with SEO YOAST, you just need to search, download and install the SEO YOAST extension in WordPress.
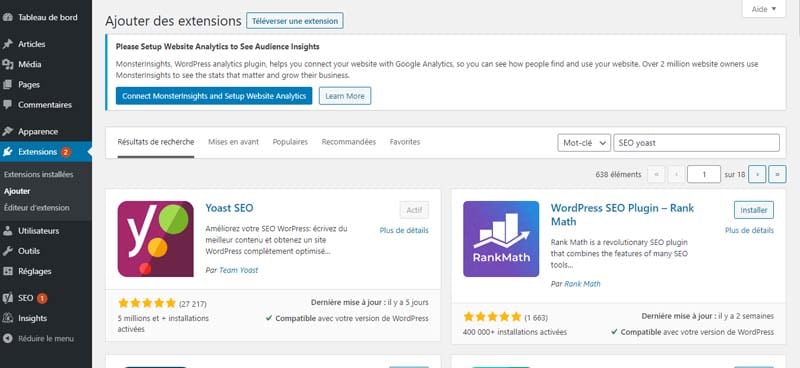
Then activate it and go to the extension settings.
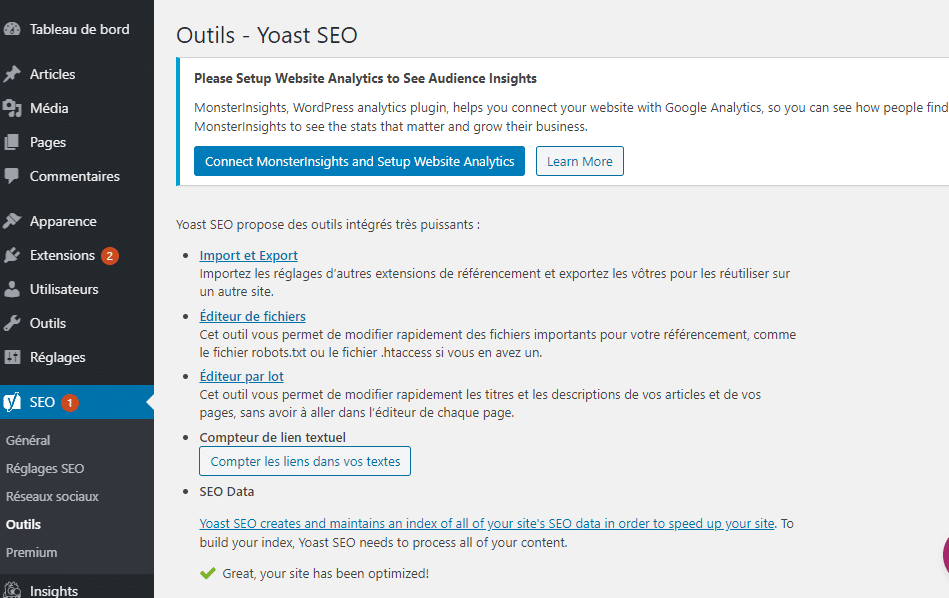
Once in the settings select “file editor” and wait for the new window to load.
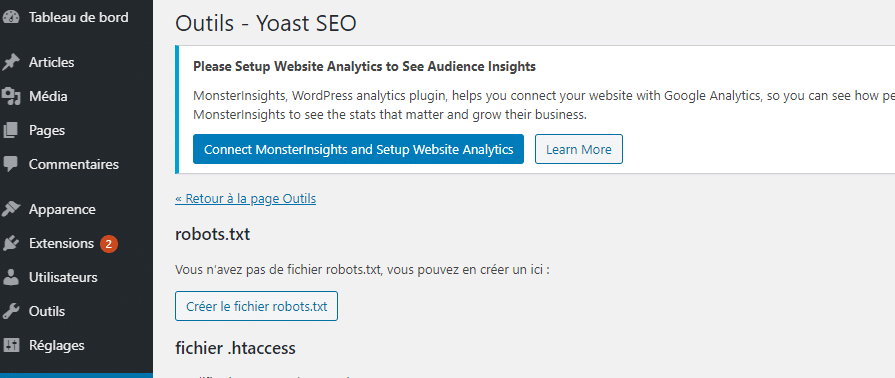
Choose “create robots.txt file.
