
El DUST, o URLs diferentes con texto similar, se produce cuando varias URLs de un sitio enlazan con una página del mismo sitio. A menudo se trata de contenidos a los que se puede acceder desde diferentes lugares del mismo dominio o por diferentes medios. También conocido como URLs duplicadas, el DUST confunde a los motores de búsqueda cuando los rastreadores tienen que rastrear e indexar las URLs duplicadas. El DUST reduce la eficacia del rastreo y diluye la autoridad de la página principal.
La creación de contenidos es la principal responsabilidad de los webmasters a la hora de clasificar un sitio web. Aunque lo ideal es crear contenidos únicos, es difícil hacerlo sin contar con los rascadores de contenidos que duplicarán los suyos.
El contenido duplicado representa entre el 25 y el 30% del contenido de la web y no todo es resultado de una intención deshonesta. También puede crearse involuntariamente en un sitio sin que los administradores de la web se den cuenta.
Este es el caso de las URLs diferentes con texto similar (DUST), donde una URL puede duplicarse cientos de veces. La gran mayoría de los sitios web se enfrentan a este problema y sus causas son numerosas.
Pero en términos concretos;
- ¿Qué es el Polvo?
- ¿Cómo aparecen las URL de DUST en un sitio?
- ¿Cuáles son los problemas potenciales de DUST?
- ¿Cómo puedo corregir los problemas relacionados con DUST?
En este artículo, daré respuestas explícitas a estas preguntas para desmitificar DUST. También descubriremos cómo evitar que se produzca este problema en un sitio.
Así que ¡siga con nosotros!
Capítulo 1: ¿Qué es el DUST y qué problemas causa en términos de SEO?
El contenido duplicado es uno de los 5 principales problemas de SEO a los que se enfrentan los sitios y el DUST es sólo una forma de contenido duplicado.
Este capítulo analiza la definición de DUST y los problemas de SEO que puede causar a un sitio.
1.1. DUST: ¿Qué es?
El contenido duplicado es común en la web y Google lo define como el contenido del mismo sitio o de otros sitios que coincide con otro contenido o es casi similar.
A través de esta definición, podemos ver que el contenido duplicado se produce a dos niveles: en el mismo dominio o entre varios dominios.

Cuando se produce en el mismo sitio, puede adoptar la forma de un contenido que aparece en diferentes páginas de un dominio o de una página a la que se puede acceder en múltiples URL.
En este último caso, el contenido duplicado se denomina DUST. Mientras que otras formas de contenido duplicado están relacionadas con la creación de contenidos, el DUST es más el resultado de la duplicación de URLs.

Esta duplicación de URLs es muy común y suele ser el resultado de un problema técnico al que todos los sitios web pueden enfrentarse en algún momento. Las siguientes URLs apuntan todas al mismo sitio y son un ejemplo de DUST.
- www.votresite.com/ ;
- yoursite.com ;
- http://votresite.com ;
- http://votresite.com/ ;
- https://www.votresite.com;
- https://votresite.com.
Aunque estas URLs parecen ser las mismas y se dirigen a la misma página, las sintaxis no son las mismas y esto puede causar problemas a un sitio web
1.2. ¿Por qué es un problema el DUST o la duplicación de la URL?
A diferencia de otras formas de contenido duplicado, el DUST no perjudica directamente el SEO de un sitio web. De hecho, Google entiende perfectamente que esta duplicación no es maliciosa.

Sin embargo, el DUST plantea tres problemas principales con los motores de búsqueda. Los motores de búsqueda son incapaces de :
- Identificar qué URLs incluir o excluir de su índice;
- Conozca la URL a la que asignar métricas de enlace como la confianza, la autoridad, la equidad..
- Identifique las URL que deben clasificarse en los resultados de búsqueda.
Para entender estas cuestiones, veamos cómo funcionan los motores de búsqueda. Consiguen mostrar los resultados de la búsqueda a través de tres funciones principales:
- Arrastrándose ;
- Indexación;
- Clasificación.

El rastreo de la web es el proceso mediante el cual los motores de búsqueda descubren contenidos web nuevos y recientemente actualizados. Envían robots llamados arañas que se mueven de URL en URL en un sitio.
Cuando varias URLs conducen a la misma página, las arañas las consideran como URLs diferentes y rastrean cada una de ellas. Entonces descubren que el contenido de estas diferentes URLs es el mismo y lo tratan como contenido duplicado.
En el transcurso del rastreo, los robots pueden añadir los nuevos recursos interesantes que encuentran al índice, una enorme base de datos de URLs.
Aunque esto puede ocurrir, las arañas evitan indexar la misma página varias veces y se centran en indexar sólo aquellas páginas que ofrecen un contenido único. Así, las arañas pueden tener que elegir qué URLs indexar.

