
Probablemente ya sepa que Google cambia constantemente su algoritmo de clasificación para ofrecer a los usuarios los mejores resultados posibles.
El 7 de agosto de 2023, el motor de búsqueda anunció que estaba investigando un nuevo marco de clasificación denominado Ponderación de términos BERT (TW-BERT), diseñado para mejorar los resultados de las búsquedas.
En este artículo, descubrimos qué es TW-BERT y cómo podría ayudar a Google a mejorar sus resultados de búsqueda.
Anuncio de Google sobre el marco de búsqueda TW-BERT
Google ha elaborado un documento de investigación que presenta un marco fascinante conocido como TW-BERT. Su función principal es mejorar los rankings de búsqueda sin incurrir en modificaciones sustanciales.
TW-BERT se presenta como un contexto de ponderación de términos de consulta que combina dos paradigmas para mejorar los resultados de las búsquedas.
Armoniza con los modelos de ampliación de consultas existentes al tiempo que aumenta su eficacia. Además, su introducción en un nuevo marco sólo requiere modificaciones mínimas.
La ponderación de términos BERT (TW-BERT) es un impresionante marco de clasificación que Google ha dado a conocer. Optimiza los resultados de las búsquedas y puede integrarse fácilmente en los sistemas de clasificación existentes.
Aunque Google no ha confirmado la explotación de TW-BERT, este nuevo marco representa un gran avance que mejorará los procesos de clasificación en varias áreas, incluida la ampliación de consultas.
Entre los colaboradores más destacados de TW-BERT se encuentra Marc Najork, uno de los principales investigadores de Google DeepMind y antiguo Director Senior de Ingeniería de Búsqueda de Google Research.
TW-BERT – ¿De qué estamos hablando?
TW-BERT es un contexto de clasificación que otorga puntuaciones, también conocidas como pesos, a las palabras contenidas en una consulta de búsqueda. El objetivo es determinar con mayor precisión qué páginas concretas son relevantes para esa consulta en particular.
Cuando se trata de la expansión de una consulta, TW-BERT resulta muy útil. Esta expansión es un proceso que reformula una consulta de búsqueda o le añade palabras(por ejemplo, añadir la palabra «home» a la búsqueda «ejercicios de musculación«) para que la consulta de búsqueda se ajuste más a los documentos.
El documento de investigación habla de dos métodos de búsqueda diferentes: uno basado en estadísticas y otro en modelos de aprendizaje profundo.
Según los investigadores
«Estos métodos de recuperación basados en estadísticas permiten una búsqueda eficaz que se adapta al tamaño del corpus y se generaliza a nuevos dominios. Sin embargo, los términos se ponderan de forma independiente y no tienen en cuenta el contexto de la consulta en su conjunto.
Para este problema, los modelos de aprendizaje profundo pueden realizar esta contextualización en la consulta para proporcionar mejores representaciones de los términos individuales.«
Para ilustrar la ponderación de los términos de búsqueda mediante TW-BERT, los investigadores toman el ejemplo de la consulta «zapatillas de correr Nike». Cada término de esta consulta recibe una puntuación, o «ponderación», que permite entender la consulta tal y como fue enviada por el usuario.
En esta ilustración, la palabra «Nike» se considera importante. Naturalmente, esta palabra recibirá una puntuación más alta. Los investigadores concluyen subrayando la importancia de garantizar que la palabra «Nike» reciba la ponderación suficiente al mostrar las zapatillas de correr en los resultados finales.