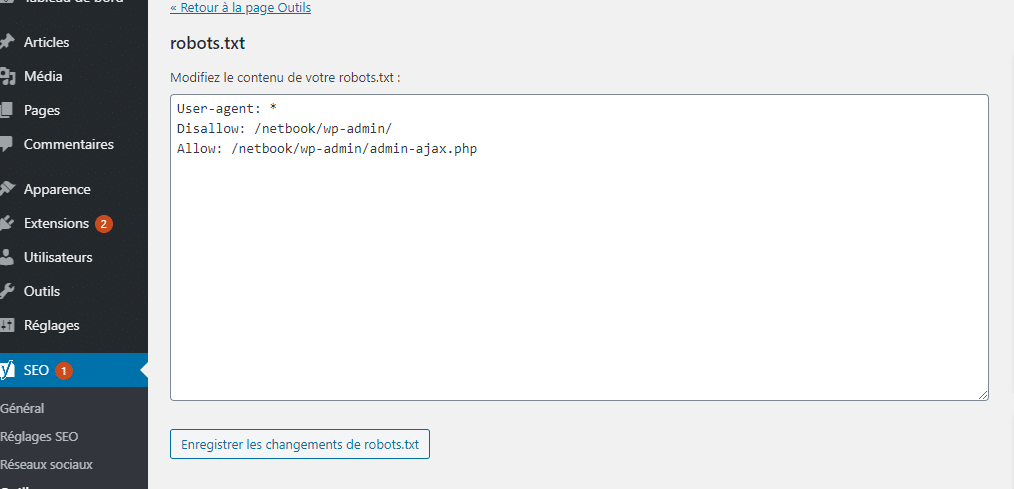
Finally edit the content of the virtual robots.txt created by WordPress and save the changes.
You can also create the robots.txt file from the ALL In SEO extension. To do this, you must first download, install and activate the extension.

Then, once you are in the extension options, select module management and wait for the new window with the different modules to load.
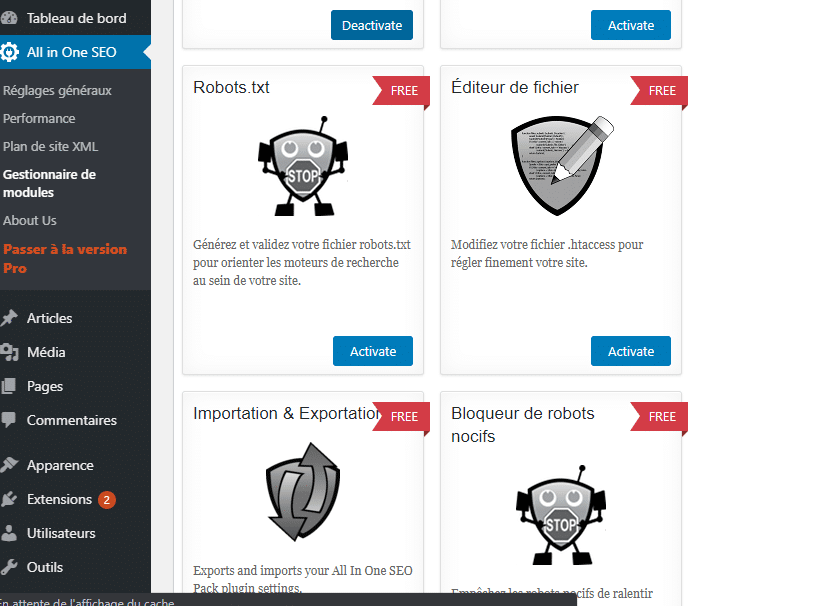
Look for the robots.txt module and press activate to set up your robots.txt file.
Now you have created your robots.txt file manually or by using a plugin on WordPress
The next step would be to check if the created robots.txt file works.
To do this, you will need to do a test.
2.3. test your robots txt file.
