
DUST, o URL diversi con testo simile, si verifica quando più URL di un sito rimandano a una pagina dello stesso sito. Spesso si tratta di contenuti a cui si può accedere da posizioni diverse dello stesso dominio o con mezzi diversi. Conosciuto anche come URL duplicato, il DUST confonde i motori di ricerca quando i crawler devono scansionare e indicizzare gli URL duplicati. DUST riduce l’efficienza del crawling e diluisce l’autorità della pagina principale.
La creazione di contenuti è la responsabilità principale dei webmaster quando si tratta di classificare un sito web. Anche se l’ideale è creare contenuti unici, è difficile farlo senza contare gli scrapers di contenuti che duplicheranno i suoi.
I contenuti duplicati rappresentano il 25-30% dei contenuti web e non tutti sono il risultato di un intento disonesto. Può anche essere creato involontariamente su un sito, senza che i webmaster se ne rendano conto.
Questo è il caso di Different URLs with Similar Text (DUST), dove un URL può essere duplicato centinaia di volte. La stragrande maggioranza dei siti web si trova di fronte a questo problema e le sue cause sono numerose.
Ma in termini concreti;
- Che cos’è la POLVERE?
- Come appaiono gli URL di DUST su un sito?
- Quali sono i potenziali problemi di DUST?
- Come posso correggere i problemi legati a DUST?
In questo articolo, fornirò risposte esplicite a queste domande per demistificare DUST. Scopriremo anche come evitare che questo problema si verifichi su un sito.
Quindi seguiteci!
Capitolo 1: Che cos’è DUST e quali problemi causa in termini di SEO?
I contenuti duplicati sono uno dei 5 principali problemi SEO che i siti devono affrontare e il DUST è solo una forma di contenuto duplicato.
Questo capitolo illustra la definizione di DUST e i problemi SEO che può causare ad un sito.
1.1. POLVERE: Cosa c’è?
I contenuti duplicati sono comuni sul web e Google li definisce come contenuti dello stesso sito o di altri siti che corrispondono ad altri contenuti o sono quasi simili.
Attraverso questa definizione, possiamo vedere che i contenuti duplicati si verificano a due livelli: sullo stesso dominio o tra diversi domini.

Quando si verifica sullo stesso sito, può assumere la forma di contenuti che appaiono in pagine diverse di un dominio o di una pagina accessibile da più URL.
In quest’ultimo caso, i contenuti duplicati si chiamano DUST. Mentre altre forme di contenuto duplicato sono legate alla creazione di contenuti, il DUST è più un risultato della duplicazione di URL.

Questa duplicazione di URL è molto comune e spesso è il risultato di un problema tecnico che tutti i siti web possono incontrare prima o poi. I seguenti URL puntano tutti allo stesso sito e sono un esempio di DUST.
- www.votresite.com/ ;
- yoursite.com ;
- http://votresite.com ;
- http://votresite.com/ ;
- https://www.votresite.com;
- https://votresite.com.
Sebbene questi URL sembrino uguali e si rivolgano alla stessa pagina, le sintassi non sono le stesse e questo può causare problemi a un sito web
1.2. Perché DUST o gli URL duplicati sono un problema?
A differenza di altre forme di contenuti duplicati, il DUST non danneggia direttamente il SEO di un sito web. Infatti, Google capisce perfettamente che questa duplicazione non è dannosa.

Tuttavia, DUST pone tre problemi principali ai motori di ricerca. I motori di ricerca non sono in grado di :
- Identifica quali URL includere o escludere dal proprio indice;
- Conoscere l’URL a cui assegnare le metriche dei link, come fiducia, autorità, correttezza..
- Identificare quali URL devono essere classificati nei risultati di ricerca.
Per capire questi problemi, vediamo come funzionano i motori di ricerca. Riesce a visualizzare i risultati della ricerca attraverso tre funzioni principali:
- Strisciare ;
- Indicizzazione;
- Classifica.

