
I contenuti duplicati si riferiscono a blocchi di testo completamente identici l’uno all’altro (duplicati esatti) o simili con piccole differenze, noti anche come quasi-duplicati. In ambito SEO, i contenuti duplicati si verificano quando questo tipo di contenuto compare su più URL o pagine web dello stesso sito o di siti diversi.
Secondo Matt Cutts di Google, 25-30 per cento di contenuti viene duplicato su Internet. Per continuare con questa logica, un recente studio di Raven Tools basato sui dati del loro strumento di audit ci dà una cifra approssimativa di 29 % per lo stesso problema
Sebbene questo fenomeno sia spesso involontario, Google e altri motori di ricerca penalizzano indirettamente i siti web con contenuti duplicati
Per comprendere meglio questo concetto, è necessario discutere i seguenti punti chiave:
- Una breve panoramica sul significato di ”contenuto duplicato” e sui suoi diversi tipi;
- Le cause e i modi per individuarle;
- Buone pratiche per affrontarle.
Queste sono alcune delle molte domande chiave a cui risponderò in modo chiaro e preciso nel corso di questa guida.
Scopra di più!
Capitolo 1: Cosa dobbiamo capire del “contenuto duplicato”?
In questo capitolo, spiegherò i punti essenziali dei contenuti duplicati, come ad esempio
- Un breve promemoria della sua definizione;
- I diversi tipi esistenti;
- Il suo impatto sulle referenze










1.1. Contenuti duplicati: che cos’è?
Il contenuto duplicato è un blocco di testo che appare più volte sul web. Quando un testo è presente in un unico URL, si parla di contenuto unico. Altrimenti, viene considerato duplicato.

Per essere più chiari, si tratta dell’atto di copiare i risultati di altri e pubblicarli sul suo sito. In generale, questa duplicazione avviene senza il permesso preventivo dell’autore.
Questo non solo solleva dubbi sulla sua capacità di produrre testi attraenti e originali, ma Google potrebbe anche penalizzare il suo SEO.
1.2) Quali sono i diversi tipi di contenuti duplicati?










I contenuti duplicati non sono solo il risultato della copia deliberata di testi o parti di essi, ma molto spesso anche :
- Cause tecniche legate al funzionamento del CMS;
- Motivi legati alla gestione del catalogo prodotti nel caso dell’e-commerce;
- Ecc.
Da questi casi che portano alla generazione di duplicati, si possono dedurre due tipi di contenuti duplicati:
1.2.1. Contenuti duplicati interni (sullo stesso sito)
I contenuti duplicati interni si verificano quando c’è una ripetizione di testo o di parti di testo su due o più pagine dello stesso sito web

I contenuti duplicati interni sono generalmente in buona fede, poiché provengono principalmente da
- Errori tecnici;
- Impostazioni URL;
- Ecc.
Va notato che non si tratta di un caso di furto di contenuti, ma di errori che portano alla moltiplicazione dei contenuti su URL diversi.
1.2.2. Contenuti duplicati esterni
Si tratta di pagine in cui il testo è lo stesso che si trova su altri siti. Questo tipo di contenuto duplicato è quello che causa veri conflitti.

Questo caso si riscontra in particolare nelle schede prodotto dell’e-commerce, che contengono informazioni tecniche sui prodotti e sulle loro funzioni d’uso.
Non è raro che nell’e-commerce alcuni utilizzino le descrizioni dei fornitori per i loro prodotti. Questo fa sì che lo stesso contenuto testuale sia presente su diversi siti web.
1.3. Quale impatto possono avere i contenuti duplicati sulla SEO e sul ranking di un sito web?









A causa della confusione che i contenuti duplicati causano agli spider dei motori di ricerca, qualsiasi classifica e consapevolezza può finire per essere divisa tra URL duplicati
Questo accade perché gli spider dei motori di ricerca devono scegliere quale pagina web devono classificare per una determinata parola chiave.
Quindi ogni variante di URL riceve punteggi di autorità di pagina e potere di ranking diversi.
