
Nella SEO, Allow è una direttiva che permette di gestire i crawler inviati dai motori di ricerca come Google e Bing. La sua funzione principale è quella di comunicare a questi bot che hanno accesso a determinati URL, sezioni o file del sito web. D’altra parte, abbiamo il Disallow che proibisce l’accesso a questi stessi elementi ritenuti sensibili.
La creazione di contenuti e l’animazione del sito web sono solo una parte dell’impegno che comporta la creazione di un sito web SEO. Diversi altri elementi entrano in gioco quando si tratta di far apparire le pagine di un sito web tra le prime della classifica SERP (Search Engine Result Page)
Infatti, i siti web hanno, ad esempio, un file robots.txt contenente direttive che le permettono di gestire le azioni dei crawler sulle pagine del suo sito web. Tra queste direttive, abbiamo Allow.
Quindi :
- Cosa significa questo termine tecnico?
- Dove posso trovarlo?
- Come può essere utilizzato e quali sono i suoi vantaggi per la SEO?
Continui a leggere questo articolo per ottenere risposte chiare e precise a queste domande.
Capitolo 1: Che cos’è la direttiva Allow e qual è il suo utilizzo nella SEO?
In questo capitolo, cercherò di :
- Per approfondire un po’ la definizione del termine Allow
- Dimostri dove si trova in una pagina web;
- E per dare la sua importanza nella SEO di una pagina web.
1.1 Che cos’è la direttiva Consenti?
La direttiva Consenti è un’affermazione in un file robots.txt che le permette di specificare e indicare al sito web di Cingolati (crawler) dei motori di ricerca quali pagine di un sito web visitare e indicizzare

Come promemoria, il file robots.txt è un file di testo che contiene istruzioni per i crawler. Contiene diverse direttive (Allow, Disallow, Sitemap, ecc.), ciascuna con una o più specificità
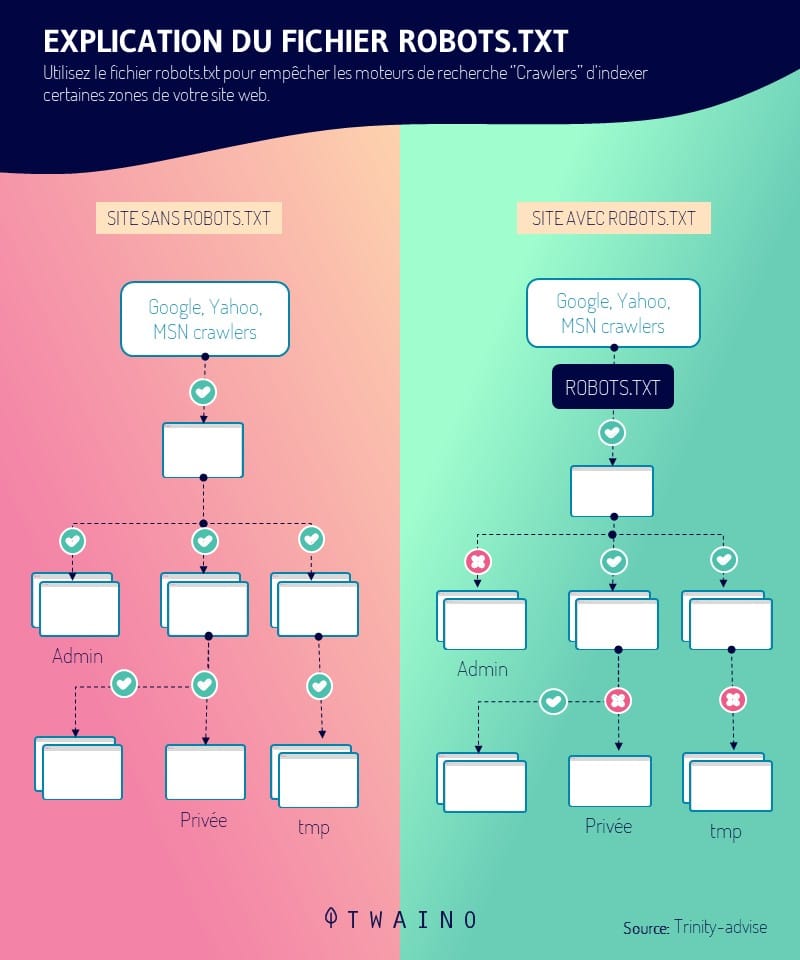
Il linguaggio o il codice utilizzato in questo file robots.txt è compreso solo dai motori di ricerca come Google, Bing..
