
Un web crawler o robot (noto anche come “crawler”, “spider” o “web spider”) è un programma automatizzato che naviga metodicamente in rete al solo scopo di indicizzare le pagine web e il loro contenuto. Questi robot vengono utilizzati dai motori di ricerca per effettuare il crawling delle pagine web, al fine di rinnovare il loro indice con nuove informazioni. Così, quando gli utenti di Internet fanno una richiesta particolare, possono trovare facilmente e rapidamente le informazioni più rilevanti.
Quando effettua una ricerca su un motore di ricerca, otterrà come risultato un elenco classificato di siti web.
Prima che questi siti web compaiano nelle SERP, un processo noto come crawling eindicizzazione viene fatto dietro le quinte dai motori di ricerca
L’attore principale al centro di questo macchinario è il cingolato.
In questo caso :
- Che cos’è un robot o un crawler?
- Come funzionano?
- Qual è la sua importanza nella SEO ?
- Che cos’è l’indicizzazione e che ruolo hanno i robot?
- Qual è la differenza tra web crawler e web scraping?
Sono tutte domande le cui risposte ci permetteranno di comprendere chiaramente la definizione di crawler e tutto ciò che lo circonda.
Andiamo!
Capitolo 1: Che cosa intendiamo veramente per Crawler o strisciante?
Le unità funzionali dei motori di ricerca, i crawler o i robot sono al centro della maggior parte delle azioni e delle interazioni sul web
Capire la ricerca su Internet richiede una comprensione approfondita dei suoi concetti
Quindi, in questo capitolo, spiegherò i robot o i crawler in modo molto dettagliato.










1.1. Un Crawler: che cos’è?
Prima di parlare del crawler nel suo funzionamento e nelle sue applicazioni, è essenziale ricordare le sue origini e dare il suo vero significato.

Detto questo, ecco la storia e poi il vero significato del crawler.
1.1.1. Crawler o robot di indicizzazione dall’avvento del web
I robot di indicizzazione sono oggi conosciuti con molti nomi
- Cingolato ;
- Bot crawler ;
- Ragni ;
- Ragno web ;
- Software per motori di ricerca;
- E molti altri nomi.

Originariamente, il primissimo crawler si chiamava WWW Wanderer (abbreviazione di World Wild Web Wanderer)
Questo robot di indicizzazione, progettato e basato su Perl (un linguaggio di programmazione stabile e multipiattaforma), è stato incaricato già nel giugno 1993 di valutare la crescita di Internet, ancora emergente
All’epoca, il robot WWW Wanderer stava perlustrando Internet alla ricerca di dati che registrava nell’indice del giorno, il primissimo indice di Internet: ilindice Wandex
All’inizio, Wanderer effettuava solo il crawling dei server web. Poco dopo la sua completa introduzione, ha iniziato a tracciare gli URL.
Contrariamente a quanto si potrebbe pensare, Wanderer con il suo indice Wandex non è stato il primo motore di ricerca su Internet. In realtà si trattava del motore di ricerca archiettonico sviluppato da Alan Emtage
Tuttavia, con il suo indice Wandex, Wanderer era sicuramente la cosa più vicina a un motore di ricerca web generico come gli attuali motori di ricerca Google e Bing.
Dopo il WWW Wanderer, nel 1994 è comparso il primo browser web: il Webcrawler. Oggi è il più antico motore di ricerca (meta-motore di ricerca) ancora presente e funzionante su Internet.
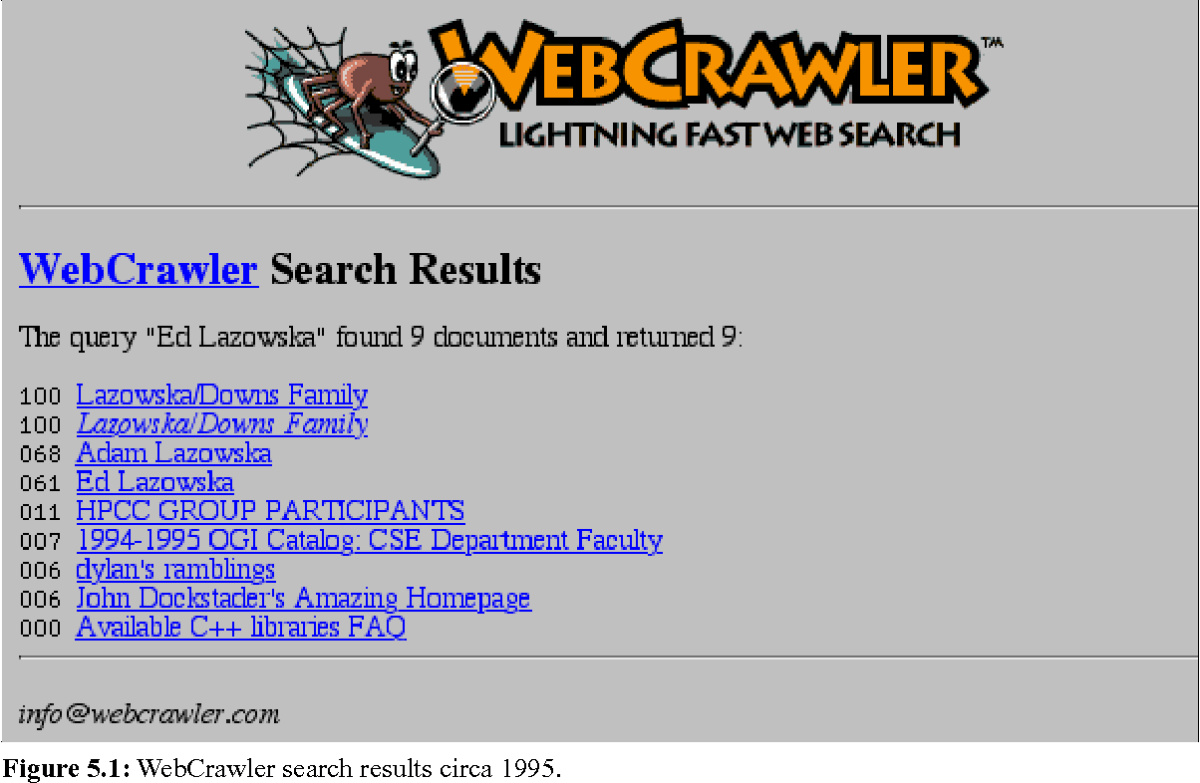
Nella costante evoluzione del web, sono stati apportati molti miglioramenti e i motori di ricerca e i loro robot di indicizzazione sono cambiati e migliorati.
