En el ámbito del SEO, el término Scraping se refiere a una estrategia empleada por los SEO o los profesionales del marketing digital para recopilar y utilizar contenidos o datos de otros sitios web. El scraping web se considera una estrategia de SEO de sombrero blanco. Permite a los SEOs raspar automática y rápidamente información o datos de la web para su análisis con el fin de desarrollar / mejorar una estrategia de marketing. La práctica de esta técnica requiere el uso de herramientas o programas informáticos específicos.
La recopilación de datos de los sitios web solía ser una práctica muy complicada y estaba reservada a los desarrolladores web experimentados. Pero desde la automatización del «web scraping» con la participación de herramientas de alto rendimiento, la práctica de la minería de datos en Internet se realiza ahora de forma eficiente y por minutos.
En este artículo, explicaré el concepto de «Scraping» al tiempo que me ocuparé de proporcionarle algunas herramientas de automatización del scraping web para facilitar sus próximas prácticas de scraping.
Capítulo 1: Definición, utilidad y los diferentes tipos de raspado
El «scraping» es un proceso de recogida de datos de la web que suele realizarse de forma automática mediante herramientas diseñadas para ello. En esta sección, hablaré principalmente del significado del concepto de «chatarra» haciendo hincapié en sus usos en el ámbito del marketing web.
1.¿Qué significa el concepto de «chatarra»?
Antes de avanzar en este desarrollo, es importante aclarar una confusión común que se produce en relación con el término «web scraping».
De hecho, el término «Scraping» se escribe con una sola «p» y no «Scrapping» que tiene un significado diferente fuera de nuestro marco. Sin embargo, no es raro ver que la gente confunda estos dos términos en los círculos francófonos.
La ortografía correcta de «raspar» proviene del verbo inglés «to scrape» que significa «la acción de raspar o raspar una parte» de algo.
El término «scrapping», que no se utiliza en el contexto de la extracción de contenidos web, procede del verbo «to scrap» y significa literalmente «abandonar, deshacerse». Por lo tanto, el «scraping» web significa «raspado».
Se trata de una práctica de SEO que consiste en succionar automáticamente el contenido existente de los sitios web para su uso interno.
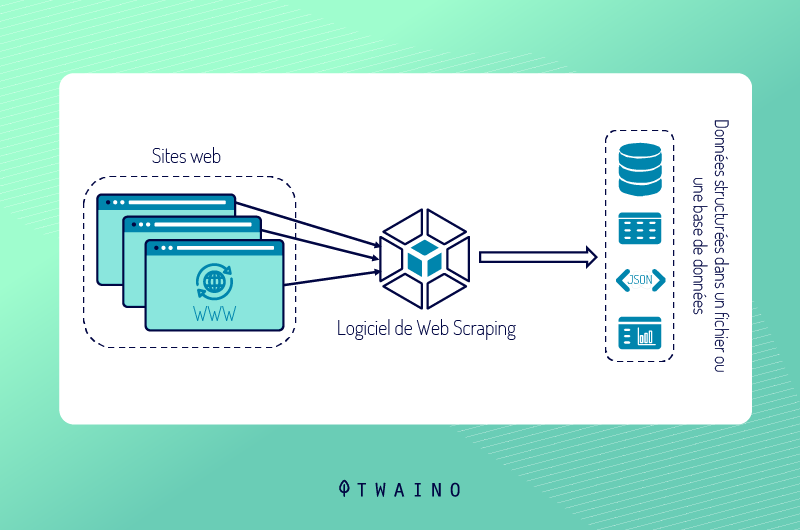
Para ello, los SEO utilizan bots que rastrean los sitios web y extraen automáticamente el contenido
Los recursos web que se suelen raspar incluyen:
- Textos ;
- Imágenes
- Vídeos
- Código
- Etc.
En concreto, el «web scraping» es el proceso de extracción de una gran cantidad de datos e información que puede utilizarse en otros sitios web
En general, existen dos formas de raspar la web: el raspado manual y el automático.
