
Un rastreador o robot web (también conocido como «crawlers», «spiders» o «arañas web») es un programa automatizado que navega metódicamente por la red con el único propósito de indexar páginas web y su contenido. Estos robots son utilizados por los motores de búsqueda para rastrear las páginas web y renovar su índice con nueva información. De este modo, cuando los usuarios realizan una determinada consulta, pueden encontrar fácil y rápidamente la información más relevante.
Cuando realice una consulta en un motor de búsqueda, obtendrá como resultado una lista clasificada de sitios web.
Antes de que estos sitios web aparezcan en las SERP, un proceso conocido como rastreo yindexación se realiza entre bastidores por los motores de búsqueda
El actor principal en el corazón de esta maquinaria es la oruga.
En este caso :
- ¿Qué es un robot o una oruga?
- ¿Cómo funcionan?
- ¿Cuál es su importancia en SEO ?
- ¿Qué es la indexación y qué papel desempeñan realmente los robots?
- ¿Cuál es la diferencia entre los rastreadores web y el raspado web?
Todas estas son preguntas cuyas respuestas nos permitirán entender claramente la definición de rastreador y todo lo que lo rodea.
¡Vamos!
Capítulo 1: ¿Qué entendemos realmente por Crawler o rastreador?
Las unidades funcionales de los motores de búsqueda, rastreadores o robots, están en el centro de la gran mayoría de las acciones e interacciones de la web
Entender la búsqueda en Internet requiere claramente una comprensión profunda de sus conceptos
Por ello, en este capítulo, explicaré los robots o rastreadores con gran detalle.










1.1. Una oruga: ¿Qué es?
Antes de hablar de la oruga en su funcionamiento y aplicaciones, es esencial recordar sus orígenes y dar su verdadero significado.

Dicho esto, he aquí la historia y, a continuación, el verdadero significado del rastreador.
1.1.1. Rastreadores o robots de indexación desde la aparición de la web
Los robots de indexación se conocen ahora con muchos nombres
- Oruga ;
- Robots rastreadores ;
- Arañas ;
- Araña web ;
- Software para motores de búsqueda;
- Y muchos otros nombres.

Originalmente, el primer rastreador se llamaba WWW Wanderer (abreviatura de World Wild Web Wanderer)
Este robot de indexación, diseñado y basado en Perl (un lenguaje de programación estable y multiplataforma), se encargó ya en junio de 1993 de evaluar el crecimiento de la todavía incipiente Internet
Por aquel entonces, el robot Wanderer de la WWW rastreaba Internet en busca de datos que registraba en el índice de la época, el primer índice de Internet: elíndice Wandex
En sus inicios, Wanderer sólo rastreaba servidores web. Poco después de su plena introducción, comenzó a rastrear las URL.
Al contrario de lo que se podría pensar, Wanderer con su índice Wandex no fue el primer motor de búsqueda en Internet. En realidad, se trata del motor de búsqueda archiético desarrollado por Alan Emtage
Sin embargo, con su índice Wandex, Wanderer era definitivamente lo más parecido a un motor de búsqueda web de propósito general como los actuales motores de búsqueda Google y Bing.
Tras el WWW Wanderer, en 1994 apareció el primer navegador web: el Webcrawler. Hoy en día, es el motor de búsqueda (metabuscador) más antiguo que sigue presente y funcionando en Internet.