La storia della ricerca su Internet e dei web crawler è stata appena delineata.
Tuttavia, qual è il vero significato della parola crawler?
1.1.2. Un Crawler: cosa significa veramente?
Prende il nome dal più antico motore di ricerca esistente (Webcrawler), crawler è una parola inglese che significa letteralmente “strisciare”, “strisciare”, “scansionare”… Tante corrispondenze opportune che esprimono chiaramente l’essenza stessa dei robot di indicizzazione
A rischio di ripetersi, un robot di indicizzazione è un programma informatico, un software che scansiona Internet in modo controllato, individuando e analizzando le pagine web con uno scopo specifico
Come un ragno con la sua tela, il crawler esplora e analizza la rete. Questa analisi riguarda le varie pagine web, i loro contenuti e tutte le loro ramificazioni
Il crawler, alla ricerca di dati, registrerà e memorizzerà le varie informazioni raccolte in indici e/o database
È quindi facile capire perché questi robot sono chiamati anche ragni o web spider.

Questi robot di indicizzazione sono, nel 99% dei casi, ancora utilizzati dai motori di ricerca. Permettono ai motori di ricerca di costruire indici strutturati e di ottimizzare le loro prestazioni come motori di ricerca (ad esempio, la presentazione di nuovi risultati rilevanti).
Nel restante 1% dei casi, i crawler vengono utilizzati per cercare e raccogliere informazioni di contatto e di profilo (indirizzi e-mail, feed RSS e simili) per scopi di marketing.
Per dirla in modo semplice, prendiamo il famoso esempio del bibliotecario. In questo esempio, il bot del motore di ricerca è un bibliotecario incaricato di inventariare tutti i libri e i documenti (siti web e pagine) in una biblioteca enorme e completamente disorganizzata (il web).
Il bot deve creare una tabella riassuntiva (indice del motore di ricerca) che permetta ai lettori (utenti di Internet) di accedere rapidamente e facilmente ai libri (informazioni) che stanno cercando
Per ordinare e classificare (indicizzare) i libri (siti web) in base alle aree di interesse e poi fare un inventario, il bibliotecario (crawler) dovrà chiedere per ogni libro, il suo titolo, il suo riassunto e l’argomento che tratta
Ma a differenza di una biblioteca, su Internet i siti web sono collegati tra loro da collegamenti ipertestuali, che vengono utilizzati dai bot per spostarsi da un sito o da una pagina web all’altra.
In breve, ecco cos’è il crawler e di cosa è responsabile. Non resta che sapere come funziona.
1.2) Come funziona un robot di indicizzazione o crawler?










Il crawler è soprattutto un programma, script e algoritmi il cui insieme di compiti e comandi è definito in anticipo
Come un bravo soldatino, segue assiduamente le istruzioni e le funzioni predefinite nel suo codice in modo automatico, continuo e ripetitivo
Navigando sul web attraverso i collegamenti ipertestuali (da siti web esistenti a nuovi siti web), gli spider indicizzano sia i contenuti che gli URL. Analizzano le parole chiave e gli hashtag e si assicurano che il codice HTML e i link dei siti indicizzati siano recenti.
