
Disallow è una direttiva che i webmaster utilizzano per gestire i crawler dei motori di ricerca. Lo scopo principale di questa direttiva è quello di indicare a questi bot, in un file Robots.txt, di non effettuare il crawling di una pagina o di un file specifico di un sito web. Al contrario, abbiamo la direttiva Allow che indica ai crawler che possono accedere a questi stessi elementi
La creazione di contenuti di qualità e di backlink sono tecniche popolari per referenziare un sito. Anche se queste tecniche dominano, ci sono molte altre tecniche che contribuiscono alla SEO di un sito web.
La maggior parte di queste tecniche, purtroppo, non sono molto conosciute, anche se alcune di esse si sono rivelate delle vere e proprie risorse per la referenziazione di un sito.
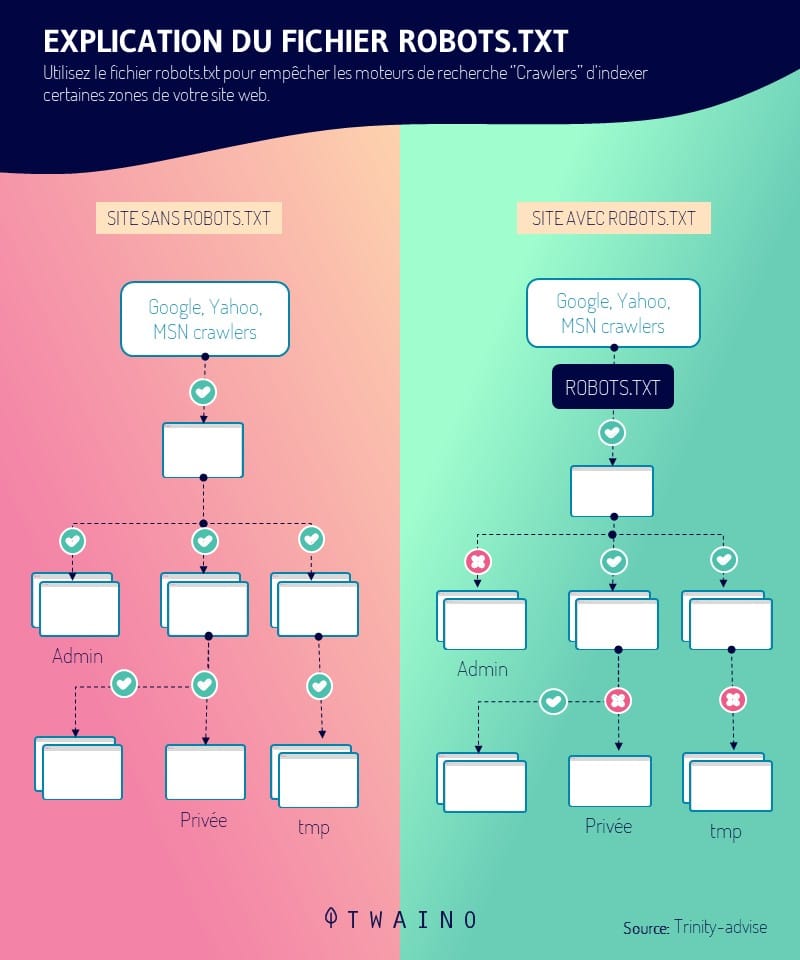
Questo è il caso del file robots.txt, un file che comunica ai motori di ricerca, attraverso diverse direttive, come esplorare le pagine di un sito web. Tra queste direttive, spicca Disallow. Si tratta di uno strumento potente, in grado di influenzare il referenziamento di un sito.
In questo articolo, conosceremo la direttiva Disallow e la sua utilità per la SEO. Infine, esploreremo alcune best practice per evitare errori nel suo utilizzo.
Capitolo 1: Cos’è la direttiva Disallow e come è utile nella SEO?
La direttiva Disallow è una pratica SEO legittima che molti webmaster già utilizzano. Questo capitolo è dedicato alla definizione di questa direttiva e alla sua importanza nel mondo SEO.
1. Che cos’è la direttiva Disallow?
Come altri tag come Nofollow, la direttiva Disallow influenza il comportamento dei web crawler come Googlebot e Bingbot verso determinate sezioni di un sito web.