Ma nel tempo, Google ha capito che la maggior parte dei contenuti duplicati non sono creati intenzionalmente
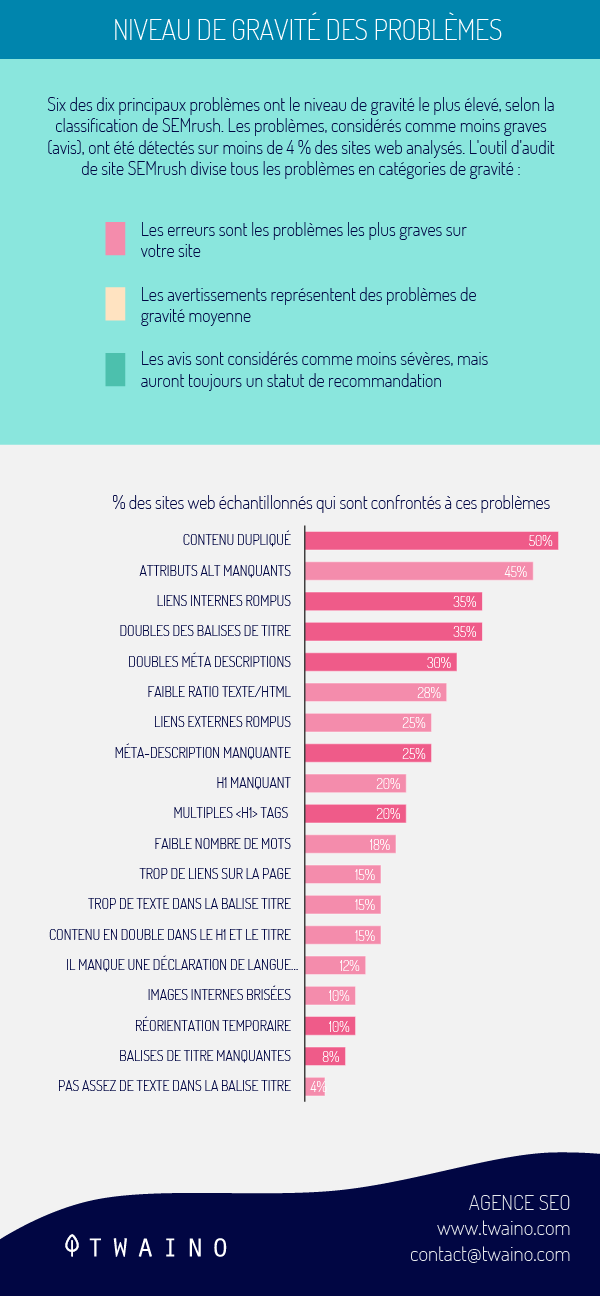
Un’analisi mostra che 50% di siti web hanno problemi di contenuti duplicati.
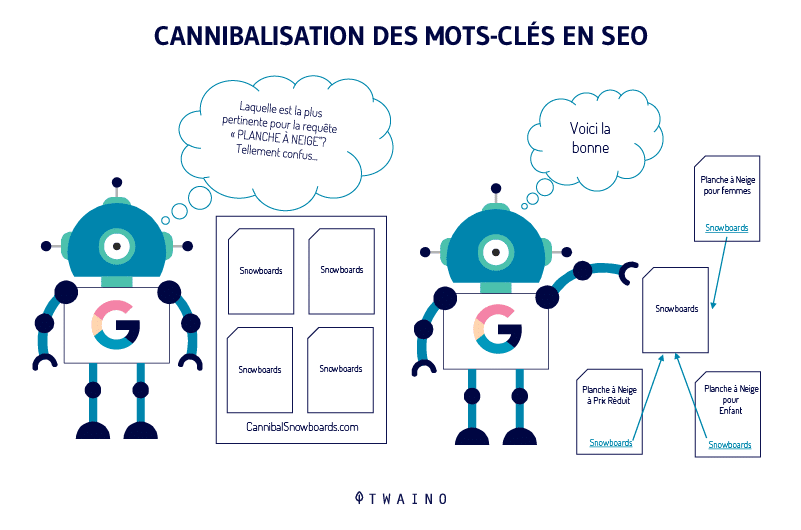
L’obiettivo di Google è quello di mostrare una diversità di siti nei risultati della ricerca. In questo caso, i crawler dei motori di ricerca sono costretti a scegliere quale versione del contenuto classificare
In questo caso, le sue produzioni testuali che lei ritiene più appropriate per un determinato argomento potrebbero non essere classificate a causa della loro somiglianza con altri contenuti esistenti.