Come dice il famoso proverbio africano: “È alla fine della corda vecchia che si tesse quella nuova”
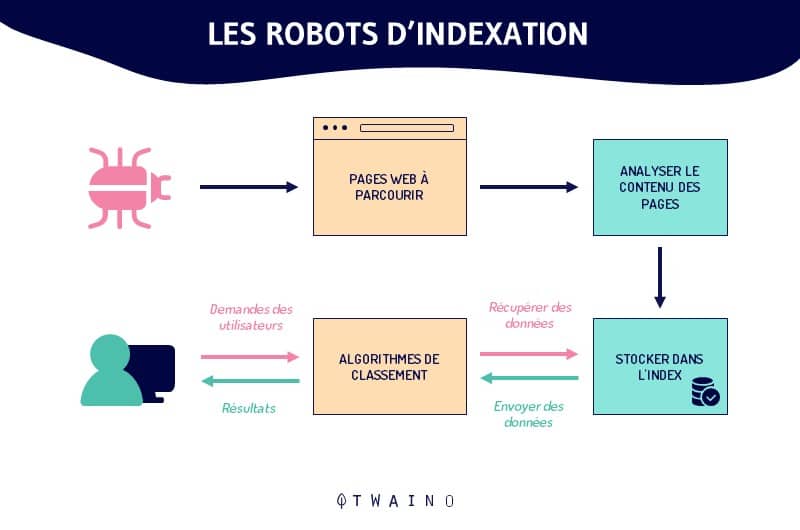
Poiché il web è in costante crescita, è impossibile valutare con precisione il numero totale di pagine su Internet
Nello svolgimento dei loro compiti, i crawler iniziano l’esplorazione da un elenco di URL noti
Quindi, il crawl segue uno schema molto semplice
Vecchi URL conosciuti => pagine web indicizzate => collegamenti ipertestuali => nuovi URL da crawlare => pagine web da indicizzare => così via..
Lungi dal lavorare in modo casuale, i robot di indicizzazione obbediscono a determinate regole che conferiscono loro una selettività meticolosa nella scelta delle pagine da indicizzare, nonché nell’ordine e nella frequenza dell’indicizzazione di queste pagine.
In questo modo, un robot di indicizzazione determina la pagina da indicizzare per prima in base a
- Il numero di backlink il numero di backlink che portano alla pagina (il numero di pagine esterne a cui questa pagina è collegata);
- Il linkage interno (i link tra le diverse pagine dello stesso sito web);
- Traffico della pagina (il numero di visitatori della pagina in questione);
- Elementi che attestano la qualità, la pertinenza e la freschezza dell’informazione contenuta nella pagina (la Sitemap, la meta-tagsmeta-tag, il URL canonicis, ecc.);
- Il robots.txt (il file che contiene gruppi di direttive per i bot) ;
- Ecc.
A seconda del motore di ricerca, questi fattori vengono considerati in modo diverso. È quindi comprensibile che non tutti i bot dei motori di ricerca si comportino allo stesso modo.
1.3. Quali sono i diversi tipi di Crawler?
Condividendo gli stessi principi operativi generali, i crawler si differenziano principalmente per l’obiettivo e la portata
Sì, oltre ai crawler dei motori di ricerca, esistono molte altre categorie di crawler.










1.3.1. Bot dei motori di ricerca
Questi crawler sono senza dubbio i primi crawler mai esistiti
Sono noti come searchbot. Un nome giustificato dal fatto che sono progettati con l’intenzione di servire i motori di ricerca nell’ottimizzazione del loro campo d’azione e soprattutto del loro database.
Tra i più famosi ci sono i seguenti searchbot:
- Googlebot di Google: il motore di ricerca più utilizzato in rete e quello con l’indice più ricco;
- Il Bingbot di Bingil motore di ricerca di Microsoft;
- Slurpbot di Yahoo;
- Lo spider Baidu del motore di ricerca cinese Baidu
- Il Bot Yandex di Yandexil motore di ricerca russo
- Il DuckDuckBot di DuckDuckGo ;
- Il Facebot di Facebook ;
- Alexa Crawler di Amazon ;
- E altro ancora.
1.3.2. Crawler desktop
Si tratta di mini crawler con funzionalità molto limitate. La loro limitata area di competenza è compensata dal loro costo relativamente insignificante
Si tratta di bot che possono essere eseguiti direttamente da un computer portatile o PC personale e possono elaborare solo una quantità molto ridotta di dati.
1.3.3. Web crawler personale
Una categoria di crawler progettati per le aziende e che vengono utilizzati, ad esempio, specificamente per fornire informazioni sulla frequenza di utilizzo di determinati hashtag/parole chiave
Gli esempi includono:
- Il VoilaBot dell’azienda di telecomunicazioni Orange
- Il bot OmniExplorer_Bot dell’azienda OmniExplorer
- E molti altri.
1.3.4. Cingolati commerciali
Si tratta di soluzioni algoritmiche offerte in abbonamento alle aziende che necessitano personalmente di un crawler. I crawler agiscono come strumenti a pagamento che consentono alle aziende di risparmiare l’enorme quantità di tempo e denaro necessaria per progettare il proprio crawler.
Esempi di software crawler a pagamento sono i seguenti:
- Botify ;
- SEMRush ;
- Oncrawl ;
- Strisciare in profondità ;
- Ecc
1.3.5. I bot dei siti web nel cloud
La particolarità di questi website crawler sta nel fatto che sono in grado di archiviare i dati raccolti nel cloud
Questo è un grande vantaggio rispetto ad altri crawler che si limitano a memorizzare le informazioni sui server locali a pagamento delle aziende IT.