- Raspado manual: Este método consiste en copiar y pegar datos e información en una base de datos. Es un método que requiere mucho tiempo y sólo puede aplicarse a pequeñas cantidades de datos
- Raspado automático: Este método es el más común y utiliza diferentes herramientas como expansores y software para la recogida de datos
1.2. ¿para qué sirve el raspado?
Lo más importante que hay que tener en cuenta al hablar de scraping es que se trata del conjunto de prácticas que permiten raspar contenidos o datos bien estructurados de la web.
El scraping es una estrategia muy inteligente que puede utilizarse para muchos fines. Aparte del uso turbio que algunos profesionales del marketing hacen de él copiando y plagiando contenidos de otros sitios web para conseguir un puesto en las páginas de resultados de búsqueda de Google, la práctica del scraping ofrece varias ventajas en el sector del marketing digital.
En el ámbito del marketing, algunas personas lo utilizan, por ejemplo, para la inteligencia competitiva
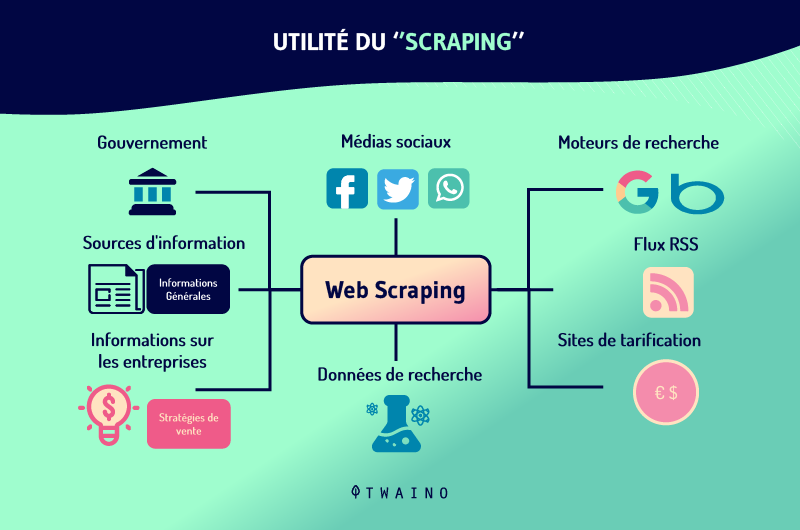
De hecho, el scraping le da una gran ventaja sobre sus competidores. Le permite recoger información y datos sobre sus sitios para analizar y comparar sus estrategias con las suyas. Esto es útil para mejorar su estrategia de marketing.
Por ejemplo, un vendedor electrónico puede utilizar el raspado de la web para ver y comparar los productos de las tiendas de la competencia con los suyos propios
El raspado de la web es también una estrategia muy eficaz para la investigación de mercado. En este caso, se utiliza para construir información y datos para analizar la eficiencia de un mercado y su valor financiero.
En el ámbito del turismo, Google utiliza el scraping de la mejor manera y recoge datos de sitios de comparación de precios para mostrar a sus usuarios los precios de los vuelos y los hoteles
1.3. Los diferentes tipos de raspado
Existen varios tipos de raspado, entre ellos
1.3.1. Raspado de pantalla
El scraping de pantalla es el tipo de scraping que se centra exclusivamente en la extracción de contenidos y datos de una pantalla.
1.3.2. Informe de minería
Se trata de un tipo de scraping que consiste en extraer los datos de un informe en formato de archivo de texto.
1.3.3. Raspado de la web
El raspado de páginas web es la técnica de extracción de contenidos o información de los sitios web. El resto de este desarrollo se dedicará exclusivamente al uso del raspado web
1.4. Las diferentes etapas del raspado
Sea cual sea el tipo de raspado, el uso o la práctica siempre respeta tres pasos esenciales, a saber
1.4.1. Buscando
Esta es la fase de la solicitud en la que la extensión del navegador o el robot rascador utilizado simplemente identifica y descarga las páginas web que se van a analizar.