In breve, possiamo riassumere i problemi che i siti web devono affrontare con i contenuti duplicati in 3 punti:
- Difficoltà di posizionamento nei risultati di ricerca;
- Visualizzazione di un’esperienza utente scadente;
- E diminuzione del traffico organico.
Ovviamente, questi non sono gli unici problemi legati ai contenuti duplicati, ma sono i più dolorosi per un sito.
Capitolo 2: Quali sono le cause e come individuare i contenuti duplicati?
Come già suggerisce il titolo di questo capitolo, dopo aver spiegato le cause dei contenuti duplicati, le mostreremo come può individuarli.










2.1. Quali sono le cause dei contenuti duplicati?
Ci sono molte ragioni per cui si possono creare contenuti duplicati, ma ne citeremo alcune:
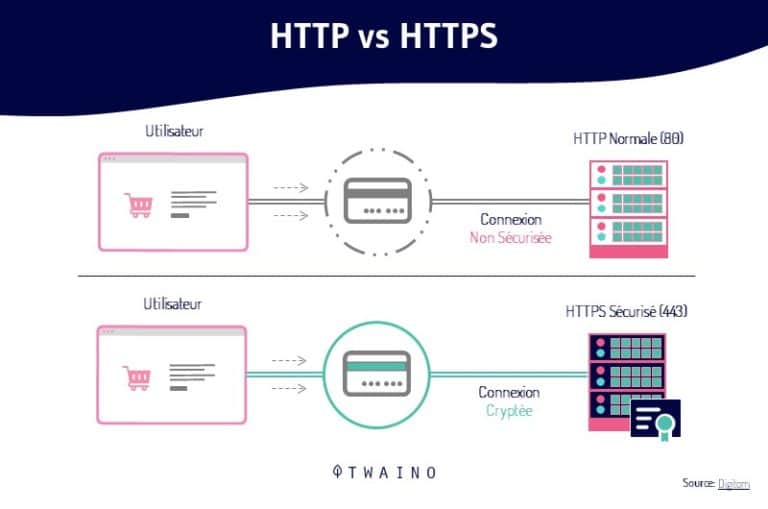
2.1.1. ”HTTP” vs. ”HTTPS” e ”WWW” vs. senza ”WWW”
Aggiungere certificati SSL i certificati del suo sito web sono il modo migliore (o l’unico) per renderlo sicuro. Le permette di trasporre il suo sito web da HTTP a HTTPS
Tuttavia, si tratta di un’azione che comporta la creazione di pagine duplicate sul suo sito web, se non effettua il reindirizzamento.
Inoltre, poiché il contenuto del suo sito web è accessibile da URL con ”WWW” e senza ”WWW”, la duplicazione diventa inevitabile.
I seguenti URL conducono tutti alla stessa pagina, ma sarebbero considerati URL completamente diversi dagli spider dei motori di ricerca:
Si noti quindi che questa situazione è la causa più comune del problema della duplicazione.
2.1.2. Contenuti scraped o copiati
Quando altri siti web “rubano” contenuti da un altro sito, questo si chiama scraping di contenuti. Se Google o altri motori di ricerca non riescono a identificare la versione originale, potrebbero finire per classificare la pagina copiata dal suo sito.
Questo tipo di duplicazione si verifica spesso per i siti che hanno prodotti elencati con descrizioni del produttore
Se lo stesso prodotto è venduto su più siti e tutti questi siti utilizzano le descrizioni del produttore, si possono trovare contenuti duplicati su più pagine di siti diversi.