Pueden incluir en el índice cualquier URL que no sea la correcta o la que usted desea indexar.
Además, es a partir del contenido indexado que los motores de búsqueda eligen el contenido relevante cuando un usuario realiza una consulta. Por lo tanto, es obvio que una página que no existe en el índice no puede aparecer en los resultados de la búsqueda.
1.¿Cómo puede el DUST perjudicar su SEO?
Las URL duplicadas pueden perjudicar el SEO de un sitio de varias maneras.
1.3.1. Reducir la eficiencia del rastreo
El hecho de que las URL duplicadas apunten todas a la misma página y que los robots sigan rastreando cada una de ellas puede reducir la eficacia del rastreo de los robots.
Esto se debe a que Google asigna un presupuesto de rastreo a todos los sitios. Este presupuesto representa el número de URL que los rastreadores pueden seguir en un sitio. Cuantas más URLs haya, más probable será que se agote el presupuesto de rastreo.

Sin embargo, los rastreadores no podrán rastrear todas las páginas cuando se agote el presupuesto y es posible que no puedan rastrear todas las páginas relevantes del sitio.
Por lo tanto, es crucial que los propietarios de los sitios trabajen para optimizar el presupuesto de rastreo para permitir que los rastreadores sigan todas las URLs relevantes.
1.3.2. Pérdida de tráfico y dilución del patrimonio
Cuando los motores de búsqueda indexan una URL con una estructura extraña entre las URL duplicadas, los usuarios pueden tener dudas cuando aparece en los resultados de la búsqueda. Esto puede conducir a una pérdida de tráfico a pesar de estar bien clasificado.
También puede ocurrir que los robots indexen varias URLs entre los duplicados. Incluso en este caso, las URL se consideran de forma diferente. Cada uno de ellos tiene diferentes autoridades y clasificaciones.

Esto diluye la visibilidad de todos los duplicados. Esto se debe a que cada una de las URL duplicadas puede captar backlinks mientras que estos enlaces pueden apuntar todos a la URL principal.
1.4. ¿Cómo aparecen las URL duplicadas?
Los webmasters no duplican las URLs intencionadamente. El DUST suele producirse cuando los sitios utilizan un sistema que crea múltiples versiones de la misma página. Esta situación es común en los sitios de comercio electrónico, especialmente en las fichas de productos.
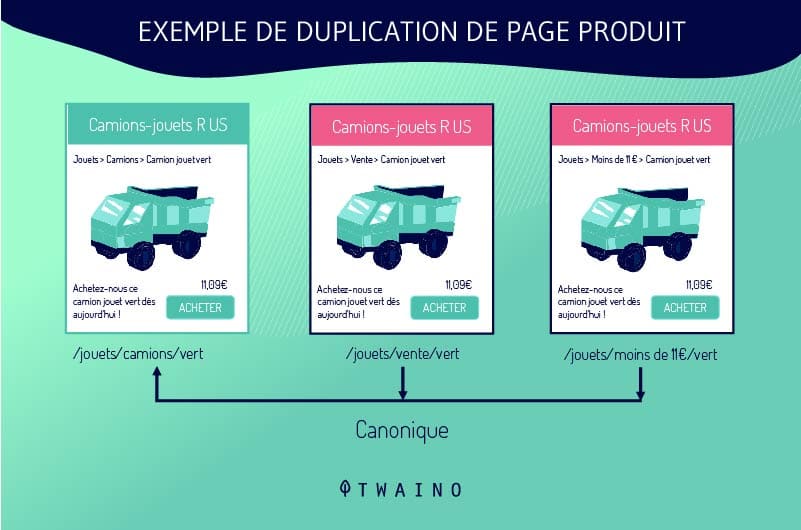
Las fichas de los productos están configuradas de forma que los clientes puedan elegir entre diferentes tamaños o colores mientras permanecen en la misma página. Por lo tanto, el sistema de gestión de contenidos genera múltiples URLs de DUST que enlazan con una sola página.
Por ejemplo, si un sitio ofrece una camisa azul en tres tallas diferentes, el sistema puede generar las siguientes URL:
- shoponline.com/blueshirt-A ;
- shoponline.com/blueshirt-B;
- shoponline.com/blueblueblouse-C.
Las URL duplicadas también son el resultado de los filtros que ofrecen los sitios para facilitar la búsqueda a sus visitantes. Todas las combinaciones generan enlaces DUST, que los motores de búsqueda lamentablemente ven de forma diferente.