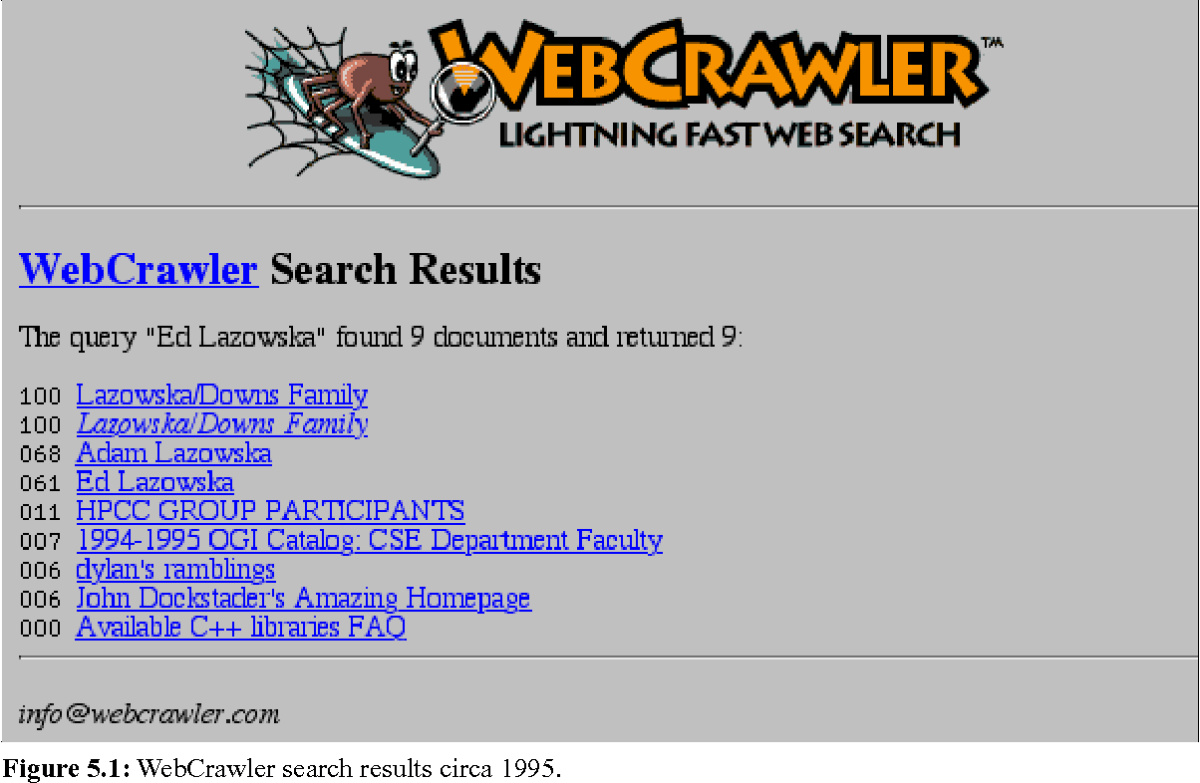
En la constante evolución de la web, se han realizado muchas mejoras y los motores de búsqueda y sus robots de indexación han cambiado y mejorado.
Así pues, se acaba de esbozar la historia de la búsqueda en Internet y de los rastreadores web.
Sin embargo, ¿cuál es el verdadero significado de la palabra rastreador?
1.1.2. Un rastreador: ¿Qué significa realmente?
Llamado así por el motor de búsqueda más antiguo que existe (Webcrawler), crawler es una palabra inglesa que significa literalmente «arrastrarse», «rastrear», «escanear»… Tantas correspondencias oportunas que expresan claramente la esencia misma de los robots de indexación
A riesgo de repetirnos, un robot de indexación es un programa informático, un software que escanea Internet de forma controlada, localizando y analizando páginas web con un propósito específico
Como una araña con su tela, el rastreador explora y analiza la red. Este análisis se refiere a las distintas páginas web, sus contenidos y todas sus ramificaciones
El rastreador, en busca de datos, registrará y almacenará las distintas informaciones recogidas en índices y/o bases de datos
Por lo tanto, es fácil entender por qué a estos robots se les llama también arañas o telarañas.

Estos robots de indexación son, en el 99% de los casos, todavía utilizados por los motores de búsqueda. Permiten a los motores de búsqueda construir índices estructurados y optimizar su rendimiento como motores de búsqueda (por ejemplo, la presentación de nuevos resultados relevantes).
En el 1% de los casos restantes, los rastreadores se utilizan para buscar y recopilar información de contacto y de perfil (direcciones de correo electrónico, canales RSS y similares) con fines de marketing.
Para simplificar, tomemos el famoso ejemplo de la bibliotecaria. En este ejemplo, el bot del motor de búsqueda es un bibliotecario encargado de inventariar todos los libros y documentos (sitios web y páginas) de una biblioteca enorme y completamente desorganizada (la web).
El bot tiene que crear una tabla resumen (índice del buscador) que permita a los lectores (usuarios de Internet) acceder rápida y fácilmente a los libros (información) que buscan
Para ordenar y clasificar (indexar) los libros (sitios web) por áreas de interés y luego hacer un inventario, el bibliotecario (rastreador) tendrá que pedir cada libro, su título, su resumen y el tema que trata
Pero, a diferencia de una biblioteca, en Internet los sitios web están conectados entre sí mediante hipervínculos, que son utilizados por los robots para pasar de un sitio o página web a otro.
En resumen, esto es lo que es el rastreador y de lo que es responsable. Sólo queda saber cómo funciona.
1.2) ¿Cómo funciona un robot de indexación o crawler?










El rastreador es ante todo un programa, scripts y algoritmos cuyo conjunto de tareas y comandos están definidos de antemano
Como un buen soldadito, sigue asiduamente las instrucciones y funciones predefinidas en su código de forma automática, continua y repetitiva
Al navegar por la web a través de los hipervínculos (de los sitios web existentes a los nuevos), las arañas indexan tanto el contenido como las URL. Analizan las palabras clave y los hashtags y se aseguran de que el código HTML y los enlaces de los sitios indexados sean recientes.