Il crawling del web è il processo con cui i motori di ricerca scoprono i contenuti web nuovi e aggiornati di recente. Inviano dei robot, chiamati spider, che si spostano da un URL all’altro di un sito.
Quando diversi URL conducono alla stessa pagina, gli spider li considerano come URL diversi e effettuano il crawling di ciascuno di essi. Poi scoprono che i contenuti di questi diversi URL sono gli stessi e li trattano come contenuti duplicati.
Nel corso del crawling, i bot sono in grado di aggiungere le nuove risorse interessanti che trovano all’indice, un enorme database di URL.
Anche se questo può accadere, gli spider evitano di indicizzare la stessa pagina più volte e si concentrano sull’indicizzazione solo delle pagine che offrono contenuti unici. Pertanto, gli spider potrebbero dover fare delle scelte su quali URL indicizzare.

Possono includere nell’indice qualsiasi URL che potrebbe non essere quello giusto o quello che lei desidera indicizzare.
Inoltre, è dai contenuti indicizzati che i motori di ricerca scelgono i contenuti rilevanti quando un utente effettua una ricerca. È quindi ovvio che una pagina che non esiste nell’indice non può apparire nei risultati della ricerca.
1.in che modo la polvere può danneggiare il suo SEO?
Gli URL duplicati possono danneggiare la SEO di un sito in diversi modi.
1.3.1. Ridurre l’efficienza dello strisciamento
Il fatto che gli URL duplicati puntino tutti alla stessa pagina e che i robot effettuino comunque la scansione di ciascuno di essi può ridurre l’efficienza della scansione dei robot.
Questo perché Google assegna un budget di crawl a tutti i siti. Questo budget rappresenta il numero di URL che i crawler possono seguire su un sito. Più URL ci sono, più è probabile che il budget per il crawling venga esaurito.

Tuttavia, i crawler non saranno in grado di scansionare tutte le pagine quando il budget è esaurito e potrebbero non essere in grado di scansionare tutte le pagine rilevanti del sito.
È quindi fondamentale che i proprietari dei siti lavorino per ottimizzare il budget di crawl, in modo da consentire ai crawler di seguire tutti gli URL rilevanti.
1.3.2. Perdita di traffico e diluizione del patrimonio netto
Quando i motori di ricerca indicizzano un URL con una struttura strana tra gli URL duplicati, gli utenti possono avere dei dubbi quando appare nei risultati di ricerca. Questo può portare a una perdita di traffico, nonostante il buon posizionamento.
Può anche accadere che i robot indicizzino diversi URL tra i duplicati. Anche in questo caso, gli URL vengono considerati in modo diverso. Ognuno di essi ottiene autorità e classifiche diverse.