Questi bot funzionano come archivisti di Internet e raccolgono contenuti web per catalogarli. Per farlo, effettua il crawling di tutti i siti web per scoprire nuove pagine e indicizzarle.

I webmaster sono in grado di dare diverse istruzioni ai crawler che accedono ai loro siti tramite un file robots.txt. La direttiva Disallow è una di queste istruzioni.
Permette ai webmaster di bloccare l’accesso a determinate risorse su un sito web. Di conseguenza, i web crawler non saranno in grado di scansionare gli URL che sono stati bloccati utilizzando la direttiva Disallow.
Questa direttiva viene talvolta utilizzata insieme alla direttiva consentire la direttiva. A differenza della direttiva Disallow, dà accesso ai browser e indica loro quali risorse devono esplorare.

Va ricordato che sono solo i bot dei motori di ricerca a comprendere il linguaggio utilizzato nel file robot.txt. I bot che non utilizzano questo linguaggio, come i bot maligni, possono quindi accedere alle risorse bloccate dalla direttiva Disallow.
1.2 Dove si trova la direttiva Disallow?
La direttiva Disallow è inclusa in un file robots.txt, come già detto. Questo file si trova nella radice di un sito, al livello superiore (www.votresite.com/robots.txt).
I bot possono trovare il file robots.txt solo nella posizione sopra indicata. Il nome corretto è robots.txt e altre voci come Robots.txt o robots.TXT vengono semplicemente ignorati.

Il file robots.txt ha altre direttive che sono :
- Disconoscere ;
- Negare ;
- Ordine ;
- Ecc.
Il file robots.txt rimane pubblicamente accessibile e può essere visualizzato per qualsiasi sito web. Appare quando si aggiunge “/robots.txt” alla fine di un dominio. Questo le permette di vedere tutte le direttive di un sito, quando ha questo file.

Il link da aprire nel suo browser si presenta così: www.votresite.com/robots.txt. Quando il file robots.txt non si trova a questo indirizzo, i bot presumono che il sito non disponga di tale file.
1.3. Qual è l’importanza della direttiva Disallow?
La direttiva Disallow può essere utilizzata per molte ragioni. Insieme alle altre direttive del file robots.txt, aiuta a migliorare il ranking di un sito.
Queste direttive aiutano a indirizzare i crawler verso le risorse e a scansionare solo quelle utili.
1.3.1. Ottimizzare il budget di crawl
La direttiva Disallow è spesso utilizzata per proibire ai crawler di effettuare il crawling di pagine che non sono di reale interesse per il SEO di un sito web. Questo è ciò che Google cerca di spiegarlo nel seguente passaggio:
“Non vuole che il suo server venga sovraccaricato dal crawler di Google o che sprechi il suo budget di crawling su pagine poco importanti o simili del suo sito.“
In parole povere, Google assegna ai suoi bot un cosiddetto crawl budget per ogni sito web. Questo budget è il numero di URL che i Googlebot possono scansionare sul sito.