Se trata de las distintas formas en que el programa utilizado rastreará los distintos sitios a los que se dirige con el fin de almacenar las URL para el tratamiento de los datos.
1.4.2. Parsing
Esta etapa también se denomina procesamiento. Después de que el programa haya rastreado los sitios y descargado las URL, sigue la etapa de análisis y extracción.
Para un procesamiento más automático, se utilizan selectores CSS o XPath para procesar y extraer los datos esenciales con mayor precisión.
1.4.3. Almacenamiento
El programa de raspado utilizado se encarga de recuperar, estructurar y exportar los contenidos y datos raspados para guardarlos en un formato de su elección. Por ejemplo, puede guardarlos en una tabla de valores o en una base de datos.
1.5. Los diferentes tipos de rascadores
La web ha experimentado una evolución muy repentina y las técnicas y medios de desarrollo también se han democratizado
A medida que la web se ha desarrollado, también lo han hecho los medios para llevar a cabo el scraping. En la actualidad existen varias formas de realizar el raspado de la web de forma automatizada.
Descubra aquí los diferentes tipos de scrapers que puede utilizar para extraer datos de la web y cómo funcionan.
1.5.1. Uso de copiar y pegar para el raspado
Copiar y pegar es un método de raspado manual. Aunque se tiende a restarle importancia, es una técnica bastante sencilla y muy eficaz, sobre todo cuando los datos que hay que extraer son pequeños.
Con la ayuda de copiar y pegar, puede copiar una tabla completa de Wikipedia y pegarla en una hoja de cálculo en su lugar de una manera muy rápida. 1.5.2. Uso de Linkclump para raspar enlaces y títulos
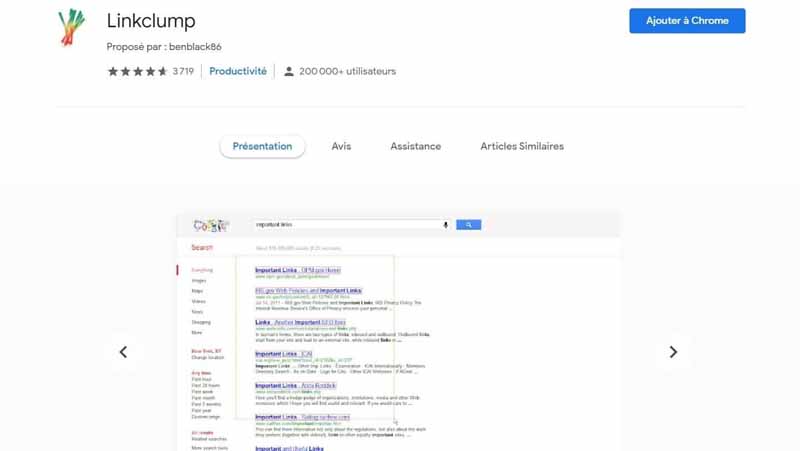
LinkClump es una extensión del navegador Chrome que se encuentra entre las mejores extensiones para impulsar las ventas. Es un rascador bastante fácil de usar que le permite ampliamente :
- Extraiga fácilmente los títulos y enlaces de los sitios web seleccionados;
- Ordene y seleccione sólo los enlaces y datos importantes de las páginas recuperadas;
- Recuperar imágenes u otros tipos de archivos.
Fuente: Salesdorado
Con LinkClump, podrá recuperar los enlaces y los títulos de cualquier página de la web en un abrir y cerrar de ojos. Es muy útil para recopilar datos de los sitios que aparecen en las SERP, como se muestra en la imagen anterior
1.5.3. Capitán Data
Captain Data es un rascador que le permite recuperar sólo los datos importantes. Con unos sencillos pasos, puede rastrear sitios de alta autoridad y recuperar los datos e información solicitados.