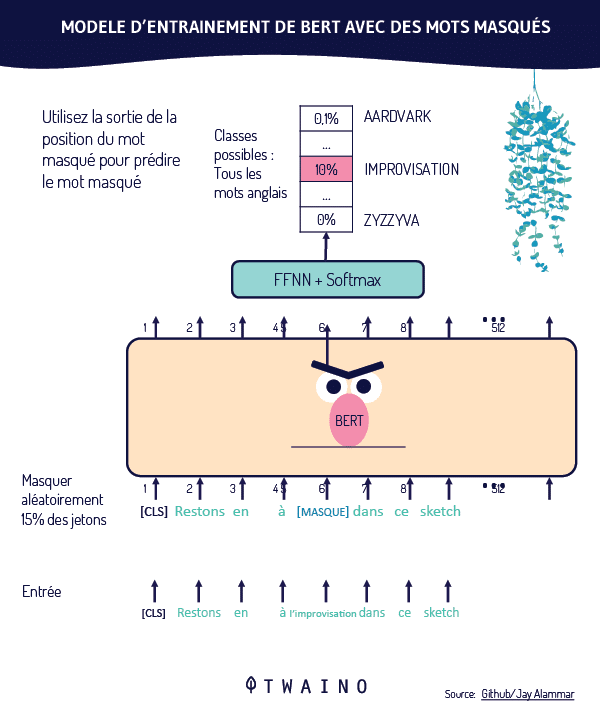
El otro reto es comprender la conexión entre las palabras «correr» y «zapatillas». Esto significa que la ponderación debe aumentar cuando las dos palabras se combinan para formar la expresión «zapatillas de correr», en lugar de ponderar cada palabra por separado.
El TW-BERT: la solución a las limitaciones de los marcos actuales
El documento de investigación analiza las limitaciones inherentes a la ponderación actual cuando se trata de la variabilidad de las consultas, y señala que los métodos de ponderación basados en estadísticas rinden por debajo de lo esperado en situaciones de «aprender desde cero».
El aprendizaje desde cero se refiere a la capacidad de un modelo para resolver un problema para el que no ha sido entrenado.
Los investigadores también presentaron un resumen de las limitaciones inherentes a los métodos actuales de expansión de términos.
La expansión de términos se refiere al uso de sinónimos para encontrar más respuestas a las consultas de búsqueda o cuando se deduce otra palabra.
Por ejemplo, cuando alguien busca «sopa de pollo», esto implica «receta de sopa de pollo».
Los investigadores describen las deficiencias de los enfoques actuales en los siguientes términos:
«… estas funciones auxiliares de puntuación no tienen en cuenta los pasos adicionales de ponderación implementados por las funciones de puntuación utilizadas en los extractores existentes, como las estadísticas de consulta, las estadísticas de documento y los valores de hiperparámetro.
Esto puede alterar la distribución original de las ponderaciones asignadas a los términos durante la evaluación final y la recuperación«.
Posteriormente, los investigadores argumentan que el aprendizaje profundo tiene sus propios retos en forma de complejidad de despliegue y comportamiento impredecible cuando se encuentra con nuevos dominios para los que no ha sido preentrenado.
Aquí es donde entra en juego TW-BERT.
¿En qué consiste TW-BERT?
La solución propuesta se asemeja a un enfoque híbrido.
Los investigadores escriben:
«Para salvar esta brecha, aprovechamos la solidez de los extractores léxicos existentes con las representaciones contextuales del texto que proporcionan los modelos profundos.
Los extractores léxicos ya asignan pesos a los términos de n-gramas en la consulta durante la búsqueda.
Nosotros explotamos un modelo lingüístico en esta fase de la canalización para asignar ponderaciones adecuadas a los términos de n-gramas en la consulta.
Este método de ponderación de términos BERT (TW-BERT) se optimiza globalmente utilizando las mismas funciones de puntuación empleadas en la canalización para garantizar la coherencia entre la formación y la recuperación.
Esto mejora la búsqueda cuando se utilizan las ponderaciones de términos producidas por un modelo TW-BERT a la vez que se mantiene una infraestructura de recuperación de información similar a la de su homólogo de producción existente.»
El algoritmo TW-BERT asigna ponderaciones a las consultas para proporcionar una puntuación de relevancia más precisa sobre la que luego puede trabajar el resto del proceso de clasificación.
Cómo es el sistema de búsqueda léxica estándar
Este diagrama ilustra el flujo de datos en un sistema de búsqueda léxica estándar.