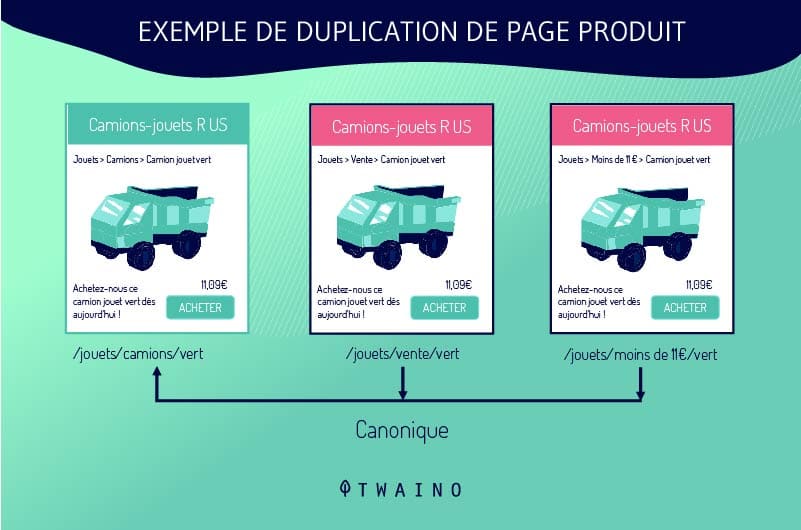
2.1.3. Variazioni dell’URL
Le variazioni negli URL possono verificarsi da
- ID di sessione
- Parametri della query e capitalizzazione
Quando un URL utilizza parametri che non modificano il contenuto della pagina, può finire per creare una pagina duplicata.
Gli ID di sessione funzionano allo stesso modo. Per tenere traccia dei visitatori del suo sito, può utilizzare gli ID di sessione per tracciare ciò che l’utente ha fatto mentre era sul sito e dove è andato
A tal fine, l’ID di sessione viene aggiunto all’URL di ogni pagina su cui si clicca
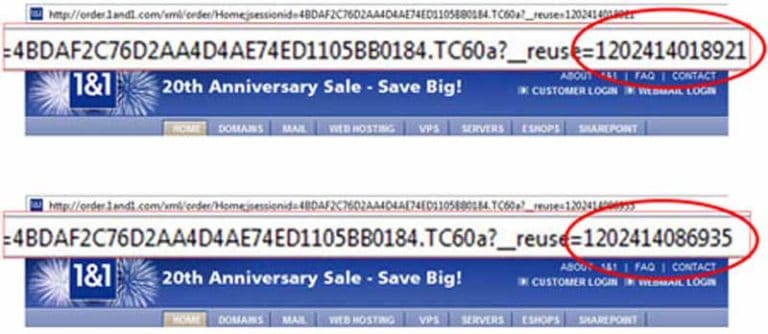
Fonte Polepositionmarketing
Pertanto, l’ID di sessione aggiunto in questo caso crea un nuovo URL alla stessa pagina e viene quindi considerato un contenuto duplicato.
Spesso le lettere maiuscole non vengono aggiunte intenzionalmente, ma è importante assicurarsi che i suoi URL siano coerenti e utilizzino lettere minuscole
Per esempio, twaino.com/blog e twaino.com/Blog sarebbero considerate pagine duplicate.
Ora che ha una buona comprensione di alcune delle cause dei contenuti duplicati, passiamo al loro rilevamento.
2.2 Come individuare i contenuti duplicati
In questa sezione, esamineremo prima i modi gratuiti per trovare contenuti duplicati e poi gli strumenti di rilevamento.
2.2.1. Modi gratuiti per trovare contenuti duplicati
Ecco alcuni modi gratuiti che le permetteranno di farlo:
- Trova i contenuti duplicati;
- Traccia quali pagine hanno più URL;
- E scopre quali sono i problemi che causano la comparsa di contenuti duplicati sul suo sito.
2.2.1.1. Google Search Console
Google Search Console è un potente strumento gratuito a sua disposizione. L’impostazione della sua console la aiuterà a ottenere visibilità sull’andamento delle sue pagine web nei risultati di ricerca
Utilizzando il Copertura nella scheda Indice, può trovare gli URL che potrebbero causare problemi di contenuto duplicato.