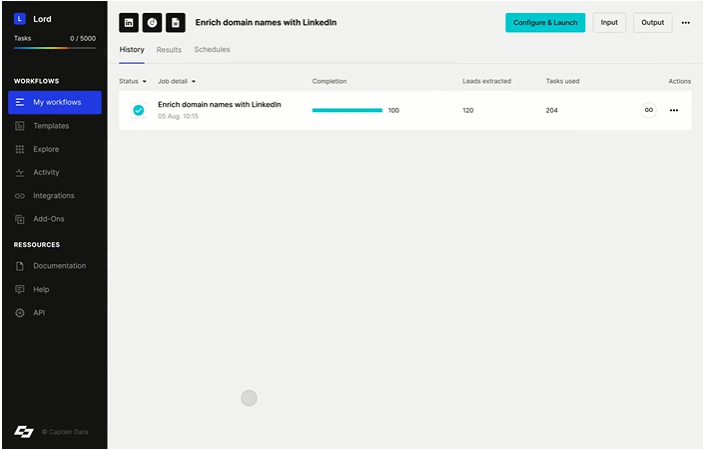
Fuente: Salesdorado
Captain Data escanea los sitios que nos gustaría raspar como: plataformas o redes sociales susceptibles de proporcionar correos electrónicos genéricos (Facebook, Linkedin, Sales Navigator, Twitter, Instagram, de hecho, etc.). En algunos casos, Captain Data puede incluso enviar solicitudes de conexión, especialmente en LinkedIn.
La principal ventaja de Captain Data reside en el hecho de que puede trabajar con las mejores herramientas de búsqueda de correo para ayudarle :
- Detecte los contactos de la empresa en Google;
- Utilice los datos de LinkedIn para enriquecer estos contactos;
- Encuentre los correos electrónicos de cada uno de los contactos con la integración de los contactos de la gota.
Sin embargo, por muy sencillo y eficaz que sea, el Capitán de datos requiere suscripciones a partir de 100 euros al mes.
1.5.4. Uso de TabSave para raspar un banco de imágenes o archivos de la web
TabeSave funciona conjuntamente con LinkClump. Por ejemplo, las fototecas o bancos de archivos suelen contener miles de imágenes o archivos. Con LinkClump, puede recuperar todos los enlaces a los bancos de imágenes o archivos.
Fuente: Salesdorado
El papel de TabSave será descargar todas las imágenes o archivos. Para ello, pegará todos los enlaces recuperados por LinkClump en TabSave y hará clic en «Descargar» para bajar una cantidad considerable de sus imágenes y archivos.
1.5.5. Uso de las hojas de cálculo de Google y XPath para raspar los títulos H2
Este es un uso un poco burdo, pero hay que entender que las hojas de cálculo de Google tienen una función llamada ImportXML que permite hacer muchas cosas.
Fuente: Salesdorado
También con el programa XPath, que es muy importante en el raspado web, puede raspar fácilmente cualquier elemento de un sitio web. Especialmente con XPath, puede recuperar todos los títulos H2 de un artículo en los sitios web seleccionados.
1.5.6 Web Scraper para principiantes
Bastante simple y sin código, Web Scraper es una herramienta de raspado web muy fácil y eficiente de usar.
La herramienta pone a disposición de sus usuarios vídeos tutoriales que le permitirán realizar ciertas tareas como paginar el contenido de su sitio e interactuar con las páginas, etc. Todo esto sin siquiera escribir una línea de código de antemano. Sin embargo, se necesita paciencia para hacer patrones y raspados. Puede que le lleve algún tiempo.
1.5.7. Utilizando SpiderPro por 38 dólares
Otra de las herramientas más fáciles de usar para los novatos. Por sólo 38 dólares, puede descargar Spider Pro para desguazar la web.