Questo diluisce la visibilità di tutti i duplicati. Questo perché ognuno degli URL duplicati può catturare backlink, mentre questi link possono puntare tutti all’URL principale.
1.4. Come appaiono gli URL duplicati?
I webmaster non duplicano gli URL intenzionalmente. Il DUST si verifica spesso quando i siti utilizzano un sistema che crea più versioni della stessa pagina. Questa situazione è comune nei siti di e-commerce, soprattutto nelle schede prodotto.
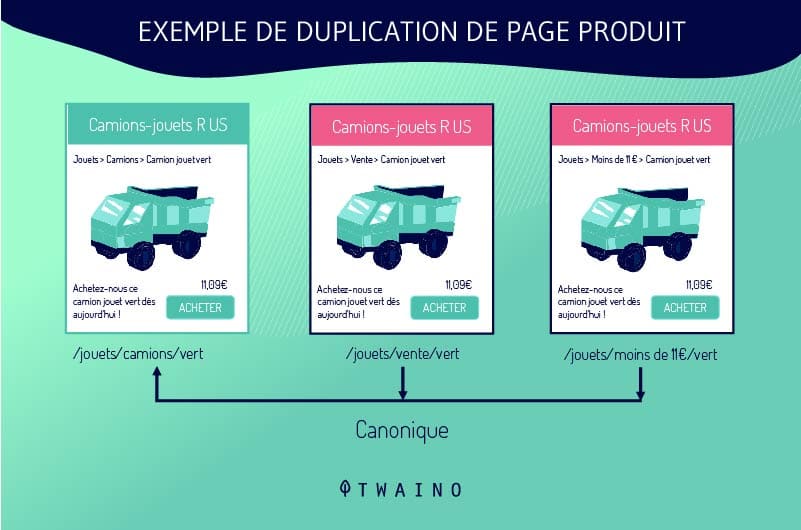
Le schede dei prodotti sono configurate in modo da consentire ai clienti di scegliere tra diverse dimensioni o colori rimanendo sulla stessa pagina. Il sistema di gestione dei contenuti genera quindi più URL DUST che rimandano a una singola pagina.
Ad esempio, se un sito offre una camicia blu in tre taglie diverse, il sistema può generare i seguenti URL:
- shoponline.com/blueshirt-A ;
- shoponline.com/blueshirt-B;
- shoponline.com/blueblouse-C.
Gli URL duplicati sono anche il risultato dei filtri che i siti offrono per facilitare la ricerca ai loro visitatori. Le diverse combinazioni generano tutte link DUST, che purtroppo i motori di ricerca considerano in modo diverso.
I siti creano anche URL duplicati quando pubblicano una versione stampabile di una pagina. Allo stesso modo, anche gli URL duplicati provengono da:
- URL dinamici;
- Versioni vecchie e dimenticate di una pagina;
- ID della sessione.
Si noti anche che gli URL sono sensibili alla presenza o meno della barra (/) alla fine. Ad esempio, Google tratterà in modo diverso example.com/page/ e example.com/page.
Pertanto, questi due URL saranno trattati come URL duplicati, anche se accedono allo stesso contenuto.
Capitolo 2: Come identificare gli URL DUST e come correggerli
La correzione degli URL DUST può avere un effetto significativo sulla SEO di un sito web. In questo capitolo, scopriremo come rilevare questi URL e i diversi modi in cui possono essere trattati.
2.1. Come trovare gli URL duplicati