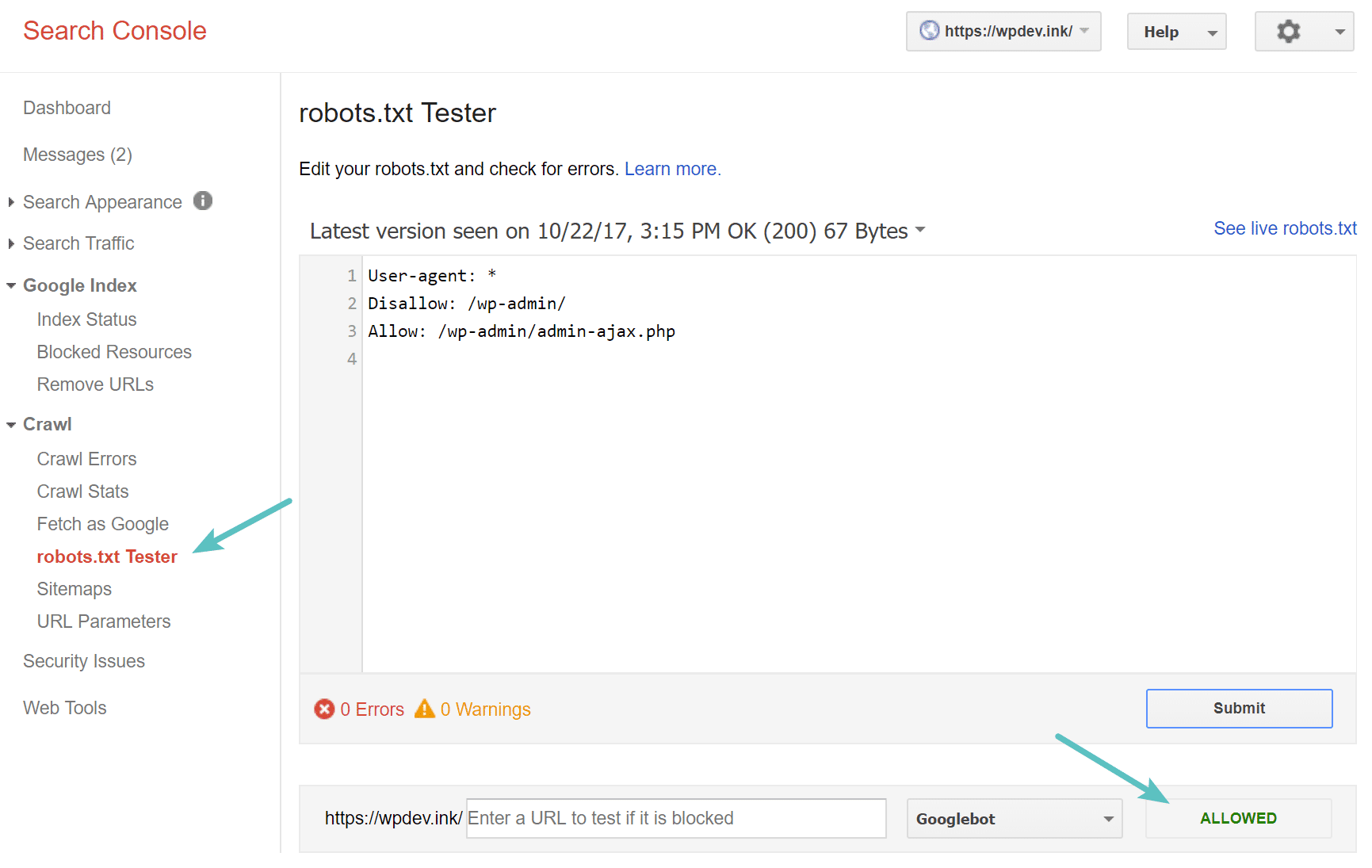
To test your robots.txt file, simply follow the instructions from Google instructions on this subject
Specifically, you need to go to your search console and click on the crawl tab then on robots.txt test
You then have access to a window that allows you to submit your robots.txt file to Google.
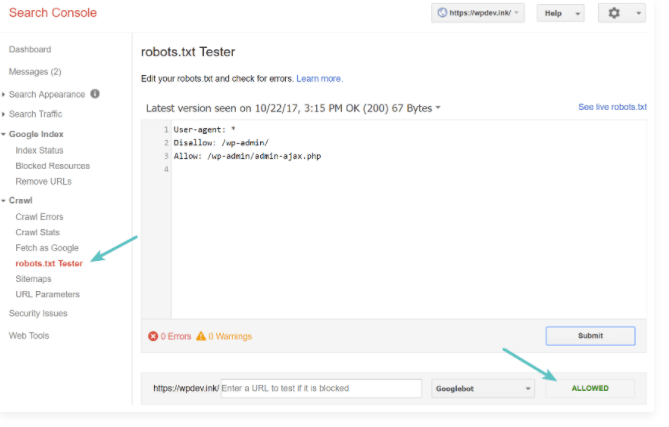
source kinsa
Don’t forget to integrate the modifications to your file before uploading it to your site’s server.