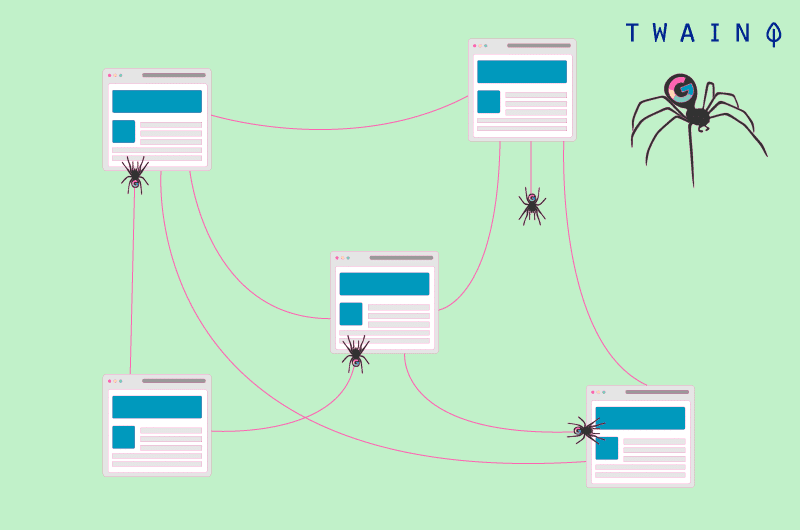
Los sitios también crean URLs duplicadas cuando publican una versión imprimible de una página. Del mismo modo, las URL duplicadas también proceden:
- URLs dinámicas;
- Versiones antiguas y olvidadas de una página;
- Identificación de la sesión.
Tenga en cuenta también que las URL son sensibles a la presencia o ausencia de la barra (/) al final. Por ejemplo, Google tratará de forma diferente a example.com/page/ y a example.com/page.
Así, estas dos URLs serán tratadas como URLs duplicadas aunque accedan al mismo contenido.
Capítulo 2: Cómo identificar las URL de DUST y cómo corregirlas
La corrección de las URLs de DUST puede tener un efecto significativo en el SEO de un sitio web. En este capítulo, descubriremos cómo detectar estas URLs y las diferentes formas en que pueden ser tratadas.
2.1. Cómo encontrar URLs duplicadas
Es esencial detectar las URLs DUST para corregir este problema. Afortunadamente, existen consejos y herramientas en línea que le permiten comprobar si hay URLs duplicadas en un dominio.
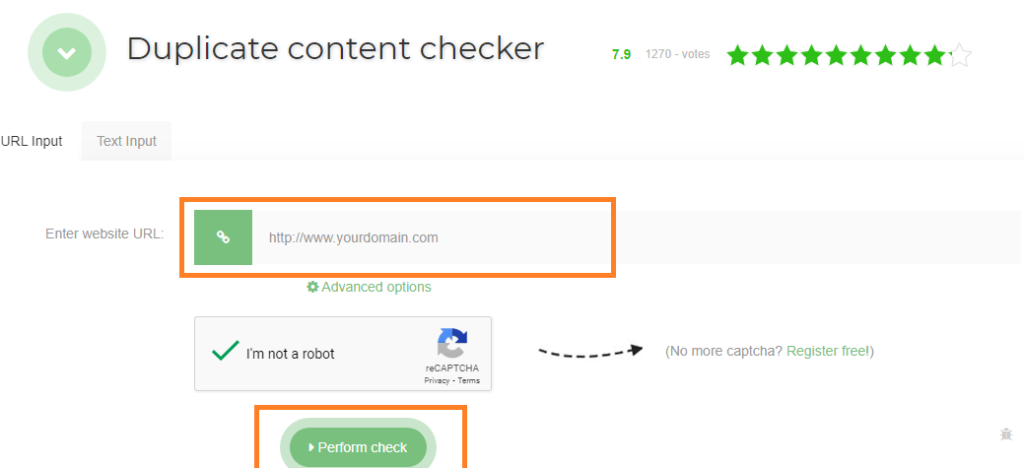
2.1.1. Herramientas de comprobación de URLs duplicadas
Entre las herramientas para comprobar las URL duplicadas, sugiero Seo Review Tools. Sólo tiene que introducir la dirección URL deseada en la barra reservada para ello y hacer clic en «Realizar verificación». La herramienta le mostrará el número de duplicados de la URL introducida.