È fondamentale rilevare gli URL DUST per correggere questo problema. Fortunatamente, esistono suggerimenti e strumenti online che le consentono di verificare la presenza di URL duplicati su un dominio.
2.1.1. Strumenti di verifica degli URL duplicati
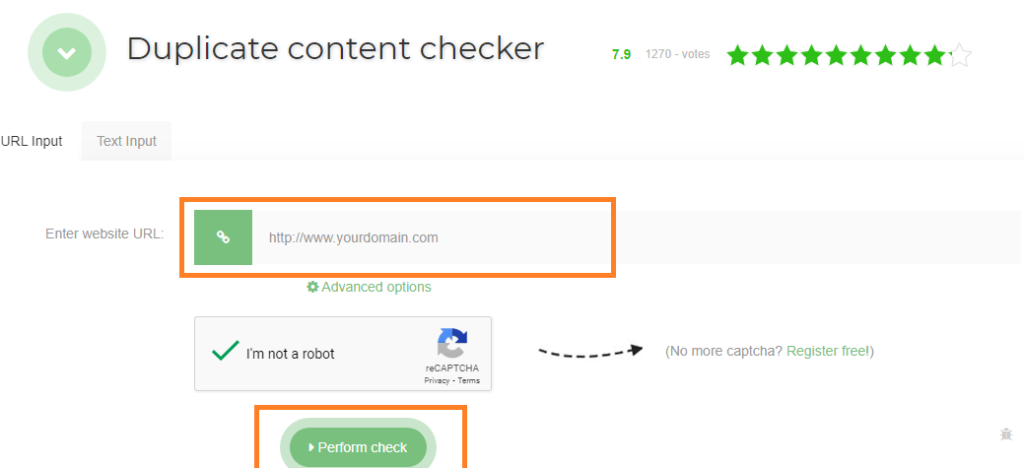
Tra gli strumenti per controllare gli URL duplicati, suggerisco Seo Review Tools. Basta inserire l’URL mirato nella barra riservata a questo scopo e cliccare su “Esegui verifica”. Lo strumento le mostrerà il numero di duplicati dell’URL che ha inserito.
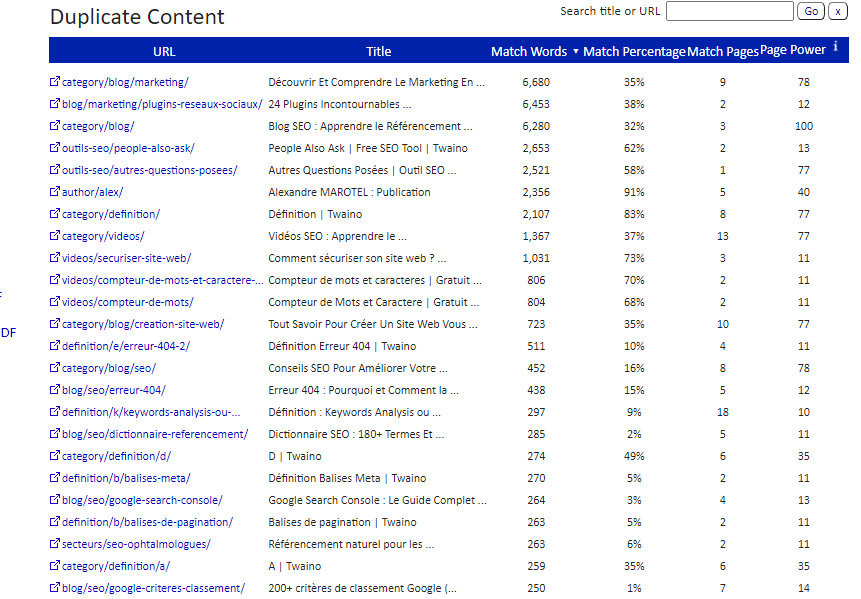
Siteliner è anche un potente strumento per trovare URL duplicati su un dominio. Esamina il suo dominio e le mostra un rapporto sui link duplicati presenti sul suo sito.
Per utilizzare questo strumento, basta inserire il suo dominio nella barra di ricerca. Quando Siteliner le mostra l’analisi del suo sito, clicchi su “contenuto duplicato” per visualizzare gli URL duplicati.
2.1.2. Utilizzando l’operatore di ricerca site:example.com intitle :
Può anche verificare la presenza di URL duplicati sul suo sito, utilizzando gli operatori di ricerca site:example.com intitle: “la sua parola chiave”. Google le mostrerà gli URL del suo dominio (example.com) che contengono la parola chiave mirata.
Basta osservare gli URL che Google le mostra per vedere quali URL rimandano alla stessa pagina. Ora che può trovare URL duplicati sul suo sito, passiamo alle azioni correttive che può intraprendere.
2.2 Come correggere gli URL di DUST
2.2.1. 301 reindirizzamento
Ilreindirizzamento 301 è un modo per inviare gli utenti e i motori di ricerca a un indirizzo diverso da quello richiesto in modo permanente. Nel caso degli URL DUST, consiste nel reindirizzare i duplicati all’URL originale.
In questo modo, i diversi URL che probabilmente saranno classificati in modo diverso vengono raggruppati in uno solo e cessano di competere. Inoltre, tutti gli URL trasmettono l’intero equipaggiamento all’URL principale.