Inoltre, l’accessibilità ai dati e agli strumenti di analisi è molto migliore. Non ci si deve più preoccupare della localizzazione e della compatibilità logistica.
1.4. Cosa dobbiamo ricordare dell’indicizzazione (Google) nella ricerca su Internet?
La porzione di web accessibile pubblicamente ed effettivamente strisciata dai robot rimane indeterminata
Si stima approssimativamente che solo il 40-70% della rete sia indicizzato per la ricerca, vale a dire diversi miliardi di URL.
Se prendiamo l’esempio del bibliotecario di cui sopra, l’azione di prospezione, classificazione e catalogazione dei libri (siti e pagine web) della biblioteca ha rappresentato l’indicizzazione della ricerca su Internet.

Indicizzazione è quindi un termine pratico che designa tutti i processi con cui il crawler scansiona, analizza, organizza e dispone le pagine dei siti web prima di proporle nelle SERP
Si tratta di un aspetto decisivo di riferimento naturalein quanto consiste nell’inserimento e nella considerazione delle pagine web nell’indice dei motori di ricerca
Sebbene questa prima fase di referenziazione organica sia decisiva, è ben lungi dall’essere sufficiente per la comparsa e il posizionamento delle pagine web nelle SERP.
Grazie ai continui aggiornamenti dell’indice di Google, e soprattutto con l’implementazione di Caffeinal’indicizzazione di Google si è evoluta maggiormente
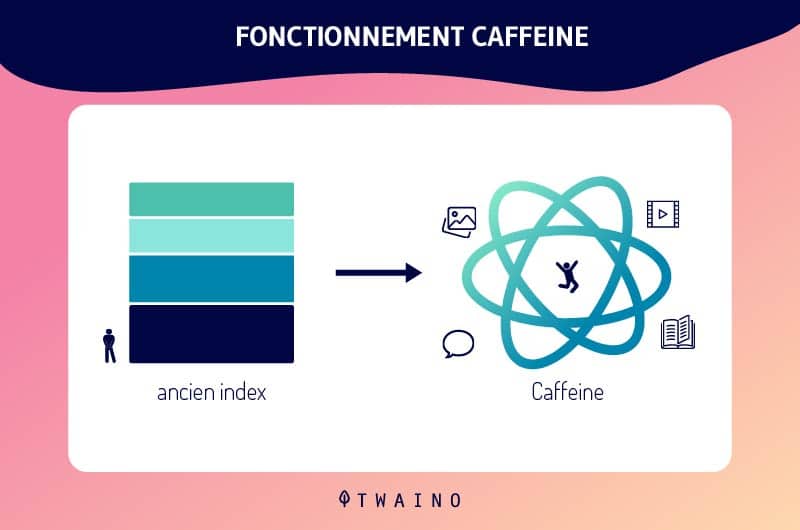
Di conseguenza, i nuovi contenuti e/o le nuove pagine web vengono prontamente indicizzati e la loro comparsa nelle SERP è diretta.
A parte questo, è fondamentale ricordare che le pagine e i contenuti del suo sito web non saranno indicizzati da Googlebot finché non li avrà trovati. Questa fase cruciale dell’indicizzazione di Google è controllabile.
In effetti, esistono diverse soluzioni per rendere le sue risorse visibili a Google. Il motore di ricerca stesso offre alternative interessanti ed efficienti sull’argomento.
Capitolo 2: Un Crawler in applicazione: cosa fa?
Ora che le presentazioni sono state fatte, entriamo nel vivo della questione.
Quali sono i contributi, i vantaggi e l’importanza SEO dei crawler?
2.1. In pratica, come funzionano i crawler?
Come abbiamo visto, il comportamento dei crawler è predefinito e integrato nelle loro linee di codice. I fattori che regolano l’indicizzazione delle pagine web sono quindi ponderati di conseguenza secondo i bot e secondo la buona volontà dei motori di ricerca.
In pratica, l’azione dei bot di indicizzazione viene decisa in diverse fasi.
Per prima cosa, i motori di ricerca devono determinare l’obiettivo e/o le preferenze di questi bot. Le politiche di crawling dei siti web, in particolare i tipi di URL da indicizzare, saranno quindi specificate nella porzione di dati che funge da salvaguardia, chiamata frontiera del crawler
In una seconda fase, i destinatari dei crawler assegnano ai loro robot un elenco di “semi”, che servirà come punto di partenza per l’indicizzazione. Si tratta di una serie di vecchi URL conosciuti o di nuovi URL da sottoporre a crawling.
Poi, i motori di ricerca aggiungono al programma dei bot la frequenza di esplorazione e di elaborazione da assegnare a ciascun URL.