La sua missione è quella di autorizzare l’indicizzazione o meno delle pagine di un sito web o di un negozio online durante il crawl
In contrapposizione alla direttiva Disallow che permette diprevenire gli spider dei motori di ricerca non possono effettuare il crawling di una pagina web o dell’intera directory; Consenti indica agli spider quali parti del sito devono effettuare il crawling.
1.2) Dove si trova la direttiva Allow?
Il permesso è incluso in un file robots.txt che si trova nella directory principale e nell’URL dei siti web. Questo file contiene diverse altre direttive, come :
- Disconoscere ;
- Negare ;
- Ordine
- Ecc
Per verificare la presenza del file robots.txt, è sufficiente digitare il seguente link nella barra degli indirizzi del suo browser http://www.adressedevotresite.com/robots.txt
1.3. Qual è l’uso della direttiva Allow?
Vedremo di seguito la sua utilità nella gestione del sito web e la sua relazione con la SEO:
1.3.1. L’importanza della direttiva Allow nella gestione del sito web
Come suggerisce il nome, questa direttiva viene utilizzata per gestire un sito web. Permette al webmaster di indirizzare i crawler inviati dai motori di ricerca verso aree specifiche del server, pagine che possono essere scansionate
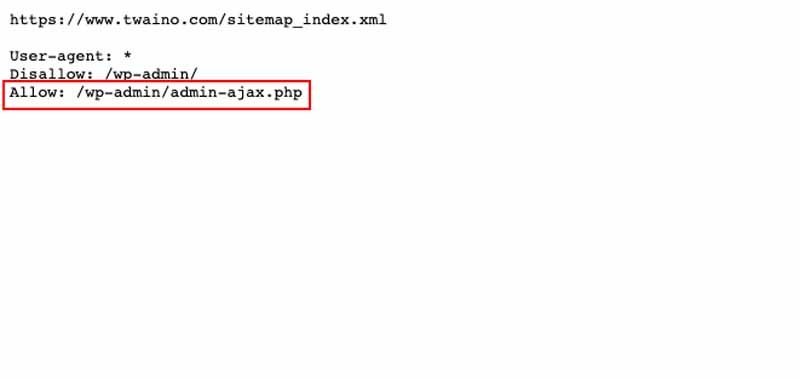
Questo può essere fatto in base al nome del bot, all’indirizzo IP o a qualsiasi altra caratteristica legata a ciascun bot e registrata nelle variabili d’ambiente
In sintesi, la direttiva Consenti le permette di specificare quali Crawler sono consentiti per accedere al server del sito web e le pagine che possono esplorare.
1.3.2. La direttiva Consenti e la SEO
In primo luogo, il file robots.txt contribuisce a una buona SEO grazie alla sua missione di dirigere l’esame di diverse parti di un sito web attraverso le sue varie direttive
Con la direttiva Consenti inclusa in questo file, il Webmaster ha la possibilità di controllare i crawler e di indicare loro quali sono le pagine migliori (altamente ottimizzate) del sito web da sottoporre a crawling
Può anche impedire che le pagine indesiderate vengano strisciate, ma questa volta con la direttiva disallow.

La funzione principale della direttiva Allow con Disallow è quella di gestire il percorso del crawler, indicandogli quali pagine di alto valore indicizzare. Queste pagine indicizzate dagli spider o dai crawler saranno visualizzate nelle SERP
Capitolo 2: Applicazione della direttiva Allow
Controllando l’applicazione della direttiva Consenti, può controllare e specificare quali spider devono visitare il suo sito e quali aree del sito devono essere visitate.
La direttiva Consenti viene applicata in base a determinati argomenti o caratteristiche specifiche dei web crawler. Può essere applicato in base a quanto segue:
- Il nome di dominio ;
- L’indirizzo IP completo o parziale;
- Una coppia di rete ;
- Una specifica di rete CIDR.
2.1. L’applicazione di Allow basata sul nome di dominio
Consenti utilizza sempre “dacome primo argomento”
Nel caso in cui specifichi il primo argomento come “Consentire da tutticioè “Consenti a tutti”, consente a tutti gli spider di effettuare il crawling del suo sito web e di accedere a tutte le pagine del suo sito
L’unica restrizione è quando il Negare e Ordine sono impostate per impedire ad alcuni spider di accedere al server.