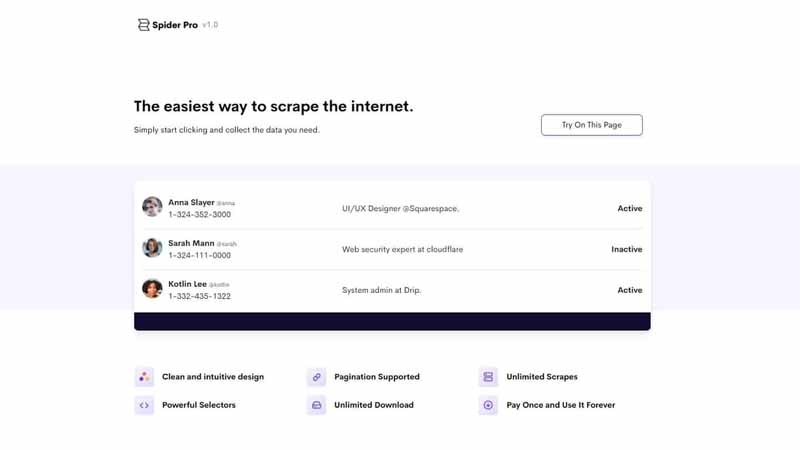
Fuente: Salesdorado
La herramienta le permite seleccionar el contenido o los datos que desee y luego convertirlos en datos bien organizados que pueden descargarse en formato JSON o CSV.
1.5.8. Uso de Apify
Apify es uno de los scrappers que permiten recuperar datos ordenados de sitios web en línea.
Si tiene una tienda online, puede utilizar Apify para raspar los datos de los sitios de las tiendas de la misma categoría que la suya con el fin de mejorar sus ofertas y hacer mejores ofertas a sus clientes.
Por ejemplo, como parte de su inteligencia competitiva, es posible que necesite crear una tabla en la que pueda poner :
- Tallas del vestido ;
- marcas ;
- Colores;
- Los precios.
Recoger esta información manualmente para completar su tabla puede llevarle mucho tiempo y es posible que no disponga de toda la información. Con una configuración de Apify, puede crear su tabla automáticamente y extraer los datos de sus competidores en segundos.
Fuente: Salesdorado
Además de ser una herramienta bastante fácil de usar, Apify tiene un montón de características para ayudarle a configurar sus Scrapes.
- Apify tiene documentación bien hecha en línea como Puppeteer, jQuery, underscoreJS, etc.
- Apify también tiene una API que le permite crear scripts de scrape en formato Json,XML,HTML,CSV,RSS y procesar el resultado en un webhook.
1.5.9. Scrapy; eficiente y rápido
Scrapy es una herramienta de scraping diseñada especialmente para aquellos que conocen Python. Le permite raspar fácil y rápidamente recursos de la web. Scrapy puede ejecutarse en un servidor local o en la nube de Scrapy.
Sin embargo, el uso de esta herramienta en páginas generadas con JavaScript puede dar problemas.

Fuente: Salesdorado
En este caso, Scrapy pide que se utilice la «Red» para buscar directamente las fuentes de datos, por lo que en lugar de forzar la ejecución de la consulta en la página web generada con JvaScript, puede hacerlo directamente a través de su navegador web
Capítulo 2: ¿Cuáles son los beneficios del raspado?
Este capítulo está dedicado a las diferentes ventajas del raspado.
2.1. Los beneficios del raspado relacionados con el uso de herramientas ?
Los datos recuperados de la web, ya sea de los sitios de la competencia o de los clientes potenciales, pueden permitirle hacer varias cosas, como
- Establezca una lista de empresas bien orientada;
- Seleccione los perfiles de clientes que le interesan;
- Realice un marketing basado en eventos (EBM), es decir, detecte automáticamente las señales de sus clientes. Esto le permitirá reaccionar mucho más rápido cuando sus clientes le necesiten.
- Y así sucesivamente.
En los últimos años, el uso de la automatización ha acelerado la popularidad del scraping. Esta estrategia, que antes estaba reservada a los desarrolladores más experimentados, está ahora al alcance de todos.