Infine, i crawler sono addestrati a rispettare le linee guida del file robots.txt e/o i tag nofollow dell’HTML, a differenza degli spambots
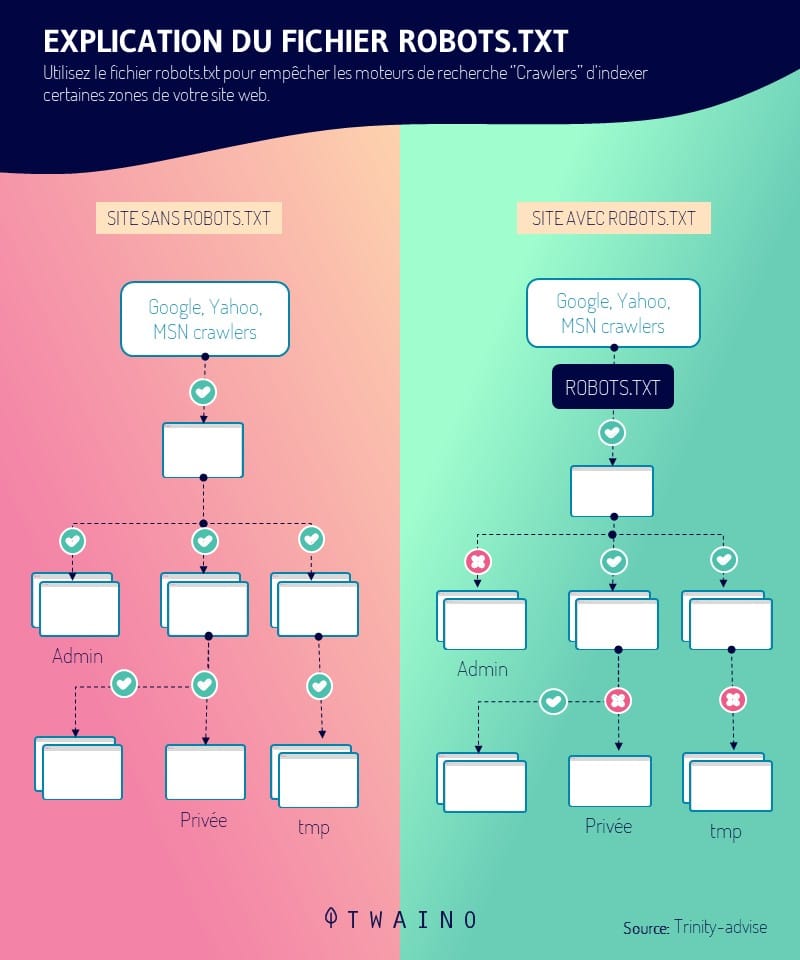
In questo modo, il crawler, in conformità con le linee guida di robots.txtprotocollo, saranno istruiti ad evitare tutto o parte di un sito web.
2.2. Un robot di indicizzazione: cosa fa?
Il crawler nelle sue applicazioni offre diversi vantaggi in molti settori.
Il primo vantaggio del crawler è il suo semplicità d’uso e la sua capacità di garantire per garantire una raccolta e un’elaborazione dei dati continua e completa.
Il suo un’efficienza senza pari nelle prestazioni delle sue funzioni di esplorazione e indicizzazione dei contenuti web è un altro vantaggio prezioso
Effettuando la prospezione, l’analisi e l’indicizzazione del web al posto degli esseri umani, i robot risparmiano un’incredibile quantità di tempo e denaro.
Dal punto di vista di SEO (Search Engine Optimisation), il crawler aiuta ad aumentare il traffico organico di un sito web e a distinguersi dalla concorrenza
A tal fine, fornisce informazioni sui termini di ricerca e sulle parole chiave più popolari.

Oltre a questi vantaggi principali, i crawler sono utili anche in molte altre discipline, come ad esempio
- Ottimizzazione dell’e-marketing analizzando la base clienti dell’azienda;
- Data mining e pubblicità mirata attraverso la raccolta di indirizzi e-mail e/o postali pubblici delle aziende;
- Valutazione e analisi dei dati dei clienti e dell’azienda allo scopo di migliorare le strategie di marketing dell’azienda;
- Creazione di database;
- La ricerca di vulnerabilità attraverso il monitoraggio continuo dei sistemi;
- E molti altri.
Capitolo 3: Qual è l’importanza e il ruolo dei crawler nella SEO?










Il ruolo e l’importanza dei crawler nell’indicizzazione non sono più in discussione. Tuttavia, le loro partizioni e i loro interessi nella strategia SEO rimangono finora poco chiari.
3.1. Il posto dei crawler nella SEO
L’importanza dei crawler per il referenziamento naturale è intimamente legata alla loro capacità di stabilire le condizioni necessarie affinché un sito web appaia nelle SERP
L’obiettivo della SEO è ottenere un notevole traffico organico generato da risultati naturali.
In altre parole: essere tra i primi risultati dei motori di ricerca.

Il crawling e l’indicizzazione delle pagine web da parte dei crawler è la base per apparire nei risultati dei motori di ricerca. In realtà, non è sufficiente per apparire nelle SERP, ma è un passo essenziale.
3.in che modo il web crawler aiuta gli esperti SEO?
L’ottimizzazione per i motori di ricerca consiste nel migliorare il posizionamento di un sito web nelle SERP. Ciò avviene ottimizzando i fattori tecnici e non tecnici della pagina per questi motori di ricerca.