Como dice el famoso proverbio africano: «Es al final de la cuerda vieja cuando se teje la nueva
Como la web está en constante crecimiento, es imposible evaluar con precisión el número total de páginas en Internet
Al realizar sus tareas, los rastreadores comienzan la exploración a partir de una lista de URLs conocidas
Así, el rastreo sigue un patrón muy simple
Antiguas URLs conocidas => páginas web indexadas => hipervínculos => nuevas URLs a rastrear => páginas web a indexar => así sucesivamente..
Lejos de trabajar al azar, los robots de indexación obedecen a ciertas reglas que les confieren una meticulosa selectividad en la elección de las páginas a indexar, así como en el orden y la frecuencia de la indexación de estas páginas.
Así, un robot de indexación determina la página que se indexará primero según
- El número de vínculos de retroceso el número de backlinks que conducen a la página (el número de páginas externas a las que está enlazada esta página);
- La vinculación interna (los enlaces entre las distintas páginas de un mismo sitio web);
- Tráfico de la página (el número de visitantes de la página en cuestión);
- Elementos que atestiguan la calidad, la pertinencia y la frescura de la información contenida en la página (el sitemap, el meta-tagsmeta-tags, el URLs canónicass, etc.);
- El robots.txt (el archivo que contiene los grupos de directivas para los bots) ;
- Etc.
Dependiendo del motor de búsqueda, estos factores se consideran de forma diferente. Por lo tanto, es comprensible que no todos los robots de los motores de búsqueda se comporten de la misma manera.
1.3. ¿Cuáles son los diferentes tipos de orugas?
Compartiendo los mismos principios generales de funcionamiento, los rastreadores difieren principalmente en su enfoque y alcance
Sí, además de los rastreadores de los motores de búsqueda, hay muchas otras categorías de rastreadores.










1.3.1. Bots de los motores de búsqueda
Estos rastreadores son sin duda los primeros rastreadores que han existido
Se les conoce como searchbots. Un nombre que se justifica por el hecho de que están diseñados con la intención de servir a los motores de búsqueda en la optimización de su campo de acción y especialmente de su base de datos.
Entre los más famosos se encuentran los siguientes robots de búsqueda:
- Googlebot de Google: el robot de búsqueda más utilizado en la red y el que tiene el índice más rico;
- El Bingbot de Bingel motor de búsqueda de Microsoft;
- Slurpbot de Yahoo;
- La araña Baidu del motor de búsqueda chino Baidu
- El bot de Yandex de Yandexel motor de búsqueda ruso
- El DuckDuckBot de DuckDuckGo ;
- El Facebot de Facebook ;
- El rastreador Alexa de Amazon ;
- Y más.
1.3.2. Rastreadores de escritorio
Se trata de mini rastreadores con una funcionalidad muy limitada. Su limitada área de competencia se ve compensada por su coste relativamente insignificante
Son bots que pueden ejecutarse directamente desde un ordenador portátil o PC personal y sólo pueden procesar una cantidad muy pequeña de datos.
1.3.3. Rastreadores web personales
Una categoría de rastreadores diseñados para empresas y que se utilizan, por ejemplo, específicamente para proporcionar información sobre la frecuencia de uso de determinados hashtags/palabras clave
Algunos ejemplos son:
- El VoilaBot de la empresa de telecomunicaciones Orange
- El OmniExplorer_Bot de la empresa OmniExplorer
- Y muchos otros.
1.3.4. Orugas comerciales
Son soluciones algorítmicas que se ofrecen por suscripción a las empresas que necesitan personalmente un rastreador. Los rastreadores actúan como herramientas de pago que permiten a las empresas ahorrarse la enorme cantidad de tiempo y dinero necesaria para diseñar su propio rastreador.
Algunos ejemplos de software de rastreo de pago son los siguientes:
- Botify ;
- SEMRush ;
- Oncrawl ;
- Arrastre profundo ;
- Etc
1.3.5. Bots del sitio web en la nube
La particularidad de estos rastreadores de sitios web reside en que son capaces de almacenar los datos recogidos en la nube
Esto supone una gran ventaja frente a otros rastreadores que se limitan a almacenar la información en servidores locales de pago de empresas informáticas.
Además, la accesibilidad a los datos y a las herramientas de análisis es mucho mejor. Ya no hay que preocuparse por la localización y la compatibilidad logística.
1.4. ¿Qué debemos recordar sobre la indexación (Google) en la búsqueda en Internet?