Inoltre, quando si imposta il primo argomento della direttiva Allow con il nome di dominionome di dominio, i crawler con nomi che corrispondono alla stringa specificata possono accedere al server e fare il crawling delle pagine del sito.
Esempio: Permetti da twaino.org
Consenti da .net example.edu

2.2. L’applicazione di Allow basata sull’indirizzo IP
Con la configurazione basata sulindirizzo IPconfigurazione basata, l’accesso sarà dato ai web crawler dopo un doppio test di riconoscimento (ricerca DNS) sull’indirizzo IP dello spider
Per prima cosa, verrà effettuata una prima ricerca inversa per determinare il nome del robot associato all’indirizzo IP
Poi, verrà effettuata una seconda ricerca direttamente sul robot per verificare se il nome del robot explorer corrisponde davvero all’indirizzo IP originale
In questo modo, il robot avrà accesso al server del sito solo quando il suo nome corrisponde al nome stringa specificata
Inoltre, è necessario che le due ricerche di indirizzi IP inversi dovrebbero dare risultati logici e coerenti.
Esempio: Consenti da 10.1.2.3
Consenti da 192.145.1.124.236.128
2.3. L’applicazione di Allow si basa sulla variabile d’ambiente
Questo terzo tipo di argomento utilizzato dalla direttiva Allow consente di accedere all’esplorazione delle pagine del sito soltanto quando riconosce l’esistenza di informazioni relative all’Spider in un meccanismo di archiviazione delle informazioni chiamato variabile d’ambiente
Da un punto di vista pratico, quando Allow viene specificato “Consenti da env=var-env“consente l’accesso a tutti i crawler che hanno la variabile d’ambiente “var-env“.
Il server del sito le permette di specificare molte variabili d’ambiente con relativa facilità. Ha quindi la possibilità di utilizzare questa direttiva per controllare l’accesso al suo sito in base alle intestazioni.
Esempio:
SetEnvIf User-Agent ^KnockKnock/2\.0 let_me_enter
Ordine Negare, Consentire
Rifiuta da tutti
Consenti da env=let_me_in
.
Capitolo: Altre domande poste sulla direttiva Allow
3.1 Che cos’è Allow?
Allow è un termine che significa Permettere. È una delle direttive che si trovano nel file robots.txt e indica ai crawler quali pagine possono accedere. Definisce anche i tipi di robot che possono accedere a una determinata pagina
3.2. Perché allow è importante per la gestione e la referenziazione di un sito web?
La sua importanza è giustificata dal fatto che le permette di avere un controllo totale sull’amministrazione del suo sito. In altre parole, può dare ordini ai crawler sulle pagine essenziali che devono esplorare. Può anche dare accesso a robot specifici.
3.3. Che cos’è un file robots.txt?
Il file robots.txt è un file di testo con una serie di direttive per manipolare positivamente i robot dei motori di ricerca su come effettuare il crawling e l’indicizzazione di un sito web.
3.4. Che cos’è un indirizzo IP?
Un indirizzo IP (con IP che sta per Internet Protocol) è un numero unico assegnato in modo permanente o temporaneo a un dispositivo collegato a una rete per identificarlo.
3.5. Che cos’è un crawler web?
Un web crawler, noto anche come spider, spider o crawler, è un programma tipicamente utilizzato da Google e Bing per effettuare automaticamente il crawling e l’indicizzazione delle pagine web
Queste pagine web, dopo essere state inserite nell’indice del motore di ricerca, possono ora apparire nei risultati di questo motore di ricerca.
In sintesi
La referenziazione naturale di un sito è un compito a lungo termine. Esiste un’intera gamma di azioni che entrano in gioco per migliorare il ranking di un sito e per far apparire le sue pagine tra i primi risultati della SERP (Search Engine Result Page)
La direttiva Allow è uno degli strumenti che deve padroneggiare per controllare l’indicizzazione delle pagine del suo sito web.
Spero che questa guida abbia fornito risposte chiare ai suoi dubbi sul termine Permesso. Quindi, la prego di condividerla se l’ha aiutata.
Grazie e a presto!