Ma quando i bot arrivano su un sito, iniziano a fare il crawling di ogni sua pagina. Più pagine ha un sito, più tempo ci vorrà per effettuare il crawling.
Ecco perché è necessario aiutare i bot a ignorare le pagine non importanti con la direttiva Disallow e indirizzarli con Allow verso le pagine importanti che meritano di essere classificate.
Detto questo, inserendo buone istruzioni nel file robots.txt con Disallow, i webmaster aiutano i bot a spendere il budget di crawling in modo saggio. Questo è uno dei motivi per cui la direttiva Disallow è particolarmente utile per la SEO.
Inoltre, la direttiva Disallow mantiene le sezioni di un sito web private e aiuta a prevenire il sovraccarico del server. Può anche essere utilizzato per impedire che alcune risorse, come le immagini o i video, appaiano nei risultati di ricerca.
1.3.2. Disallow impedisce a una pagina di essere indicizzata?
La direttiva Disallow non impedisce a una pagina di essere indicizzata, ma piuttosto impedisce il crawling.
Pertanto, un URL bloccato con Disallow può apparire nei risultati di ricerca quando Google trova contenuti rilevanti per una query. Può essere classificato anche quando ci sono backlink e tag canonici che puntano ad esso.
Tuttavia, Google sarà in grado di visualizzare solo informazioni diverse dall’URL della pagina. Quest’ultimo appare quindi al posto del titolo. Per la meta descrizione, il motore di ricerca mostra un messaggio che indica che non è disponibile a causa di un file robots.txt.
Per evitare che i motori di ricerca dall’indicizzazione di una pagina webviene utilizzato il tag Noindex. Dice loro di non considerare la risorsa in questione nelle SERP.
Bisogna anche ricordare che le direttive Disallow e Noindex possono essere combinate. Il tag Noindex le consentirà di escludere dall’indice alcune delle sue pagine ed evitare problemi quali contenuti duplicati.
Si noti che questo tag è diverso da Nofollow, un tag che viene utilizzato quando si vuole dire a Google di indicizzare la pagina, ma di non seguire i link su quella pagina.

Il Noindex e il Nofollow può essere combinato quando non vuole che la pagina in questione sia indicizzata e che i suoi link non siano seguiti.
Capitolo 2: Forme di applicazione di Disallow e best practice per evitare errori
L’applicazione della direttiva Disallow è particolarmente semplice e richiede solo una conoscenza della sintassi e dei caratteri generali. Questo capitolo illustra le forme di applicazione della direttiva Disallow e le buone prassi per evitare errori.
2.1. Utilizzando gli agenti-utenti per specificare i motori di ricerca
Per applicare la direttiva Disallow e le direttive robots.txt, deve prima impostare gli utenti-agenti a cui è destinato il messaggio. Questi sono i bot che prenderanno in considerazione le istruzioni per la direttiva.
Per indicare che sono destinati a tutti i bot, viene utilizzato il simbolo (*) come di seguito.

Ma quando ci rivolgiamo esclusivamente ai Googlebot, procediamo come segue:
- user-agent: Googlebots
Quando ci rivolgiamo solo ai Bingbot, scriviamo :
- user-agent : Bingbot
La registrazione di un user-agent segna anche l’inizio delle istruzioni per un insieme di direttive. Quindi, tutte le direttive tra un primo agente-utente e un secondo agente-utente vengono trattate come direttive del primo agente.

Inoltre, l’asterisco (*) rappresenta l’insieme dei caratteri possibili, mentre il segno del dollaro ($) rappresenta il modo in cui gli URL vengono terminati. Il segno di cancelletto (#) viene utilizzato per iniziare un commento.
I commenti sono riservati agli esseri umani e non sono supportati dai robot. Questi tre simboli sono chiamati jolly e una loro errata gestione può causare problemi al suo sito.
2.2. Le diverse forme di applicazione di Disallow
La sintassi di Disallow varia a seconda del tipo di applicazione.
2.2.1. Disconoscere:
Quando mette Disallow: senza aggiungere nulla dopo, sta dicendo ai crawler che non ci sono restrizioni. Ciò significa che tutto ciò che è presente sulla sua pagina è buono per imparare e i bot possono esplorare tutto.

Lei sa che questa sintassi non è utile, in quanto i motori di ricerca effettueranno comunque il crawling del suo sito in sua assenza.
2.2.2. Disallow:/
Questa direttiva si legge Disallow all e le consente di non consentire un intero sito. Quando utilizza questa sintassi, i robot degli agenti-utente definiti non saranno in grado di effettuare il crawling del suo sito. Questa sintassi può essere utilizzata, ad esempio, quando un sito è ancora in manutenzione.