La parte de la web que es de acceso público y que realmente es rastreada por los robots sigue siendo indeterminada
Se calcula aproximadamente que sólo el 40-70% de la red está indexada para la búsqueda, es decir, varios miles de millones de URL.
Si tomamos el ejemplo del bibliotecario anterior, la acción de prospectar, clasificar y catalogar los libros (sitios y páginas web) de la biblioteca representó la indexación de la búsqueda en Internet.

Indexación es, por tanto, un término práctico que designa todos los procesos por los que el rastreador escanea, analiza, organiza y ordena las páginas de los sitios web antes de proponerlas en las SERP
Es un aspecto decisivo de referencia naturalya que consiste en la inserción y consideración de las páginas web en el índice del motor de búsqueda
Aunque esta primera etapa de referenciación orgánica es decisiva, dista mucho de ser suficiente para la aparición y el posicionamiento de las páginas web en las SERP.
Gracias a las continuas actualizaciones del índice de Google, y especialmente con la implementación de Cafeínala indexación de Google ha evolucionado más
Como resultado, los nuevos contenidos y/o las nuevas páginas web se indexan rápidamente y su aparición en las SERP es directa.
Aparte de esto, es crucial recordar que las páginas y el contenido de su sitio web no serán indexados por el Googlebot hasta que los haya encontrado. Esta etapa crucial de la indexación de Google es controlable.
En efecto, existen varias soluciones para que sus recursos sean visibles para Google. El propio motor de búsqueda ofrece alternativas interesantes y eficaces sobre el tema.
Capítulo 2: Un Crawler en aplicación: ¿Qué hace?
Una vez hechas las presentaciones, vayamos al meollo de la cuestión.
¿Cuáles son las aportaciones, las ventajas y la importancia SEO de los rastreadores?
2.1. En la práctica, ¿cómo funcionan los rastreadores?
Como hemos visto, el comportamiento de los rastreadores está predefinido e integrado en sus líneas de código. Así, los factores que rigen la indexación de las páginas web se ponderan en función de los bots y de la buena voluntad de los motores de búsqueda.
En la práctica, la acción de los robots de indexación se decide en varias etapas.
En primer lugar, los motores de búsqueda deben determinar el objetivo y/o las preferencias de estos bots. Por lo tanto, las políticas de rastreo de los sitios web, en particular los tipos de URL que se van a indexar, se especificarán en la porción de datos que sirve de salvaguarda denominada frontera de rastreo
En un segundo paso, los destinatarios de los rastreadores asignan a sus robots una lista «semilla» que servirá de punto de partida para la indexación. Se trata de una serie de antiguas URLs conocidas o de nuevas URLs a rastrear.
A continuación, los motores de búsqueda añaden al programa de los robots la frecuencia de exploración y tratamiento que debe darse a cada URL.
Por último, los rastreadores están entrenados para respetar las directrices del archivo robots.txt y/o las etiquetas HTML nofollow, a diferencia de los spambots
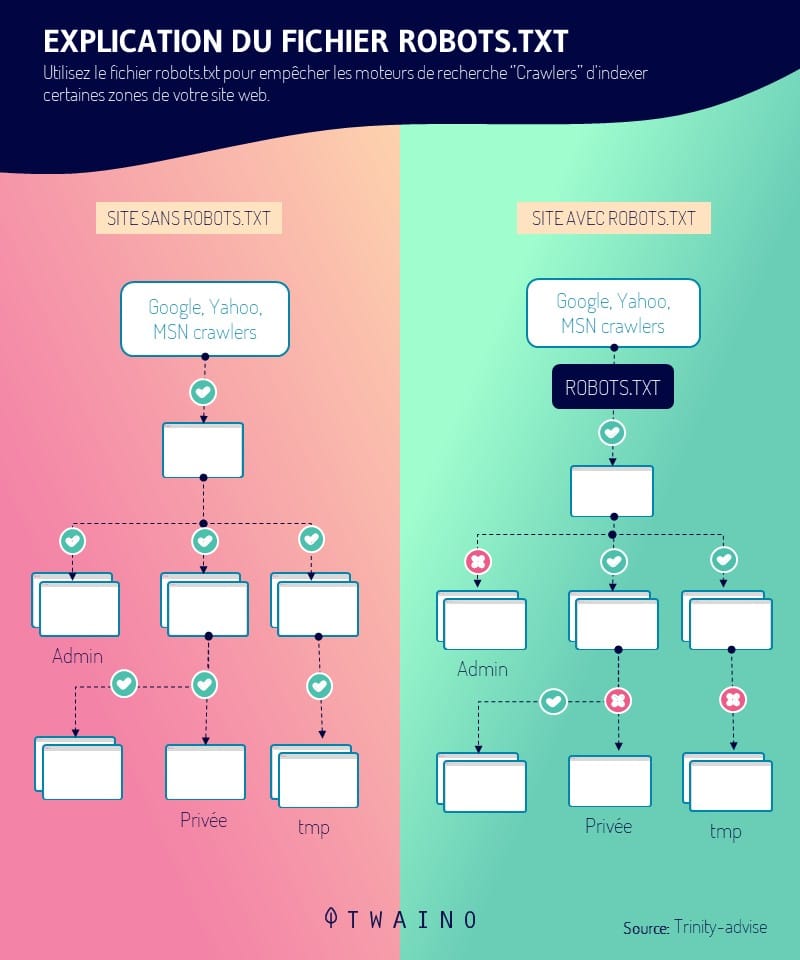
Así, el rastreador de acuerdo con las directrices de la robots.txtprotocolo, se le indicará que evite todo o parte de un sitio web.