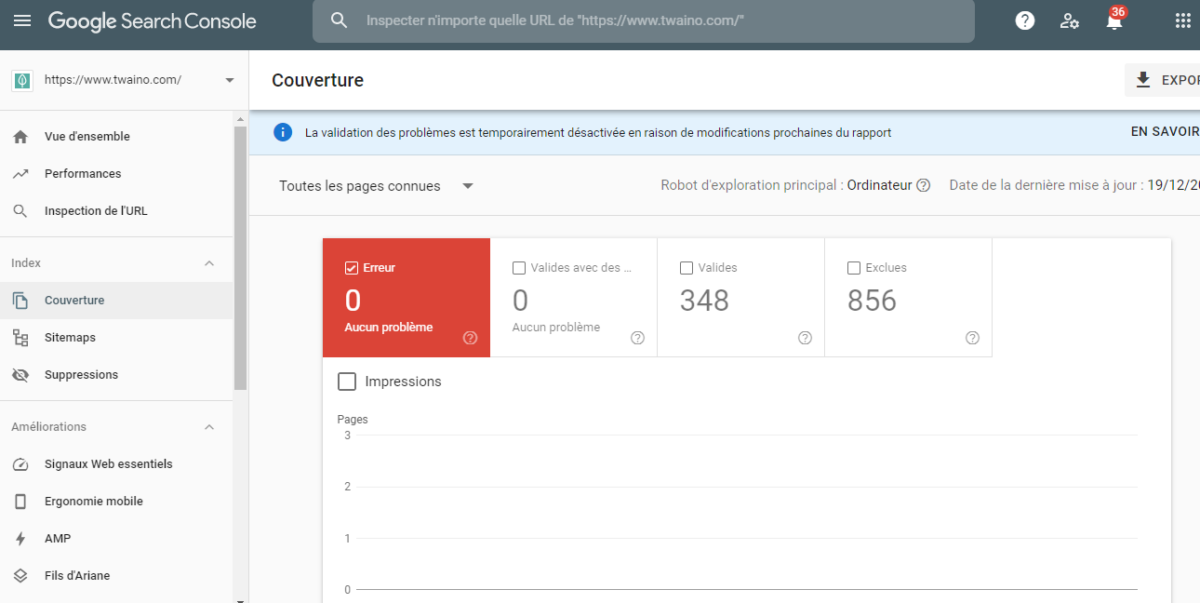
Cercate i problemi più comuni, come ad esempio:
- Versioni HTTP e HTTPS dello stesso URL;
- Versioni www e non www dello stesso URL;
- URL con e senza barra “/” ;
- URL con e senza parametri di query;
- URL con e senza lettere maiuscole;
- Query di coda lunga con classificazioni su più pagine.
Tenga traccia degli URL che scopre con problemi di duplicazione, in modo da poterli rivedere
2.2.2.2. Controllore di contenuti duplicati
SEO Review Tools ha creato questo controllore di contenuti duplicati per aiutare i siti web a combattere il furto di contenuti. Inserendo il suo URL nel loro strumento di controllo, può ottenere una panoramica degli URL esterni e interni che duplicano l’URL inserito.
Ecco cosa è stato trovato quando ho inserito “https://www.twaino.com/” nel checker:
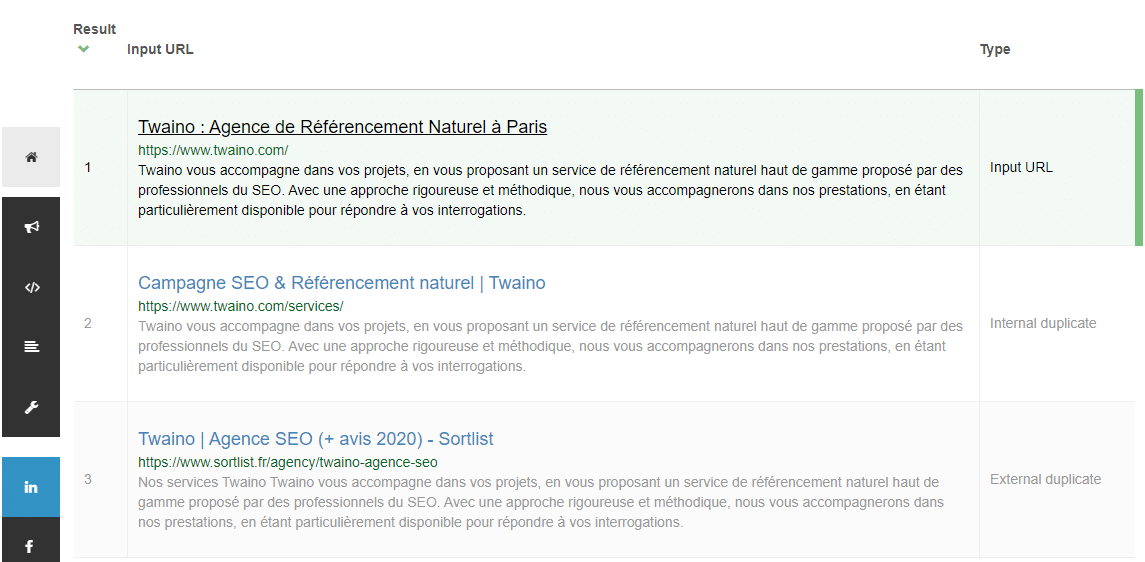
Trovare i contenuti duplicati esterni è molto importante. Come promemoria, i contenuti duplicati esterni si verificano quando qualcun altro ruba contenuti dal suo sito.