2.2.3. Disallow: blog
Questo codice le permette di bloccare l’accesso a tutte le pagine il cui URL inizia con blog. Pertanto, tutti gli indirizzi che iniziano con https://www.votresite.com/blog saranno semplicemente ignorati durante l’esplorazione.

2.2.4. Disallow:/*.pdf
È possibile impedire il crawling di un particolare tipo di file e questo codice lo fa proprio con i file PDF. Ciò consentirà ai crawler di ignorare i file di questo tipo durante il crawling dei seguenti URL:
- https://www.votresite.com/contrat.pdf
- https://www.votresite.com/blog/documents.pdf
È anche possibile aggiungere il simbolo ($) alla nostra sintassi per dire ai bot che tutte le pagine con URL che terminano con (.pdf) devono essere ignorate.
2.3. Disallow VS Allow
Le direttive Disallow e Allow possono essere utilizzate insieme in un file robots.txt. Se utilizzati insieme, l’uso di caratteri jolly potrebbe portare a istruzioni contrastanti.

Inoltre, i bot di Google spesso eseguono la direttiva meno restrittiva quando le istruzioni non sono chiare. Ma quando le direttive Disallow e Allow corrispondono allo stesso URL in un file robots.txt, vince l’istruzione più lunga.
La lunghezza dell’istruzione è il numero di caratteri dell’istruzione al di fuori della direttiva. Questo è il percorso della direttiva che i bot seguiranno. Negli esempi seguenti, verrà eseguita la seconda istruzione.
- Disconoscere /esempio* (9 caratteri)
- Consenti /esempio.htm $ (13 caratteri)
- Consenti /*pdf$(6 caratteri)
2.4. Le migliori pratiche per evitare errori
Una configurazione errata del file robots.txt o un’istruzione sbagliata della direttiva Disallow possono rallentare le prestazioni SEO del suo sito. Ecco perché è importante fare attenzione a non bloccare le risorse per errore.
D’altra parte, non dovrebbe bloccare i dati sensibili solo con la direttiva Disallow. Come già detto, una pagina bloccata può comunque apparire nei risultati di ricerca e diventare pubblica.