2.2. Un robot de indexación: ¿Qué hace?
La oruga en sus aplicaciones ofrece diversas ventajas en muchos ámbitos.
La primera ventaja del rastreador es su la sencillez de uso y su capacidad para garantizar para garantizar una recopilación y un procesamiento de datos continuos y completos.
Su una eficiencia sin precedentes en el rendimiento de sus funciones de exploración e indexación de contenidos web es también una valiosa ventaja
Al realizar la prospección, el análisis y la indexación de la web en lugar de los humanos, los robots ahorran una cantidad increíble de tiempo y dinero.
Desde el punto de vista de SEO (Search Engine Optimization), el rastreador ayuda a aumentar el tráfico orgánico de un sitio web y a destacarse de la competencia
Para ello, proporciona información sobre los términos de búsqueda y las palabras clave más populares.

Además de estas ventajas principales, los rastreadores también son útiles en muchas otras disciplinas, como
- Optimización del e-marketing mediante el análisis de la base de clientes de la empresa;
- La extracción de datos y la publicidad dirigida mediante la recopilación de direcciones públicas de correo electrónico y/o postal de las empresas;
- Evaluación y análisis de los datos de los clientes y de la empresa con el fin de mejorar las estrategias de marketing de la empresa;
- Creación de bases de datos;
- La búsqueda de vulnerabilidades a través de la monitorización continua de los sistemas;
- Y muchos otros.
Capítulo 3: ¿Cuál es la importancia y el papel de los rastreadores en el SEO?










El papel y la importancia de los rastreadores en la indexación ya no se cuestionan. Sin embargo, sus particiones e intereses en la estrategia de SEO siguen siendo un poco confusos hasta ahora.
3.1. El lugar de los rastreadores en el SEO
La importancia de los rastreadores para la referenciación natural está íntimamente ligada a su capacidad para establecer las condiciones necesarias para que un sitio web aparezca en las SERP
El objetivo del SEO es obtener un tráfico orgánico considerable generado por los resultados naturales.
En otras palabras: estar entre los primeros resultados de los motores de búsqueda.

El rastreo y la indexación de las páginas web por parte de los rastreadores es la base para aparecer en los resultados de los motores de búsqueda. En realidad, no basta con aparecer en las SERPs, pero es un paso esencial.
3.¿Cómo ayuda el rastreador web a los expertos en SEO?
La optimización de los motores de búsqueda consiste en mejorar la clasificación de un sitio web en los SERP. Esto se hace optimizando los factores técnicos y no técnicos de la página para estos motores de búsqueda.
Las implicaciones SEO del rastreador web son enormes, ya que su trabajo es indexar su sitio antes de que los algoritmos determinen si merece un lugar en la primera página
Aquí tiene dos (02) consejos para conseguir que indexen sus páginas importantes de forma eficiente:
3.2.1. Vinculación interna
Al colocar nuevos backlinks y enlaces internos adicionales, el profesional de SEO se asegura de que los rastreadores descubran las páginas web a partir de los enlaces extraídos para garantizar que todas las páginas del sitio web acaben en las SERP.
3.2.2. Envío del mapa del sitio
La creación de mapas de sitio y su envío a los motores de búsqueda ayuda al SEO, ya que estos mapas de sitio contienen listas de páginas para rastrear
Los rastreadores podrán descubrir fácilmente el contenido oculto en las profundidades del sitio web y rastrearlo en poco tiempo, produciendo así la presencia de las páginas importantes del sitio web en los resultados de búsqueda.