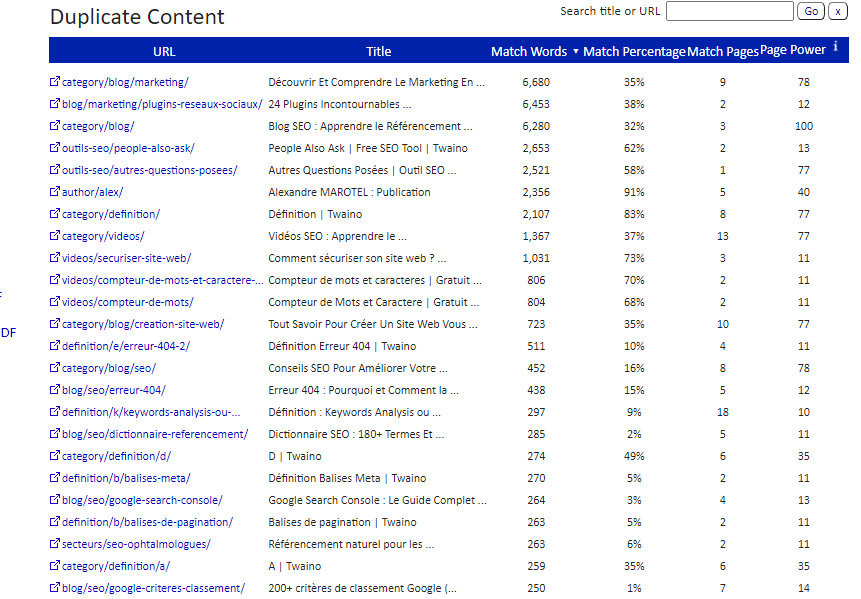
Siteliner es también una potente herramienta para encontrar URLs duplicadas en un dominio. Examina su dominio y le muestra un informe de los enlaces duplicados en su sitio.
Para utilizar esta herramienta, simplemente introduzca su dominio en la barra de búsqueda. Cuando Siteliner le muestre el análisis de su sitio, haga clic en «contenido duplicado» para mostrar las URLs duplicadas.
2.1.2. Utilizando el operador de búsqueda site:example.com intitle :
También puede comprobar si hay URLs duplicadas en su sitio utilizando los operadores de búsqueda site:example.com intitle: «your keyword». Google le mostrará las URLs de su dominio (ejemplo.com) que contienen la palabra clave buscada.
Sólo tiene que mirar las URL que le muestra Google para ver qué URLs enlazan con la misma página. Ahora que puede encontrar URLs duplicadas en su sitio, pasemos a las acciones correctivas que puede tomar.
2.2 Cómo arreglar las URL de DUST
2.2.1. Redirección 301
Laredirección 301 es una forma de enviar a los usuarios y a los motores de búsqueda a una dirección diferente de la que solicitan permanentemente. En el caso de las URL de DUST, consiste en redirigir los duplicados a la URL original.
De este modo, las diferentes URLs que pueden tener una clasificación diferente se agrupan en una sola y dejan de competir. Además, todas las URLs pasan su equipo completo a la URL principal.

Esta URL se beneficia así del poder de referenciación de sus duplicados. Naturalmente, esto tendrá un impacto significativo en la referenciación de la página en cuestión. Tenga en cuenta, sin embargo, que la redirección 301 no elimina el DUST duplicado.
2.2.2. La etiqueta rel=canonical
La etiqueta rel=canonical sigue siendo una de las mejores formas de transferir el potencial de referenciación de una página duplicada a otra. Es una etiqueta HTML que simplemente indica a los motores de búsqueda qué URL deben añadir a sus índices.

Google define la URL canónica como la URL más representativa de un grupo de contenido duplicado. Esta URL es la que los rastreadores seguirán regularmente para optimizar el presupuesto de rastreo de un sitio. Los demás serán visitados con menos frecuencia.
Google y otros motores de búsqueda atribuyen todo el potencial SEO de las URL duplicadas a la URL canónica. La etiqueta rel=canonical se añade a la cabecera de una página HTML.
Los motores de búsqueda consideran las otras páginas como duplicados de la URL canónica y no las hacen desaparecer. Esto es muy ventajoso, sobre todo porque seguro que no quiere que se eliminen todos los duplicados.
2.2.3. Uso de meta robots
El uso de los meta robots es tan sencillo como eficaz a la hora de evitar que las páginas aparezcan en los resultados de las búsquedas. Consiste en añadir las etiquetas Noindex y Nofollow al código HTML de una página.

La etiqueta Noindex indica a los motores de búsqueda que no desea que añadan una URL a sus índices y, por tanto, que no la muestren en los resultados de la búsqueda.
Basta con añadir la etiqueta Noindex a las URL duplicadas para evitar que compitan con la URL principal.
La etiqueta Nofollow indica a Google que no siga un enlace y que no transmita su autoridad a las páginas a las que enlaza. Así, las arañas ignorarán todos los enlaces que incluyan la etiqueta Nofollow.