Le implicazioni SEO del web crawler sono enormi, poiché il loro compito è quello di indicizzare il suo sito prima che gli algoritmi determinino se merita un posto nella prima pagina
Ecco due (02) consigli per far sì che indicizzino in modo efficiente le sue pagine importanti:
3.2.1. Collegamento interno
Inserendo nuovi backlink e link interni aggiuntivi, il professionista SEO si assicura che i crawler scoprano le pagine web dai link estratti, per garantire che tutte le pagine del sito web finiscano nelle SERP.
3.2.2. Invio della mappa del sito
Creare sitemap e inviarle ai motori di ricerca aiuta la SEO, in quanto queste sitemap contengono elenchi di pagine da sottoporre a crawling
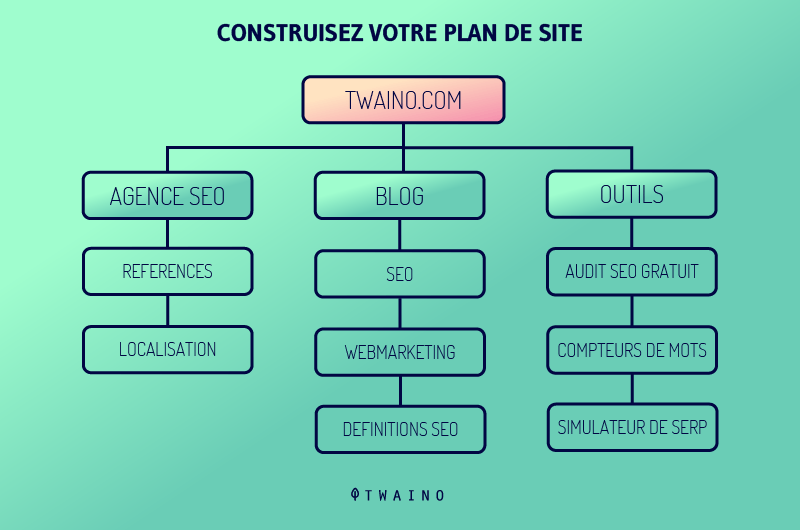
I crawler saranno facilmente in grado di scoprire i contenuti nascosti in profondità nel sito web e di scansionarli in breve tempo, producendo così una presenza delle pagine importanti del sito web nei risultati di ricerca.










3.3. Le migliori pratiche per migliorare il suo SEO con i crawler
L’ottimizzazione della sua strategia SEO comporta principalmente l’ottimizzazione del suo bilancio a gattoni (il budget per il crawl o l’esplorazione). Questo è il periodo di tempo così come il importo di pagine web che i crawler possono esplorare e analizzare per un sito web.
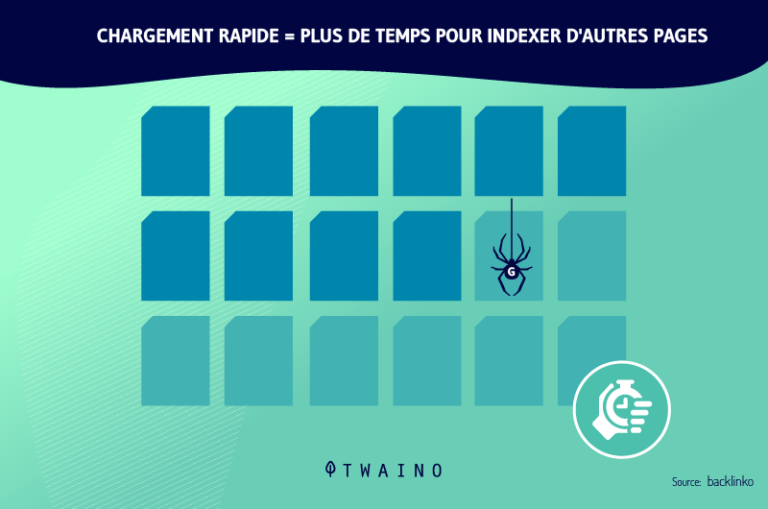
L’ottimizzazione di questo budget comporta il miglioramento della navigazione, dell’architettura e degli aspetti tecnici del sito web. È quindi consigliabile adottare, tra le altre, la buone pratiche le migliori pratiche:
- Invii una Sitemap XML tramite GSC (Google Search Console). Questa è una direttiva non standard in robots.txtche orienta i crawler verso le pagine che devono essere scansionate e indicizzate per prime.
- Fare un audit completo del sito web. L’obiettivo è migliorare fattori come le parole chiave, la velocità di caricamento delle pagine del sito web, ecc.
- Costruisca una strategia di netlinking ottimale con backlink e un forte collegamento interno. Da un lato, si tratta di ottenere link da altri siti web già indicizzati e con un’alta frequenza di crawler. D’altra parte, si tratta di collegare in modo intelligente le diverse pagine del sito web per consentire ai crawler di spostarsi facilmente da una pagina all’altra.
- Ispeziona URL, contenuti e codice HTML con l’obiettivo di rimuovere o aggiornare elementi obsoleti, superflui, discutibili o irrilevanti.
- Opti per meta-tag espliciti e pertinenti, contenuti di qualità, URL canonici..