3.3. Mejores prácticas para mejorar su SEO con rastreadores
La optimización de su estrategia de SEO implica principalmente la optimización de su presupuesto para el rastreo (el presupuesto de rastreo o exploración). Esta es la período de tiempo así como el cantidad de páginas web que los rastreadores pueden explorar y analizar para un sitio web.
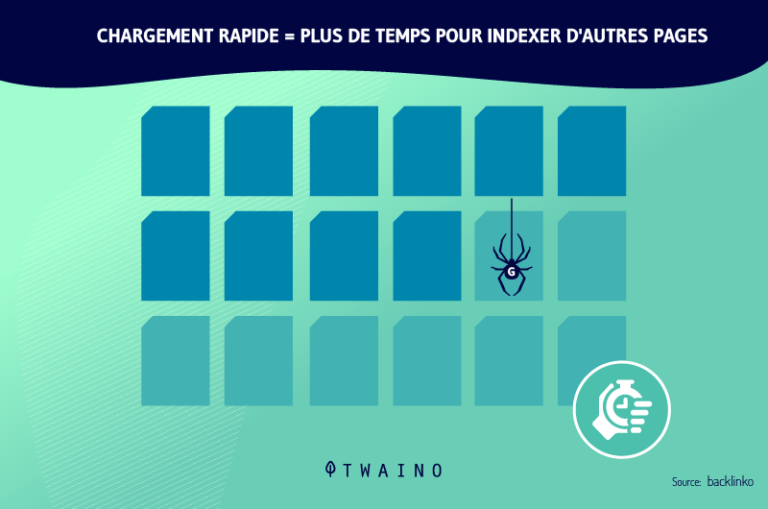
La optimización de este presupuesto implica mejorar la navegación, la arquitectura y los aspectos técnicos del sitio web. Por lo tanto, es aconsejable adoptar, entre otros, el buenas prácticas las mejores prácticas:
- Envíe un sitemap XML a través de GSC (Google Search Console). Esta es una directiva no estándar en robots.txtque guía a los rastreadores hacia las páginas que deben ser rastreadas e indexadas en primer lugar.
- Haga una auditoría completa de la página web. El objetivo es mejorar factores como las palabras clave, la velocidad de carga de las páginas del sitio web, etc.
- Construya una estrategia óptima de netlinking con vínculos de retroceso y una fuerte vinculación interna. Por un lado, consiste en obtener enlaces de otros sitios web que ya están indexados y tienen una alta frecuencia de rastreo. Por otro lado, se trata de enlazar de forma inteligente las diferentes páginas del sitio web para que los rastreadores puedan pasar fácilmente de una página a otra.
- Inspeccione las URL, el contenido y el código HTML con el objetivo de eliminar o actualizar los elementos obsoletos, superfluos, cuestionables o irrelevantes.
- Opte por metaetiquetas explícitas y relevantes, contenido de calidad, URLs canónicas..
- Evite contenido duplicadoevite los contenidos duplicados camuflaje y todas las prácticas de BlackHat SEO.
- Asegúrese de que el servidor que aloja el sitio web es accesible para los rastreadores de los motores de búsqueda.
- Identificar y corregir los distintos elementos que bloquean la indexación de las páginas web.
- Esté al tanto de las actualizaciones y cambios en los algoritmos de los motores de búsqueda para estar siempre al tanto de los criterios actuales de SEO.
3.4. Otros usos de los rastreadores más allá de los motores de búsqueda
Google ha empezado a utilizar el rastreador web para buscar e indexar contenidos y descubrir fácilmente sitios web por palabras y frases clave
Los motores de búsqueda y los sistemas informáticos han creado sus propios rastreadores web programados con diferentes algoritmos. Estos rastrean la web, analizan el contenido y crean una copia de las páginas visitadas para su posterior indexación
El resultado es visible, porque hoy en día se puede encontrar fácilmente toda la buena información o los datos que existen en la web.
Podemos utilizar rastreadores para recoger tipos específicos de información de las páginas web, como
- Reseñas indexadas de una aplicación de agregación de alimentos; Información para la investigación académica
- Información para la investigación académica;
- Estudio de mercado para encontrar las tendencias más populares;
- Los mejores servicios o lugares para uso personal;
- Trabajos corporativos u oportunidades;
- Etc.
Otros casos de uso de los rastreadores son:
- Seguimiento de los cambios de contenido;
- Detección de sitios web maliciosos;
- Recuperación automática de los precios de los sitios web de la competencia para la estrategia de precios;
- Identificar los potenciales superventas para una plataforma de comercio electrónico accediendo a los datos de la competencia;
- Clasificación de la popularidad de los líderes o de las estrellas de cine;
- Acceso a los datos de miles de marcas similares;
- Indexación de los enlaces más compartidos en las redes sociales;
- Acceder a las listas de empleo e indexarlas en función de las opiniones y los salarios de los empleados;
- Comparación de precios y catalogación de códigos postales para minoristas;
- Acceso a datos sociales y de mercado para construir un motor de recomendación financiera;
- Descubrir salas de chat relacionadas con el terrorismo;
- Etc.