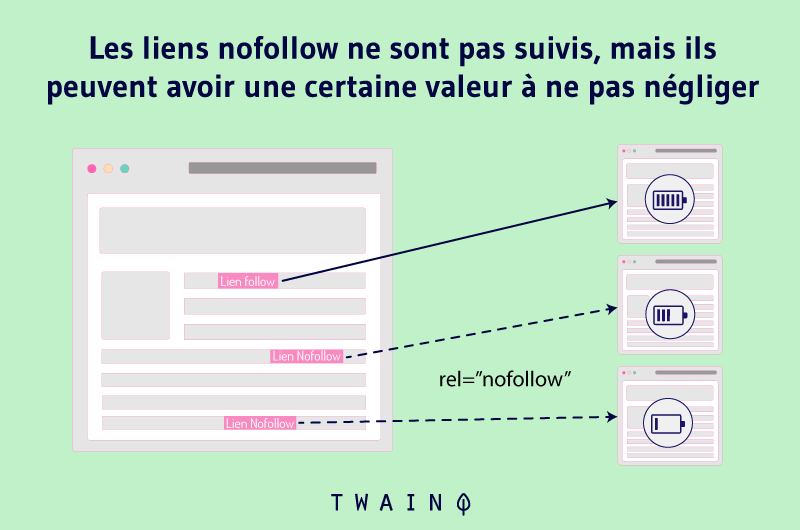
Por lo tanto, añadir esta etiqueta a las URL duplicadas puede ayudarle a corregir los problemas relacionados con la duplicación de URL.
2.2.4. Configuración en Google Search Console
Insertar etiquetas canónicas y metas bot a cientos de páginas DUST suele ser mucho trabajo. Afortunadamente, la configuración de Google Search Console puede ser parte de la solución a las URLs DUST.
2.2.4.1. Cómo configurar la versión de la URL de su sitio
Definir la dirección de un dominio también puede ayudar a resolver los problemas de DUST. Los administradores de sitios web pueden establecer una preferencia para su dominio en esta herramienta y especificar si las arañas deben rastrear determinadas URL.
En lugar dehttp://www.votresite.com, pueden especificar quehttp://votresite.com es la dirección de su dominio. Observe la ausencia de www y lo mismo ocurre con los protocolos HTTP y HTTPS con la ausencia de S.
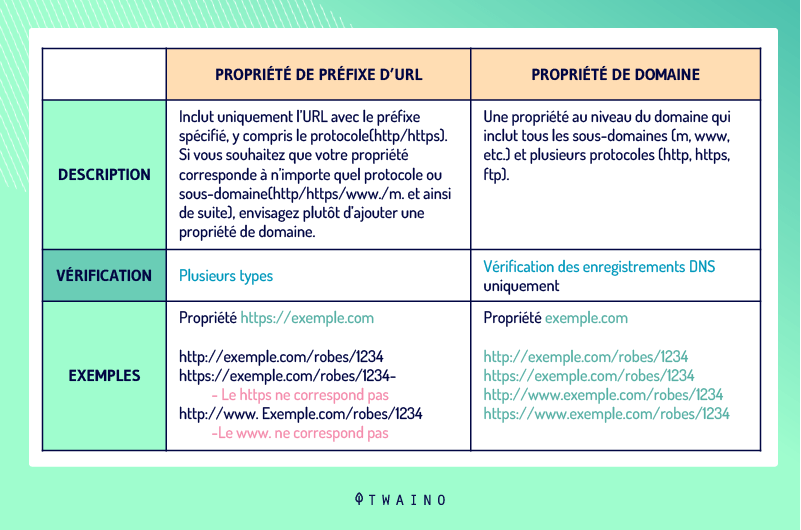
Para proceder a la configuración de la versión de la URL de su sitio, vaya a Google Search Console y elija «Añadir propiedad»
2.2.4.2. Gestión de los parámetros de la URL
La configuración de los ajustes de la URL en Google Search Console le permite especificar los ajustes de la URL que debe ignorar. Sin embargo, debe tener cuidado de no añadir URLs incorrectas que puedan dañar su sitio.
Para ello, haga clic en Crawl en la herramienta y haga clic en «Configurar los ajustes de la URL». El botón «Configurar los ajustes de la URL» le permite introducir sus ajustes.