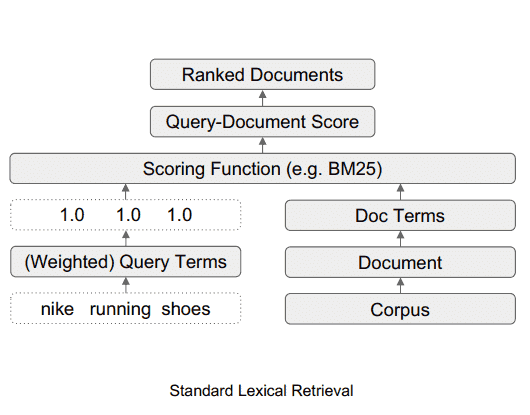
Fuente: searchenginejournal
Qué aspecto tiene el sistema de búsqueda TW-BERT
Este diagrama muestra cómo encaja la herramienta TW-BERT en un marco de búsqueda.
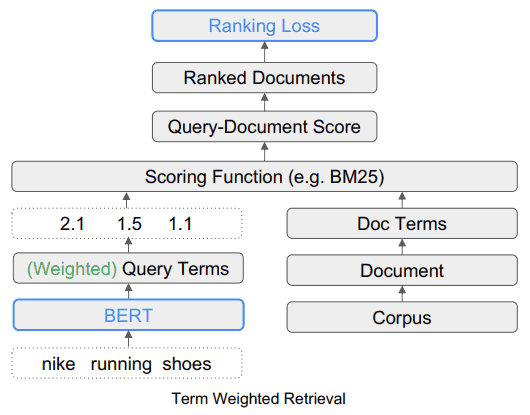
Fuente: searchenginejournal
La facilidad de despliegue de TW-BERT
Una de las ventajas de TW-BERT es que puede introducirse fácilmente en el proceso actual de clasificación de búsqueda de información, como un componente plug-and-play.
«Esto nos permite desplegar nuestras ponderaciones de términos directamente en un sistema de recuperación de información durante la búsqueda.
Esto difiere de los métodos de ponderación anteriores que requieren un ajuste adicional de los parámetros de un extractor para lograr un rendimiento de extracción óptimo, ya que optimizan las ponderaciones de términos obtenidas mediante heurística en lugar de una optimización de extremo aextremo.»
Un factor clave de la facilidad de implantación de TW-BERT es que no requiere el uso de software especializado ni actualizaciones de hardware. Esta capacidad hace que la integración de TW-BERT en un sistema de algoritmos de clasificación sea sencilla.
¿Ha incorporado ya Google TW-BERT a su algoritmo de clasificación?
En cuanto a su aplicabilidad al algoritmo de clasificación de Google, la facilidad de integración de TW-BERT sugiere que Google podría haber adoptado este mecanismo en la estructura de su algoritmo.
El marco podría integrarse en el sistema de clasificación del algoritmo sin requerir una actualización completa del algoritmo básico.
Por otro lado, algunos algoritmos poco eficaces o que no ofrecen ninguna mejora, aunque intrigantes en su diseño, podrían no conservarse para el algoritmo de clasificación de Google. Por otro lado, algunos algoritmos especialmente eficaces, como TW-BERT, están llamando la atención.
TW-BERT ha demostrado ser muy eficaz a la hora de mejorar las capacidades de los sistemas de clasificación actuales, lo que lo convierte en un candidato viable para su adaptación por parte de Google.
Si Google ya ha implementado TW-BERT, esto podría explicar las fluctuaciones de clasificación reportadas por las herramientas de monitoreo SEO y la comunidad de marketing de búsqueda durante el mes pasado.
Aunque Google sólo hace público un número limitado de cambios de clasificación, aquellos que tienen un impacto significativo, aún no existe confirmación oficial de que Google haya integrado TW-BERT.
Sólo podemos especular sobre su probabilidad basándonos en las importantes mejoras introducidas en la precisión del sistema de búsqueda de información y en la practicidad de su uso.
En resumen
TW-BERT es una importante innovación en el campo de la referenciación natural, que podría cambiar la forma en que Google analiza y clasifica las páginas web. TW-BERT aún no se ha integrado oficialmente en el algoritmo de Google, pero es posible que lo haga en un futuro próximo.