Si sabe de Raspado de la webpuede estar confundiéndolo con el rastreo de la web. Ahora veamos la diferencia:
3.5. Web crawler vs Web scraper: Comparación
Al igual que el crawler, el scraper es un robot encargado de recoger y procesar datos en la web. Pero no se equivoque, los crawlers y los scrapers no son el mismo tipo de robots.
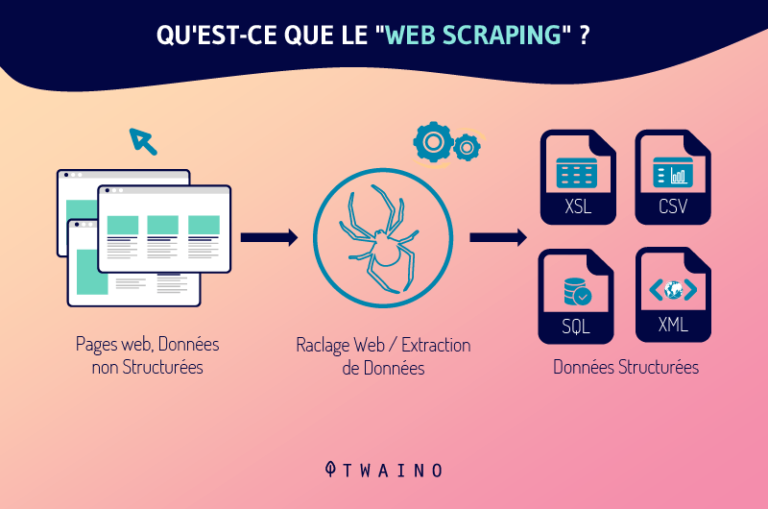
El raspador web es al rastreador web lo que el yin es al yang, el negro al blanco, el mal al bien..
Uno sirve a la ley y a los justos, mientras que el otro sirve a veces al lado oscuro
En realidad, el scraper es un bot programado para localizar y duplicar en su totalidad, normalmente sin autorización, datos específicos pertenecientes al contenido de una página web
Después de extraer estos datos, el rascador los añade tal cual o modificados en las bases de datos para su uso posterior.
Aunque son similares, los dos bots pueden distinguirse claramente por varias características:
- Su función principal
La función del rastreador consiste exclusivamente en explorar, analizar e indexar el contenido de la web a través de la consulta continua de URLs antiguas y nuevas. Los raspadores, por otro lado, sólo existen para copiar datos de sitios web siguiendo URLs específicas.
- Su impacto en los servidores web:
A diferencia de los rastreadores de los motores de búsqueda, que siguen las directrices de los archivos robots.txt y se contentan con los metadatos, los rascadores no siguen ninguna regla.
Veamos un caso rápido del concepto de raspado de la web:
Estudio de caso
- En primer lugar, por refiriéndose a a Condiciones de uso del 7 de junio de 2017, Linkedin establece lo siguiente a través de la sección 8.2.k
«Usted se compromete a no: […] desarrollar, apoyar o utilizar cualquier software, dispositivos, scripts, bots o cualquier otro medio o proceso (incluyendo, sin limitación, rastreadores web, plug-ins del navegador y complementos, o cualquier otra tecnología o trabajo físico) para hacer web scrap de los Servicios o copiar de otra manera los perfiles y otros datos de los Servicios.»
A pesar de ello, en una batalla legal entre Linkedin y una start-up estadounidense llamada HiQ Labs (sobre el uso de prácticas de web scraping para recoger exclusivamente información perteneciente a los perfiles públicos de LinkedIn de los empleados de una empresa), el tribunal dictaminó lo siguiente
Los datos presentes en los perfiles de los usuarios son públicos una vez que se publican en la red y, en este caso, pueden recogerse libremente a través del web scraping.
- En segundo lugar, refiriéndose a fábrica digitalel «web scraping» sería considerado por el artículo 323-3 del Código Penal francés como «Robo de datos». Este artículo dice:
«El hecho de introducir fraudulentamente datos en un sistema de tratamiento automatizado, extraerlos, conservarlos, reproducirlos, transmitirlos, borrarlos o modificarlos fraudulentamente se castiga con cinco años de prisión y una multa de 150.000 euros. Cuando este delito se ha cometido contra un sistema de tratamiento automatizado de datos personales implantado por el Estado, la pena se eleva a siete años de prisión y una multa de 300.000 euros
Ahora le toca a usted sacar su conclusión de este concepto de raspado web.