- Evitare contenuti duplicatievitare i contenuti duplicati occultamento e tutte le pratiche SEO BlackHat.
- Si assicuri che il server che ospita il sito web sia accessibile ai crawler dei motori di ricerca.
- Identificare e correggere i vari elementi che bloccano l’indicizzazione delle pagine web.
- Sia consapevole degli aggiornamenti e delle modifiche degli algoritmi dei motori di ricerca, in modo da essere sempre al corrente degli attuali criteri SEO.
3.4. Altri usi dei crawler oltre ai motori di ricerca
Google ha iniziato a utilizzare il web crawler per cercare e indicizzare i contenuti, per scoprire facilmente i siti web in base a parole e frasi chiave
I motori di ricerca e i sistemi informatici hanno creato i propri web crawler programmati con diversi algoritmi. Questi effettuano il crawling del web, analizzano il contenuto e creano una copia delle pagine visitate per un’ulteriore indicizzazione
Il risultato è visibile, perché oggi è possibile trovare facilmente tutte le informazioni o i dati validi che esistono sul Web.
Possiamo utilizzare i crawler per raccogliere determinati tipi di informazioni dalle pagine web, come ad esempio
- Recensioni indicizzate da un’applicazione di aggregazione alimentare; informazioni per la ricerca accademica
- Informazioni per la ricerca accademica;
- Ricerche di mercato per individuare le tendenze più popolari;
- I migliori servizi o luoghi per uso personale;
- Lavori o opportunità aziendali;
- Ecc.
Altri casi d’uso dei crawler includono:
- Tracciamento delle modifiche dei contenuti;
- Rilevamento di siti web dannosi;
- Recupera automaticamente i prezzi dai siti web della concorrenza per la strategia dei prezzi;
- Identificare i potenziali bestseller per una piattaforma di e-commerce, accedendo ai dati dei concorrenti;
- Classifica della popolarità dei leader o delle star del cinema;
- Accesso ai feed di dati di migliaia di marchi simili;
- Indicizzazione dei link più frequentemente condivisi sui social network;
- Accesso e indicizzazione degli annunci di lavoro in base alle recensioni e alle retribuzioni dei dipendenti;
- Benchmark dei prezzi e catalogazione dei codici postali per i rivenditori;
- Accesso ai dati di mercato e sociali per costruire un motore di raccomandazione finanziaria;
- Scoprire le chat room legate al terrorismo;
- Ecc.
Se è a conoscenza di Scraping del webforse si sta confondendo con il web crawling. Ora vediamo la differenza:
3.5. Web crawler vs Web scraper: confronto
Come il crawler, lo scraper è un robot responsabile della raccolta e dell’elaborazione dei dati sul web. Ma non si illuda, i crawler e gli scrapers non sono lo stesso tipo di robot.
Il web scraper è per il web crawler ciò che lo yin è per lo yang, il nero per il bianco, il male per il bene..
Uno serve il lecito e il giusto, mentre l’altro a volte serve il lato oscuro
In realtà, lo scraper è un bot programmato per individuare e duplicare nella sua interezza, di solito senza autorizzazione, dati specifici appartenenti al contenuto di un sito web
Dopo aver estratto questi dati, lo scraper li inserisce così come sono o come sono stati modificati nei database per utilizzarli successivamente.
Sebbene simili, i due bot sono chiaramente diversi sotto diversi aspetti:
- La loro funzione principale
La funzione del crawler consiste esclusivamente nell’esplorare, analizzare e indicizzare i contenuti web attraverso la consultazione continua di URL vecchi e nuovi. Gli scrapers, invece, esistono solo per copiare i dati dai siti web seguendo URL specifici.
- Il loro impatto sui server web:
A differenza dei crawler dei motori di ricerca, che seguono le linee guida dei file robots.txt e si accontentano dei metadati, gli scrapers non seguono alcuna regola.
Vediamo un rapido caso di studio del concetto di web scraping:
Caso di studio
- In primo luogo, da riferendosi a a Condizioni d’uso del 7 giugno 2017linkedin dichiara quanto segue nella sezione 8.2.k
“Lei accetta di non: […] sviluppare, supportare o utilizzare alcun software, dispositivo, script, bot o qualsiasi altro mezzo o processo (inclusi, senza limitazioni, web crawler, plug-in e add-on del browser, o qualsiasi altra tecnologia o lavoro fisico) per fare web scraping dei Servizi o copiare in altro modo profili e altri dati dai Servizi.”
Ciononostante, in una battaglia legale tra Linkedin e una start-up statunitense chiamata HiQ Labs (sull’utilizzo di pratiche di web scraping per raccogliere esclusivamente informazioni appartenenti ai profili pubblici di LinkedIn dei dipendenti di un’azienda), il tribunale ha deliberato come segue
I dati presenti sui profili degli utenti sono pubblici una volta pubblicati in rete e, in questo caso, possono essere raccolti liberamente tramite il web scraping.