Una volta scoperta, può inviare una richiesta di rimozione a Google e rimuovere la pagina duplicata.
2.2.2. Strumenti per trovare contenuti duplicati
Ecco una panoramica dei principali strumenti, sia gratuiti che a pagamento, per rilevare i contenuti duplicati interni ed esterni.
2.2.2.1 Copyscape
Lanciato nel 2004, Copyscape è lo strumento più noto per combattere il plagio e il furto di contenuti. Questo strumento offre un servizio gratuito e a pagamento.
Non è necessario registrarsi per utilizzare la versione gratuita, basta inserire l’URL della pagina da controllare e cliccare su “Vai”.
Ma il difetto di questo strumento nella sua versione gratuita è che non è in grado di riconoscere gli utenti, in quanto non è richiesta la registrazione prima dell’uso
Pertanto, non otterrà alcun risultato se qualcuno ha già effettuato la stessa ricerca.
La versione a pagamento di questo strumento le permette di..:
- Inserisca il testo da controllare;
- Cerca in oltre 10.000 pagine;
- Escludere alcune aree dalla ricerca
Il costo è di 0,05 dollari per ricerca.
2.2.2.2 Dupli Checker
Dupli Checker le permette di controllare il testo inserito manualmente o caricato da un file. È quindi possibile fare un confronto con i risultati rilevati, scoprendo la percentuale dello stesso testo.
2.2.2.3 Plagiarisma
Plagiarisma consente di controllare solo Bing nella versione gratuita. Basta incollare il testo da controllare o l’URL della pagina per avviare il controllo
Esiste una versione a pagamento che dà accesso a funzioni aggiuntive al costo di 0,05 dollari per ricerca.
2.2.2.4 Plagio
Plagium ha due versioni: gratuita e a pagamento. La prima offre un numero limitato di ricerche e funziona solo inserendo il testo che desidera controllare
La seconda costa 0,07 dollari per ricerca e consente di ottenere un numero maggiore di risultati, poiché viene eseguita una ricerca più approfondita. Con la versione a pagamento può controllare anche i documenti in formato Word o PDF.
2.2.2.5 PlagScan
PlagScan è un servizio molto completo, ma a pagamento, con pacchetti a partire da 4,99 dollari per 5000 ricerche di parole
Oltre a identificare le pagine con testo duplicato, può anche vedere dove si trova e confrontare pagine diverse.
2.2.2.6 Quetext
Sarebbe quasi impossibile stilare un elenco di strumenti di rilevamento del plagio senza menzionare Quetext, che gode di una notevole popolarità.
È uno strumento ben sviluppato ed efficace per rilevare le pagine web con contenuti simili ai suoi.
Può anche selezionare l’opzione “calcola punteggio di somiglianza” per ottenere risultati più precisi.
Una volta individuati i duplicati sul suo sito, sarà facile rimuoverli.
Capitolo 3: Come rimuovere o prevenire i contenuti duplicati










La rimozione dei contenuti duplicati aiuterà a garantire che la pagina corretta sia accessibile e indicizzata dagli spider dei motori di ricerca
Tuttavia, potrebbe non voler rimuovere tutti i contenuti duplicati, ma indicare ai motori di ricerca quale versione è quella originale da indicizzare
Ecco come può farlo:
3.1. rel = tag “canonical
Questo grazie all’attributo Rel = tag canonico che gli spider dei motori di ricerca riconoscono la versione duplicata dell’URL di una pagina
I motori di ricerca invieranno quindi tutti i link e il potere di ranking all’URL specificato, poiché lo considereranno la versione originale.