Capítulo 4: Otras preguntas sobre los rastreadores web
4.1. ¿Qué es un rastreador?
Un rastreador web es un software diseñado por los motores de búsqueda para rastrear e indexar automáticamente la web.
4.2 ¿Qué es el rastreo de Google?
El rastreo es el proceso por el que Googlebot (también conocido como robot o araña) visita las páginas para añadirlas al índice de Google. El motor de búsqueda utiliza un amplio conjunto de ordenadores para recuperar (o «rastrear») miles de millones de páginas en la web
4.3. ¿Cuándo se arrastra?
El rastreo se produce cuando Google u otro motor de búsqueda envía un robot (o araña) a una página o publicación web para rastrearla
Estos rastreadores extraen entonces los enlaces de las páginas que visitan para descubrir otras páginas del sitio web
4.4 ¿Cómo funciona el rastreador de Google?
Los rastreadores web comienzan su proceso de rastreo descargando el archivo robot.txt del sitio web. El archivo incluye mapas de sitio que enumeran las URL que el motor de búsqueda puede rastrear. Una vez que los rastreadores comienzan a rastrear una página, descubren nuevas páginas a través de los enlaces
Así, añaden las URLs recién descubiertas a la cola de rastreo para que puedan ser rastreadas posteriormente. Con esta técnica, estos rastreadores pueden indexar todas las páginas que están conectadas a otras.
Como las páginas cambian regularmente, los rastreadores de los motores de búsqueda utilizar varios algoritmos para decidir factores como la frecuencia de rastreo de una página existente y el número de páginas de un sitio que deben ser indexadas.
4.5. ¿Qué es el antirrastreador?
El anti crawler es una técnica para proteger contra los crawlers o indexadores de su sitio web. Si su sitio web contiene imágenes valiosas, información sobre precios y otra información importante que no quiere que se rastree, puede utilizar etiquetas meta robots.
4.6. ¿Cómo trabaja Google para ofrecer resultados relevantes a las consultas de los usuarios?
Google rastrea la web, clasifica los millones de páginas que existen y las añade a su índice. Así, cuando un usuario realiza una consulta, en lugar de rastrear toda la web, Google puede simplemente rastrear su índice más organizado para obtener resultados relevantes rápidamente.
4.7. ¿Qué son las aplicaciones de rastreo web?
El rastreo de la web se utiliza habitualmente para indexar páginas para los motores de búsqueda. Esto permite a los motores de búsqueda ofrecer resultados relevantes para las consultas de los usuarios.
El rastreo de la web también se utiliza para describir el raspado de la web, la extracción de datos estructurados de las páginas web y similares.
4.8. ¿Cuáles son los ejemplos de Crawler?
Cada motor de búsqueda utiliza su propio rastreador web para recoger datos de Internet e indexar los resultados de la búsqueda
Por ejemplo:
- Amazonbot es un rastreador web de Amazon para la identificación de contenidos web y el descubrimiento de backlinks
- Baiduspider para Baidu ;
- Motor de búsqueda Bingbot para Bing por Microsoft ;
- DuckDuckBot para DuckDuckGo ;
- Exabot para el motor de búsqueda francés Exalead;
- Googlebot para Google ;
- ¡Slurp para Yahoo!
- Yandex Bot para Yandex ;
- Etc.
4.9. ¿Cuál es la diferencia entre el rastreo web y el scraping web?
En generalrastreo de la web es practicada por los motores de búsqueda a través de robots que consisten en rastrear y crear una copia de la página en el índice
A diferencia del gateo raspado de la web es utilizado por un humano, siempre a través de un bot, para extraer determinados datos, normalmente de un sitio web, para su posible análisis o para crear algo nuevo
En resumen
Los rastreadores y la indexación son ahora conceptos cuyo significado e implicaciones usted domina. Recuerde que estos conceptos son el día a día y la esencia misma de los motores de búsqueda
El rastreador, en su función de prospección y archivo de la web, determina la presencia y la posición de los sitios web en los resultados del motor de búsqueda
Sin embargo, los robots de indexación, arañas o como quiera llamarlos, también se utilizan en muchos otros campos y disciplinas
Desde el funcionamiento de los diferentes protagonistas de la búsqueda en Internet hasta las mejores prácticas para su optimización, ahora tiene una idea bastante clara de todo el tema.
Aplique los conocimientos adquiridos de forma inteligente
Comparta con nosotros en los comentarios su experiencia y sus descubrimientos sobre el tema
¡Hasta pronto!