Con una herramienta como Captain Data, el scraping es ahora tan sencillo como elegir los sitios a scrapear y los datos a extraer.
Gracias a las herramientas de raspado, es posible :
- Extraiga información y datos sin tener ningún conocimiento técnico de programación;
- Mecanizar el proceso de recuperación de datos de la web;
- Procesar y analizar los datos para tomar decisiones estratégicas;
- Etc.
2.2. construir una lista de negocios bien dirigida con el Web Scraping
Si desea realizar una prospección, debe crear un perfil de su cliente ideal (Persona Branding). Este es el primer paso de cualquier actividad de marketing
Este primer paso consiste en crear un perfil del cliente (perfil del cliente ideal) adaptado a sus ofertas y servicios. Con el scraping, puede recuperar muchos datos sobre las empresas de su perfil ideal al dirigirse a las empresas.
Podrá recoger información valiosa a través del scraping, como por ejemplo
- Direcciones
- Correos electrónicos
- Números de teléfono.
El objetivo es disponer de toda la información necesaria que pueda conducirle a la empresa o al cliente ideal. Si su objetivo está en LinkedIn, por ejemplo, le recomiendo que utilice Linkedin Sales Navigator, que es una herramienta de raspado muy potente.
Fuente : Salesdorado
Este Scraper le permitirá obtener listas de empresas bien orientadas
Además, Google Maps también es una fuente muy eficaz en la que puede recopilar contactos de sitios con las características de su objetivo.
2.3. identificar y seleccionar la información correcta de las cuentas de sus clientes objetivo en LinkedIn
Hay varias formas de detectar los contactos adecuados y los datos que necesita
Si tiene un negocio que opera en el sistema B2B (Business to Business), puede encontrar estos datos explorando las cuentas de sus clientes objetivo en LinkedIn. Las herramientas presentadas anteriormente pueden ayudarle a hacerlo rápidamente y además ahorrará unos minutos preciosos en lugar de tener que revisar los perfiles uno por uno.
2.4. Detección de señales débiles con el raspado
El scraping es una estrategia que permite a un vendedor seguir la actividad de un cliente potencial o de un competidor detectando señales que le permitan considerar estrategias y oportunidades de negocio.
He aquí algunos consejos que puede utilizar para detectar las empresas según sus necesidades.
Fuente: Salesdorado
Consejo 1: Aplique filtros específicos en el Navegador de ventas
Por ejemplo, si decide detectar empresas en crecimiento, puede utilizar los filtros para explorar el «Crecimiento de los empleados».
Consejo 2: Utilice la función «Búsqueda de empleo» de Indeed para mejorar los datos recuperados
Este consejo se utiliza mejor cuando su público objetivo son las empresas que contratan.
En este caso, también puede acudir a LinkedIn para buscar empresas que publiquen ofertas de empleo. Hay que tener en cuenta que las reseñas negativas le dan una mejor oportunidad de recuperar a algunos de los clientes insatisfechos y descontentos de sus competidores.
2.5. El scraping le permite dar una puntuación a cada cliente: scoring CRM
Si quiere identificar sus indicadores clave de rendimiento y evaluar su mercado, el scraping también es una estrategia mejor para aplicar. Empiece por detectar un sitio web con mucho valor
En particular, puede recopilar muchos más datos sobre la empresa objetivo raspando :
- Redes sociales ;
- direcciones y datos legales;
- Datos e información fácilmente detectables (idiomas, enlaces de navegación, números de teléfono, etc.).
Además, puede crear patrones para extraer los correos electrónicos de los empleados. Un patrón se define como la estructura o construcción de una dirección de correo electrónico
Imagen
Por ejemplo, las direcciones de correo electrónico de las empresas suelen construirse con la estructura:prénom@nomdelentreprise.com.