L’uso del rel = canonico non rimuoverà la pagina duplicata dai risultati della ricerca. Semplicemente, consente agli spider dei motori di ricerca di sapere quale pagina originale deve beneficiare in tempo reale di qualsiasi link equity
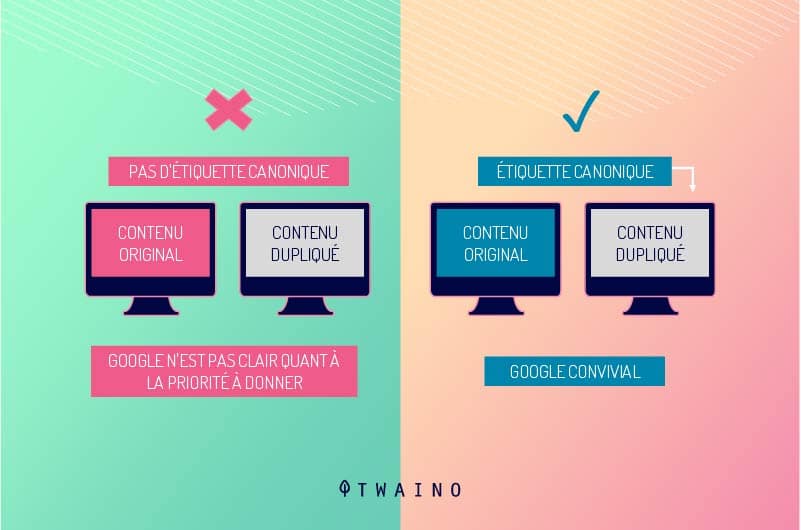
Questi tag rel = canonical sono utili quando la versione duplicata non deve essere rimossa, come nel caso di URL con parametri o barre di separazione.
3.2. Reindirizzamenti 301
L’uso di un 301 reindirizzamento il reindirizzamento è l’opzione migliore se non vuole che la pagina duplicata sia accessibile
Quando imposta un reindirizzamento 301, indica al crawler del motore di ricerca quale pagina sta ricevendo tutto il traffico e i valori SEO.

Al momento di decidere quale pagina mantenere e quali pagine reindirizzare, cerchi la pagina più performante e ottimizzata
Quando combina diverse pagine che competono per le posizioni di classifica in un unico contenuto, creerà una pagina più forte e più rilevante, che i motori di ricerca e gli utenti preferiranno.
3.3. Meta Noindex robot
Il tag noindex è un frammento di codice che aggiunge all’intestazione HTML della pagina che desidera escludere dagli indici dei motori di ricerca
Quando aggiunge il codice “content = noindex, follow”, sta dicendo ai motori di ricerca di effettuare il crawling dei link sulla pagina, ma impedisce loro di aggiungere quel contenuto ai loro indici.

Il tag noindex è anche utile per gestire i contenuti duplicati in paginazione. La paginazione si verifica quando i contenuti si estendono su più pagine, dando luogo a più URL
3.4. Tag canonico autoreferenziale
Per evitare lo scraping di contenuti, può aggiungere il meta tag rel = canonical che punta all’URL in cui si trova già la pagina, creando così una pagina auto-canonica.
L’aggiunta di questo tag indicherà ai motori di ricerca che la pagina corrente è l’originale.