- In secondo luogo, facendo riferimento a fabbrica digitaleil web scraping sarebbe considerato ai sensi dell’Articolo 323-3 del Codice Penale francese come “furto di dati”. Questo articolo afferma che:
“Il fatto di introdurre fraudolentemente dei dati in un sistema di elaborazione automatizzato, di estrarre, detenere, riprodurre, trasmettere, cancellare o modificare fraudolentemente i dati in esso contenuti è punibile con cinque anni di reclusione e una multa di 150.000 euro. Quando questo reato è stato commesso contro un sistema automatizzato di elaborazione dei dati personali implementato dallo Stato, la pena è aumentata a sette anni di reclusione e una multa di 300.000 euro
Ora sta a lei trarre le sue conclusioni da questo concetto di web scraping.
Capitolo 4: Altre domande sui web crawler
4.1. Che cos’è un crawler?
Un crawler web è un software progettato dai motori di ricerca per effettuare automaticamente il crawling e l’indicizzazione del web.
4.2 Che cosa è il crawling di Google?
Il crawling è il processo con cui Googlebot (noto anche come robot o spider) visita le pagine per aggiungerle all’indice di Google. Il motore di ricerca utilizza una vasta gamma di computer per recuperare (o “strisciare”) miliardi di pagine sul web
4.3. Quando striscia?
Il crawling avviene quando Google o un altro motore di ricerca invia un robot (o spider) a una pagina web o a una pubblicazione web per effettuare il crawling della pagina web
Questi crawler estraggono poi i link dalle pagine che visitano per scoprire altre pagine del sito web
4.4 Come funziona il crawler di Google?
I web crawler iniziano il loro processo di crawling scaricando il file robot.txt del sito web. Il file include sitemap che elenca gli URL che il motore di ricerca può scansionare. Una volta che i crawler iniziano a strisciare una pagina, scoprono nuove pagine attraverso i link
Quindi, aggiungono gli URL appena scoperti alla coda di crawling, in modo che possano essere crawlati in seguito. Con questa tecnica, questi crawler possono indicizzare ogni pagina che è collegata ad altre.
Dal momento che le pagine cambiano regolarmente, i crawler dei motori di ricerca utilizza diversi algoritmi per decidere su fattori come la frequenza con cui una pagina esistente deve essere sottoposta a crawling e quante pagine di un sito devono essere indicizzate.
4.5. Che cos’è l’anti-crawler?
L’anti crawler è una tecnica per proteggere i crawler o gli indicizzatori dal suo sito web. Se il suo sito web contiene immagini di valore, informazioni sui prezzi e altre informazioni importanti che non vuole che vengano carrellate, può usare tag meta robots.
4.6. Come lavora Google per fornire risultati pertinenti alle richieste degli utenti?
Google effettua il crawling del web, categorizza i milioni di pagine esistenti e le aggiunge al suo indice. In questo modo, quando un utente effettua una ricerca, invece di scansionare l’intero web, Google può semplicemente scansionare il suo indice più organizzato per ottenere rapidamente risultati pertinenti.
4.7. Cosa sono le applicazioni di web crawling?
Il crawling del web è comunemente usato per indicizzare le pagine per i motori di ricerca. Ciò consente ai motori di ricerca di fornire risultati pertinenti per le query degli utenti.
Il crawling del web viene utilizzato anche per descrivere lo scraping del web, l’estrazione di dati strutturati dalle pagine web e simili.
4.8. Quali sono gli esempi di Crawler?
Ogni motore di ricerca utilizza il proprio web crawler per raccogliere i dati da Internet e indicizzare i risultati della ricerca
Per esempio:
- Amazonbot è un crawler web di Amazon per l’identificazione di contenuti web e la scoperta di backlink
- Baiduspider per Baidu ;
- Motore di ricerca Bingbot per Bing da Microsoft ;
- DuckDuckBot per DuckDuckGo ;
- Exabot per il motore di ricerca francese Exalead;
- Googlebot per Google ;
- Yahoo! Slurp per Yahoo ;
- Yandex Bot per Yandex ;
- Ecc.
4.9. Qual è la differenza tra web crawling e web scraping?
In generalecrawling del web è praticata dai motori di ricerca attraverso i robot, che consistono nel crawling e nella creazione di una copia della pagina nell’indice
A differenza di strisciare scraping del web è utilizzato da un essere umano, sempre attraverso un bot, per estrarre dati particolari, di solito da un sito web, per una possibile analisi o per creare qualcosa di nuovo
In sintesi
I crawler e l’indicizzazione sono ora concetti di cui lei conosce il significato e le implicazioni. Si ricordi che questi concetti sono la vita quotidiana e l’essenza stessa dei motori di ricerca
Il crawler, nella sua funzione di prospezione e archiviazione del web, determina la presenza e la posizione dei siti web nei risultati dei motori di ricerca
Tuttavia, i robot di indicizzazione, gli spider o come li si voglia chiamare, sono utilizzati anche in molti altri campi e discipline
Dal funzionamento dei diversi protagonisti della ricerca su Internet alle migliori pratiche per la sua ottimizzazione, ora ha un’idea abbastanza chiara dell’intero argomento.
Applichi le conoscenze acquisite in modo intelligente
Condivida con noi nei commenti la sua esperienza e le sue scoperte sull’argomento
A presto!