Chapter 3: The different uses of the robots.txt file.
Here we will see some uses of the robots.txt file. But first, we’ll talk about the ultimate goal of a robots.txt file.
3.1. The purpose of robots.txt
Once you have successfully created and installed the file, it is important to know how to use it
The use of robots.txt files is mainly to deny and allow access to your site to search engine robots
Indeed, the instructions do not have the same operating mode. The service provided differs from one directive to another. However, the operation of instructions can be summarized in two expressions: authorization and refusal.
3.1.1. Authorization
This consists in allowing all web robots to explore all compartments and all web pages of your site. If this is your wish, the presence of the robots.txt file is therefore unnecessary, since the instructions are without missions
Therefore, they can no longer recognize and control the web robots. It is therefore recommended that you refrain from installing the file under these circumstances
On the other hand, in case you already have it, it is simply advisable to remove it. However, if you want to keep it, you should leave it completely empty without any changes.
3.1.2. Refusal
You may want to prohibit all web robots from exploring your site. To achieve this, the installation of the robots.txt file is important. It is a question here of integrating a single instruction: to block the access of your site to all the web robots.
Now that we know the two final objectives of a robots.txt let’s see how to use it to allow and deny access to robots.
3.2. how to use the robots txt file to block access to an entire site?
To prevent robots from crawling your site for any reason, simply add to your robots.txt file the code :
User agent : *
Disallow: /
In this code, the asterisk means: All robots and the slash in disallow means that you want to prevent access to all pages of your site’s domain.
3.3. how to use the robots.txt file to prevent a single robot from crawling your site?
If you want to exclude the exploration of your site by the crawler of a specific search engine, you just have to use the code :
User-agent : name of the robot
Disallow :/
Using this code will allow you to apply the exclusion rule only to a specific robot.
3.3) How to prevent robots from exploring a folder or a file on your site?
To prevent robots from exploring a file or a folder on your site, simply use the code :
User agent: *
Disallow : name of the folder
3.4. How to use the robots. Txt to allow a file that is contained in an unauthorized folder.
To ask the crawlers to index a content that is in a folder that you don’t want the crawlers to explore entirely you just have to use the code :
User agent : *
Disallow : path of the unauthorized folder
Allow : path of the file to explore
Beyond these uses, note that the robots.txt file can be modified and you can also choose to exclude certain pages from the robots.txt file
3.5. How to modify a robots.txt file ?
It must be admitted that it is very rare to modify an already installed robots.txt file. However, it is possible to modify it. Except that you must expect a reconfiguration of your site.
If you have created and installed your file manually, you must then open your robots.txt file at the root of your site and make the various changes you would like to make. Once finished, you must save the changes and save your file.
On the other hand, if you use a CMS like WordPress, you can modify your file using the SEO YOAST and All In SEO plugins by following the instructions in part 2.2.
3.6. How to exclude certain pages from your robots.txt file?
As it is possible to modify this file, you should know that it is also possible to exclude certain pages from your robots.txt database. It is a matter of subtracting certain URLs authorized to access the search engine of your site.
To do this, you must go back to the root of your site. You must be able to access the contents of the file. Then go to the Disallow statement folder. It is this directive that constitutes the memory of all authorized URLs.
It is then up to you to identify the undesirable addresses that you wish to extract from your database. Simply uncheck them and they are now considered as unauthorized URLs
Now that you know everything about the use of robots txt, I will present you in the chapter some good practices to adopt.
Chapter 4 : Some good practices to have for your txt file
To use your robots.txt files properly:
- In the configuration of your robots.txt file, make sure that only pages that have no value are blocked
- Make sure you do not block the JavaScript and CSS files of your site;
- Always do a test after setting up your robots.txt file to make sure you haven’t blocked anything by accident;
- Always place the robots.txt file in the root directory of your site;
- Make sure you name your file “robots.txt” ;
- Add the location of your sitemap to your robots.txt file.
And that’s it, we’re done with the things to keep in mind when it comes to handling your robots.txt file.
In a nutshell
Robots.txt are text files installed in the root of websites to control the crawling and indexing of their content by various search engine robots.
In this article, you will find out not only how they can be useful for your site, but also how to use them to get the most out of them.


{kind=link}