Fuente: seerinteractive
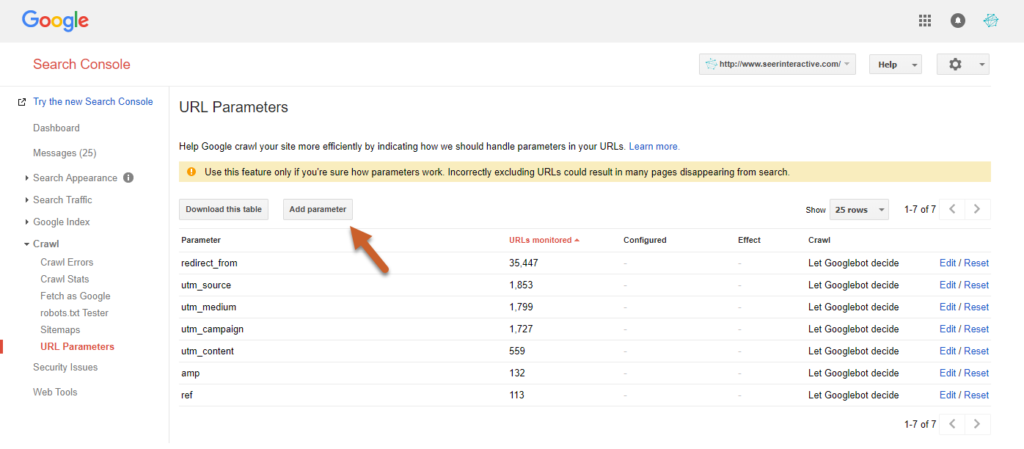
Fuente: seerinteractive
Para guardar la configuración, seleccione si la configuración cambia o no la forma en que los usuarios verán el contenido
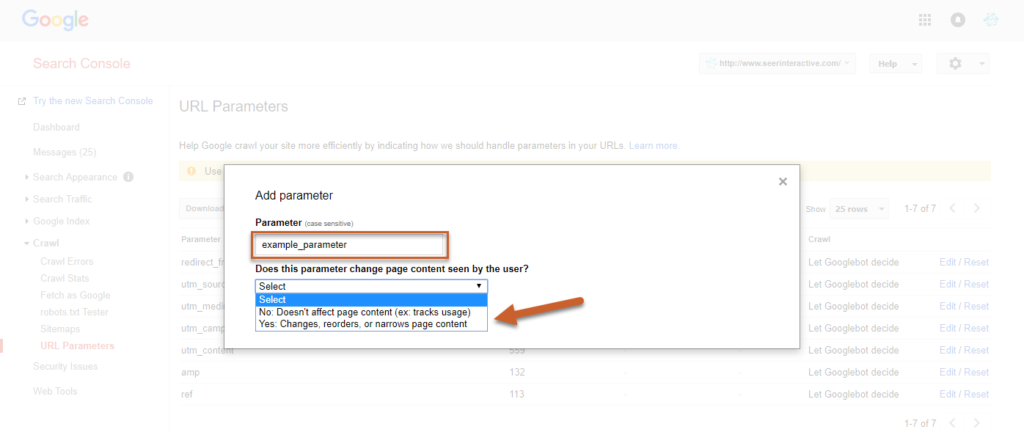
Fuente: seerinteractive
En este punto, elija SÍ para definir cómo puede afectar el parámetro al contenido.
2.2.4.3. Declarar URLs pasivas
La gestión de los parámetros de las URL también permite establecer ciertas URL como pasivas para que los robots de Google las ignoren mientras rastrean un sitio.
Esta es probablemente la técnica más eficaz para eliminar las URLs desordenadas de los resultados de búsqueda.
Se recomienda aplicar esta técnica temporalmente mientras su equipo puede añadir etiquetas canónicas y configurar la redirección 301 para los duplicados.
Para declarar pasivas algunas de sus URLs, sólo tendrá que seguir los mismos pasos y hacer clic en NO antes de guardar. Como resultado, dejarán de aparecer en las SERP. Sin embargo, esta técnica no está exenta de inconvenientes.

A diferencia de la etiqueta canónica, la URL principal que se mantiene después de definir los duplicados en la configuración de Google Search Console no se beneficia de ninguna de estas últimas en términos de SEO.
Sin embargo, los problemas no surgen cuando las URL marcadas pasivamente son nuevas o tienen muy poca autoridad de página. Por lo tanto, le sugerimos que compruebe la autoridad de las páginas que desea añadir en los ajustes.
Para ello puede utilizar, por ejemplo, la herramienta de verificación Ahrefs. Cuando la autoridad de una página es alta, no debe marcar su URL como pasiva o perderá valiosos beneficios de SEO.
Capítulo 3: Otras preguntas frecuentes sobre DUST
Este capítulo está dedicado a las preguntas que se hacen a menudo sobre las URL de DUST.
3.1) ¿Cómo puedo evitar las URLs duplicadas?
Aunque hay URLs de DUST que son inevitables en algunos casos, muchos de los duplicados pueden evitarse. Los administradores de sitios web deben utilizar siempre un formato de URL coherente para todos los enlaces internos de sus dominios.