Al detectar el patrón de la empresa, tiene la posibilidad de obtener los correos electrónicos de todos los empleados
Para automatizar sus acciones en este sentido, puede utilizar una herramienta como Hunter. Otras herramientas como Builtwith y Similartech pueden ayudar a identificar el tráfico de forma automática e incluso identificar otras herramientas de scraping que utilizan las empresas de la competencia.
2.5. Reunir datos e información fiables
La calidad de los datos es la capacidad de una empresa para actualizar sus datos a medida que las cosas cambian
Por tanto, como empresa, debe luchar contra la obsolescencia de sus datos. El scraping también puede ayudarle a controlar regularmente sus bases de datos y a actualizarlas a tiempo.
En efecto, se puede detectar una modificación o un cambio de un levantamiento de fondo, por ejemplo, con las señales de las herramientas de raspado. Esto le permitirá identificar nuevas oportunidades de negocio o estrategias de marketing.
2.6. Hacer que los datos recogidos sean accesibles y operativos
Como he explicado en la sección anterior, la calidad de los datos le permite mantenerlos actualizados
Pero tenga en cuenta que los datos sólo son fiables cuando son operativos e idénticos en todos los sistemas (software de CRM, software de automatización de marketing, etc.) en los que están presentes.
Con herramientas de scraping como Captain data, puede hacer que los datos sean accesibles en el software de CRM, pero también puede hacer que estén disponibles en todo el software del ecosistema de datos de su empresa.
Capítulo 3: Otras preocupaciones sobre el raspado
3.1. ¿El scraping es una estrategia de sombrero negro o de sombrero blanco?
Los principales objetivos de las técnicas de scraping son el SEO y las ventas.
El scraping se percibe como una extracción fraudulenta de datos de la web. A veces se utiliza con mala intención y algunos webmasters recogen información de otros sitios y luego la pegan en los suyos para mejorar su SEO.
Esto va en contra de las directrices de Google y es una mala práctica a la hora de clasificar un sitio web
Por lo tanto, se trata claramente de una práctica de Black Hat que puede conducir a una penalización manual o simplemente a una degradación por parte de Google.

Por otro lado, cuando el scraping se utiliza con la intención de mejorar su estrategia de marketing, puede considerarse como White Hat.
De hecho, cuando los datos extraídos de los sitios web se procesan y analizan para seguir la evolución de los competidores y definir un nuevo enfoque de marketing, el scraping contribuirá al desarrollo de su negocio de forma legal.
Tenga en cuenta que el scraping no es explícitamente una estrategia Black Hat, aunque algunos lo utilicen de forma incorrecta. Por cierto, Google también está raspando un gran número de sitios para garantizar a sus usuarios mejores resultados de búsqueda en las SERP.
3.2. ¿Cuál es la diferencia entre el raspado web y la indexación web?
Aunque el raspadoweb y laindexación web siguen casi el mismo proceso, no son lo mismo y tienen objetivos diferentes
La indexación es una práctica que permite a Google rastrear sitios web e indexar páginas web con contenido de calidad para presentarlas en los resultados de búsqueda.

Este trabajo lo realizan los robots de indexación, también llamados arañas, que se encargan de visitar las páginas web respetando las directivas (Robot.txt, Nofollow, etc.) del propietario del sitio
En cuanto al scraping, el objetivo general es recuperar contenidos de otros sitios web para uso personal.
El scraping se realiza sin el consentimiento del propietario del sitio y las herramientas de scraping utilizadas no respetan ninguna directriz.
Conclusión
En este artículo hemos definido el scraping con todos los matices posibles que se pueden hacer con el término «Scrap», así como los tipos y beneficios del scraping para el marketing digital.
No cabe duda de que la automatización de la práctica del raspado ha contribuido en gran medida a la expansión de esta técnica
También hemos esbozado una lista de potentes herramientas de scraping para ayudar a extraer datos y contenidos de la web de forma rápida y segura.
¿Le ha resultado útil este artículo?
Déjenos un comentario y mencione especialmente el raspador que le ha parecido más destacado y que piensa utilizar pronto.