Quando un sito viene copiato, il codice HTML viene estratto dal contenuto originale e aggiunto a un URL diverso
Se il tag canonico è incluso nel codice HTML, probabilmente verrà copiato anche nel sito duplicato, conservando così la pagina originale come versione canonica
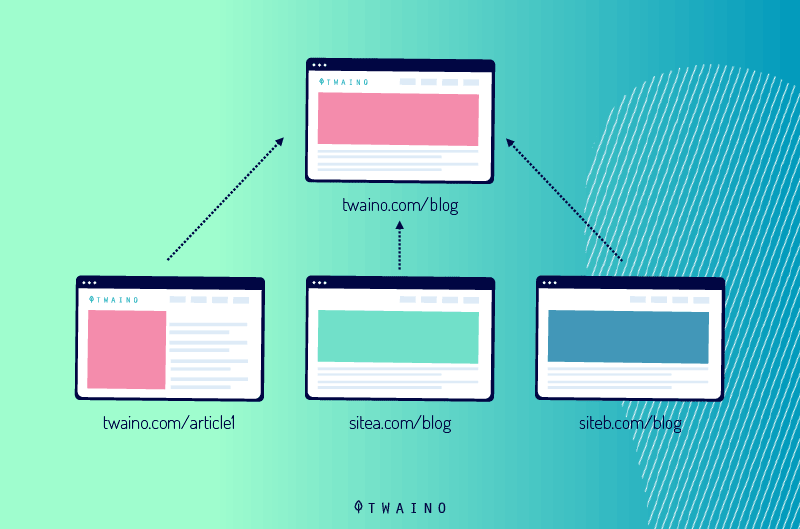
È importante notare che si tratta di una protezione aggiuntiva che funzionerà solo se gli scrapers di testo copiano questa parte del codice HTML.
Capitolo 4: Altre domande poste sui contenuti duplicati
4.1. Che cos’è il contenuto duplicato?
Il contenuto duplicato è quando ci sono due o più contenuti identici o simili all’interno o all’esterno di un sito web.
4.2. Quanto sono dannosi i contenuti duplicati per la SEO?
I contenuti duplicati sono negativi per due motivi principali:
Quando sono disponibili più versioni di contenuti, si riducono le prestazioni di tutte le versioni dei contenuti, poiché sono in concorrenza tra loro.
Inoltre, rende difficile per i motori di ricerca determinare quale versione indicizzare e quindi visualizzare nei risultati della ricerca
4.3. Quali sono i diversi tipi di contenuti duplicati?
Esistono due tipi di contenuti duplicati:
- I contenuti duplicati interni si verificano quando un dominio crea contenuti duplicati attraverso più URL interni (sullo stesso sito web).
- Il contenuto duplicato esterno, noto anche come duplicazione cross-domain, si verifica quando due o più domini diversi hanno la stessa copia di pagina indicizzata dai motori di ricerca.
La duplicazione esterna e interna può avvenire come duplicati esatti o quasi.
4.4. Quali sono i rischi SEO dei contenuti duplicati?
Tecnicamente, i contenuti duplicati possono ancora avere un impatto sul posizionamento nei motori di ricerca. Quando c’è più di un contenuto molto simile, i motori di ricerca hanno difficoltà a decifrare la versione migliore.
Alcuni dei problemi che i siti web possono incontrare con i contenuti duplicati includono Difficoltà di posizionamento nei risultati di ricerca, diminuzione del traffico organico, ecc.
4.5. Come evitare i contenuti duplicati sul suo sito?
Per evitare contenuti duplicati, ha due possibilità:
- Utilizzi GSC per vedere gli URL con contenuti duplicati sul suo sito;
- Utilizzi uno strumento di rilevamento del plagio a pagamento.
4.6. Che cos’è il copia e incolla nella scrittura web?
Il copia e incolla è la pratica di copiare il testo completo di una pagina interna o esterna di un sito per produrre nuovi contenuti. Questa pratica è nota anche come plagio e rappresenta una grande minaccia per il proprietario del sito web.
4.7. Google penalizza i contenuti duplicati?
SÌ! Copiare il lavoro di qualcun altro senza prendere le dovute precauzioni può non solo influire sul posizionamento SEO del suo sito, ma può anche causarne la deindicizzazione dall’indice di Google.
In sintesi
Anche se spesso i contenuti duplicati non vengono creati intenzionalmente, possono danneggiare indirettamente il suo valore SEO e il suo potenziale di ranking, se lasciati incustoditi.
Quando saprà come gestire i contenuti duplicati sul suo sito web, per gli spider dei motori di ricerca sarà più facile svolgere il loro ruolo nell’indicizzazione e nel posizionamento del suo sito.
Ecco perché abbiamo dedicato del tempo a dettagliare ciascuno dei punti citati nell’introduzione di questo articolo
Sta a lei vedere fino a che punto queste diverse nozioni le permetteranno di ottimizzare il suo sito web in modo efficace.
E se ha altri consigli per combattere i contenuti duplicati, non esiti a condividerli con noi nei commenti.
A presto!