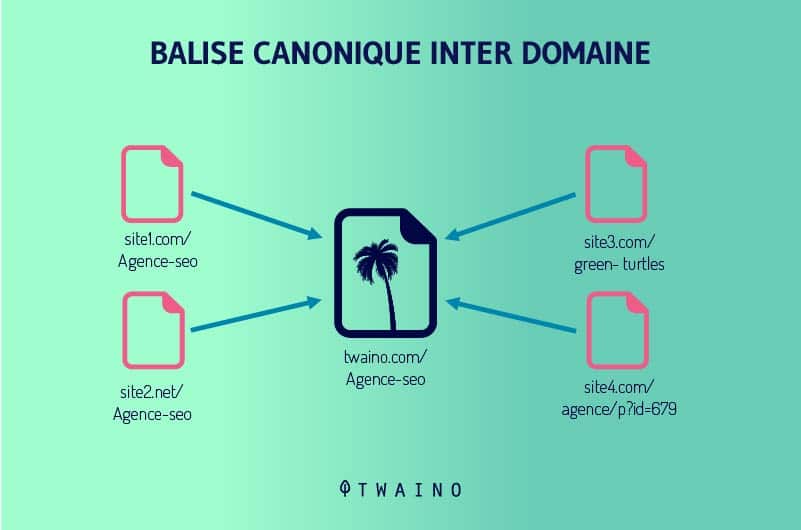
Por ejemplo, un webmaster debería definir la versión canónica de su sitio web y asegurarse de que todos los que añaden enlaces internos a su sitio web siguen este formato.
Cuando la versión canónica del sitio en cuestión es www.example.com/, todos los enlaces internos deben ir ahttp://www.example.com/ en lugar de ahttp://example.com/. La diferencia fundamental es la presencia de (www) en la versión canónica del sitio.
3.2. ¿Se pueden utilizar todas las estrategias anteriores para DUST al mismo tiempo?
En realidad, no existe una solución única para tratar las URL duplicadas. Las soluciones mencionadas anteriormente tienen sus ventajas y desventajas. Por ejemplo, la redirección 301 puede reducir la eficacia del rastreo.
Es el mismo principio para la etiqueta canónica. En efecto, los robots exploran de todos modos las URL duplicadas para identificar la URL canónica con el fin de indexarla. En cuanto a los meta robots, no transmiten la autoridad de las URL duplicadas a la URL original.

En cuanto a la declaración de las URL pasivas en la configuración de Google Search Console, esto es específico de Google y no afecta a otros motores de búsqueda.
Por lo tanto, el problema persiste en otros motores de búsqueda como Bing si ya no es el caso de Google.
En vista de ello, es razonable tratar de utilizar todas estas soluciones de forma adecuada para cubrir todos los problemas potenciales. Sin embargo, debe analizar cada una de estas soluciones para determinar cuáles son las que mejor se adaptan a sus necesidades.
3.3. Qué es una URL dinámica
El uso de URLs dinámicas es una de las principales causas de DUST. En general, la URL dinámica se genera a partir de una base de datos cuando un usuario envía una consulta de búsqueda.

El contenido de la página no cambia cuando un usuario quiere elegir el color de un artículo en una tienda online, por ejemplo. Las URL dinámicas suelen contener caracteres como: ?, &, %, +, =, $.
En cambio, las URL estáticas no cambian y no contienen ningún parámetro de URL. Estas URL no causan problemas durante la exploración de un sitio, como es el caso de las URL dinámicas.
3.4. ¿Cuál es el parámetro de la URL?
Los parámetros de las URL son una de las causas de las URL duplicadas. Todavía llamados variables URL, los parámetros URL son las variables que vienen después de un signo de interrogación en una URL.
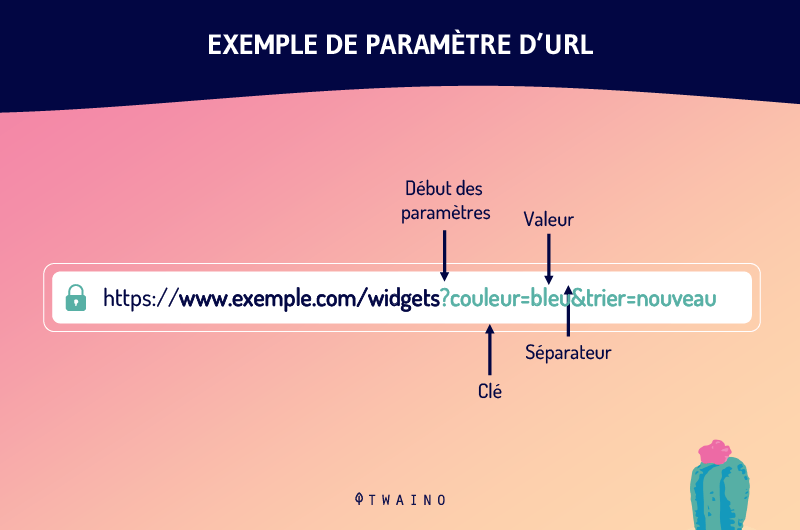
Son las piezas de información que definen las diferentes características y clasificaciones de un producto o servicio. También pueden determinar el orden en que se muestra la información a un espectador.