Inoltre, i bot malintenzionati che non seguono le linee guida di robots.txt possono scorrere le pagine che dovrebbero essere protette con Disallow. Poiché il file robots.txt è pubblico, chiunque può guardarlo e scoprire cosa sta cercando di nascondere.
Per quanto riguarda gli agenti-utente, è necessario sapere come utilizzarli per essere precisi nel registrare le istruzioni delle varie direttive. Tenga presente che un motore di ricerca può avere diversi bot quando definisce gli agenti.
Ad esempio, Google utilizza Googlebot per la ricerca organica, ma Googlebot-Image per la ricerca di immagini.
Capitolo 3: Altre domande sulla direttiva Disallow
In questo capitolo esaminiamo le domande che vengono regolarmente poste in relazione alla direttiva Disallow.
3.1) Che cos’è un robots.txt?
Un file robots.txt fornisce istruzioni ai motori di ricerca sulle sue preferenze di crawling. Questo file è sensibile nel mondo della SEO e un piccolo errore può compromettere un intero sito.
Ma se usato con saggezza, invia buoni segnali a Google e aiuta il suo sito a posizionarsi bene. Per modificare un file robots.txt, deve semplicemente collegarsi al suo server tramite un client FTP e poi apportare le modifiche.
Se non riesce ad effettuare la connessione, può contattare il suo host web. Tuttavia, se deve creare un nuovo file robots.txt, può farlo da un editor di testo semplice.
In questo caso, si assicuri di eliminare quello vecchio, se ne ha già uno sul suo sito. Faccia attenzione a non utilizzare un editor di testo come Word, potrebbe introdurre altro codice nel suo testo.
3.2) Che cos’è il crawling?
Conosciuto anche come crawling, il crawling delle pagine web è un processo in cui i motori di ricerca inviano dei robot (spider) per esaminare il contenuto di ogni URL.
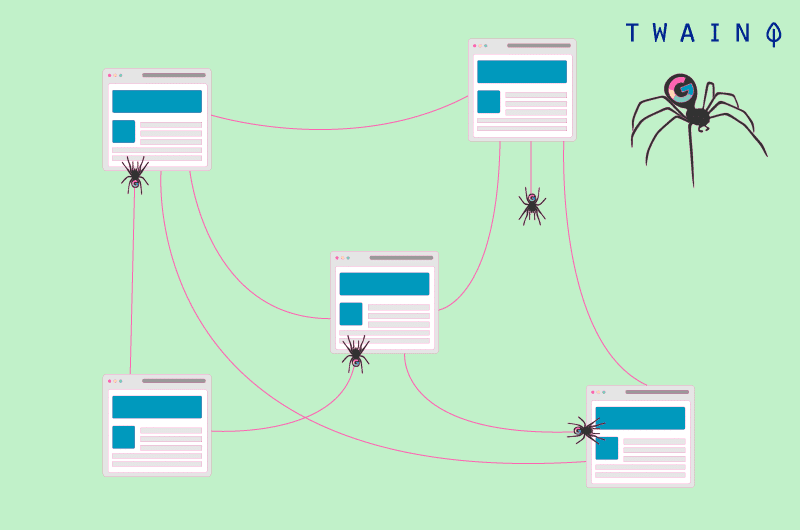
Questi spider si spostano da una pagina all’altra per trovare nuovi URL o contenuti. È questo primo passo che consente ai motori di ricerca di scoprire i suoi contenuti e di programmarli per l’indicizzazione.
Il file del robot entra in gioco in questa fase e guida i bot in base alle sue preferenze. Il crawling si distingue dall’indicizzazione, in quanto quest’ultima consiste nell’archiviare e organizzare i contenuti trovati durante il crawling.
3.3. Quali pagine possono essere bloccate utilizzando la direttiva Disallow?
I motori di ricerca non hanno una regola universale su quali pagine bloccare. L’uso della direttiva Disallow è quindi specifico per il sito e dipende dal giudizio del webmaster.
Tuttavia, questa direttiva può aiutare a indicare agli spider di non effettuare il crawling delle pagine in esame. Può anche essere utilizzato per impedire l’accesso a determinate pagine, come le pagine di ringraziamento.
Quando lavora su un sito multilingue, ad esempio, può bloccare la versione inglese se non è pronta e impedire agli spider di esplorarla.
Per quanto riguarda la pagina di ringraziamento, in genere è destinata ai nuovi potenziali clienti. Queste pagine possono ancora spendere i budget di crawl e apparire nei risultati di ricerca.

Quando appare nei risultati di ricerca, la pagina di ringraziamento è disponibile per chiunque e può accedervi senza passare attraverso il processo di acquisizione dei contatti.
Ma bloccando la pagina di ringraziamento, si assicura che i potenziali clienti qualificati possano accedervi. In questo caso, la sola direttiva Disallow non sarà sufficiente, poiché non impedisce all’URL in questione di essere indicizzato.
Detto questo, la pagina in questione può ancora apparire nelle SERP. È quindi consigliabile combinare la direttiva Disallow con la direttiva Noindex. Questo impedirà ai crawler di visitare e indicizzare la pagina.
Conclusione
Nel complesso, ci sono molte azioni che possono essere intraprese per migliorare il ranking di un sito. La direttiva Disallow è una di queste azioni che le offre un vantaggio reale in termini di referenze.
Le consente di vietare agli spider dei motori di ricerca di effettuare il crawling di contenuti non utili, al fine di ottimizzare il budget di crawl di un sito web.
In questo modo, permette agli spider di utilizzare quel budget nel modo migliore per aumentare la visibilità dei suoi contenuti nei risultati di ricerca.
L’uso della direttiva Disallow può quindi avere un impatto significativo quando le istruzioni sono fornite correttamente. Tuttavia, può rompere un intero sito quando le istruzioni sono sbagliate.