Los casos de uso más comunes para los parámetros de la URL incluyen
- Filtrado – Por ejemplo, ? tipo=tamaño, color=reg o ? rango de precios=25-40
- Identificar – ? product=big-reg, categoryid=124 o itemid=24AU
- Traducir – Por ejemplo, ? lang=fr, ? language=de.
3.5. Cuál es el ID de la sesión
Los sitios web a menudo quieren hacer un seguimiento de la actividad de los usuarios para poder añadir productos a un carrito de la compra, por ejemplo. La forma de hacerlo es dar a cada visitante un identificador de sesión.
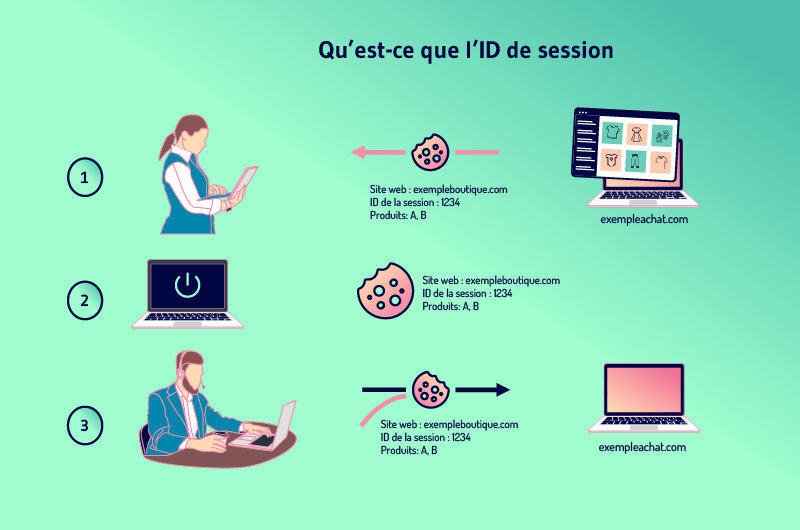
La sesión no es más que el historial de lo que un usuario hace en un sitio y el ID es específico para cada visitante. Para mantener la sesión cuando un visitante abandona una página para ir a otra, los sitios web necesitan almacenar el ID en algún lugar.
Para ello, los sitios web suelen utilizar cookies que almacenan la identificación en el ordenador del visitante.
Pero cuando un visitante ha desactivado previamente el almacenamiento de cookies, el ID de sesión puede ser transferido del servidor al navegador como un parámetro adjunto a la URL de la página.
Esto significa que todos los enlaces internos del sitio tienen el identificador de sesión añadido a su URL. De este modo, se crean nuevas URL a medida que el visitante visita más páginas. Estas nuevas URLs son duplicados de la URL principal y por lo tanto crean el problema de DUST.
3.6. ¿Penaliza Google las URL duplicadas?
Google no penaliza el contenido duplicado ni las URL duplicadas, y los empleados de Google lo señalan una y otra vez. John Muller, por ejemplo, declaró:
«No tenemos una penalización por contenido duplicado. No degradamos un sitio por tener suficiente contenido duplicado.«
Sin embargo, Google está trabajando para desalentar la duplicación que resulta de la manipulación y está haciendo ajustes en sus clasificaciones.
Aunque se podría pensar que las penalizaciones no se refieren implícitamente a las URLs DUST, sí que afectan al SEO de un sitio web como se ha comentado anteriormente
Conclusión
En definitiva, el DUST es un problema común con el que se encuentran la mayoría de los sitios web. Es un conjunto de URLs que dan acceso a la misma página en un dominio.
En la mayoría de los casos, el DUST no causa grandes problemas para el SEO de un sitio. Sin embargo, los errores técnicos que conducen a la duplicación de miles de URL de páginas agotan el presupuesto de rastreo de un sitio y pueden afectar a sus esfuerzos de SEO.
Afortunadamente, estos problemas pueden evitarse y la duplicación de URLs puede corregirse:
- Redirección 301;
- Configuración de los meta robots;
- La etiqueta rel=canonical
- La definición de las URL pasivas en la configuración de Google Searche Console.
Corregir las URL de DUST puede llevar bastante tiempo y requiere una planificación cuidadosa. Por lo tanto, se aconseja al webmaster que evite en lo posible las situaciones de duplicación de URL.
Y ahora, díganos cuál de las formas mencionadas en este artículo le ha ayudado ya a corregir las URLs duplicadas.