Questo URL beneficia quindi del potere di referenziazione dei suoi duplicati. Questo avrà naturalmente un impatto significativo sulla referenziazione della pagina in questione. Si noti, tuttavia, che il reindirizzamento 301 non rimuove il duplicato DUST.
2.2.2. Il tag rel=canonical
Il tag rel=canonical rimane uno dei modi migliori per trasferire il potenziale di riferimento di una pagina duplicata ad un’altra pagina. Si tratta di un tag HTML che indica semplicemente ai motori di ricerca quale URL aggiungere ai loro indici.

Google definisce l’URL canonico come l’URL più rappresentativo di un gruppo di contenuti duplicati. Questo URL è quello che i crawler seguiranno regolarmente per ottimizzare il budget di crawling di un sito. Gli altri saranno visitati meno frequentemente.
Google e altri motori di ricerca attribuiscono il pieno potenziale SEO degli URL duplicati all’URL canonico. Il tag rel=canonical viene aggiunto all’intestazione di una pagina HTML.
I motori di ricerca considerano le altre pagine come duplicati dell’URL canonico e non le fanno sparire. Questo è molto vantaggioso, soprattutto perché sicuramente non vuole che tutti i duplicati vengano rimossi.
2.2.3. Utilizzo di meta robot
L’uso dei meta-robot è semplice ed efficace quando si tratta di impedire che le pagine appaiano nei risultati di ricerca. Consiste nell’aggiungere i tag Noindex e Nofollow al codice HTML di una pagina.

Il tag Noindex indica ai motori di ricerca che lei non vuole che aggiungano un URL ai loro indici e quindi che non lo visualizzino nei risultati della ricerca.
È sufficiente aggiungere il tag Noindex agli URL duplicati per evitare che entrino in competizione con l’URL principale.
Il tag Nofollow indica a Google di non seguire un link e di non trasmettere la sua autorità alle pagine a cui si collega. Pertanto, gli spider ignoreranno tutti i link che includono il tag Nofollow.
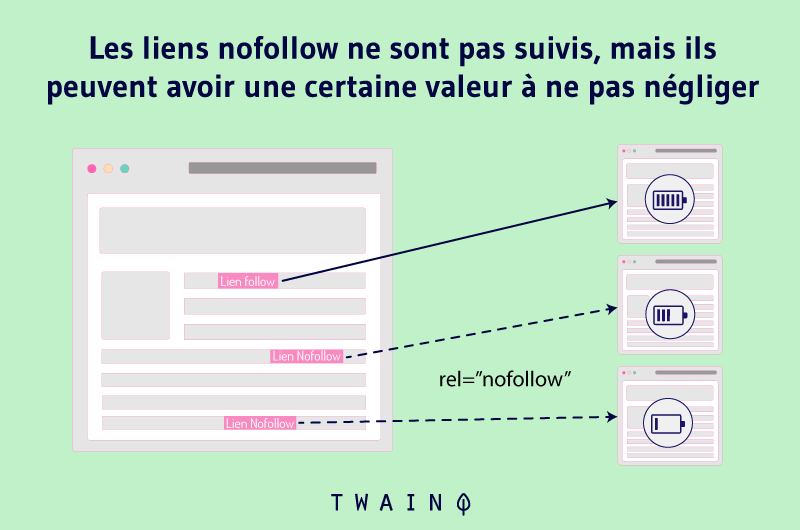
L’aggiunta di questo tag agli URL duplicati può quindi aiutarla a correggere i problemi legati alla duplicazione degli URL.
2.2.4. Impostazione in Google Search Console
L’inserimento di tag canonici e di meta bot in centinaia di pagine DUST è spesso molto impegnativo. Fortunatamente, le impostazioni di Google Search Console possono essere parte della soluzione agli URL DUST.
2.2.4.1. Impostazione della versione URL del suo sito
La definizione dell’indirizzo di un dominio può anche aiutare a risolvere i problemi di DUST. I webmaster possono impostare una preferenza per il loro dominio in questo strumento e specificare se gli spider devono effettuare il crawling di determinati URL.
Invece dihttp://www.votresite.com, possono specificare chehttp://votresite.com è l’indirizzo del loro dominio. Si noti l’assenza di www e lo stesso vale per i protocolli HTTP e HTTPS, con l’assenza di S.
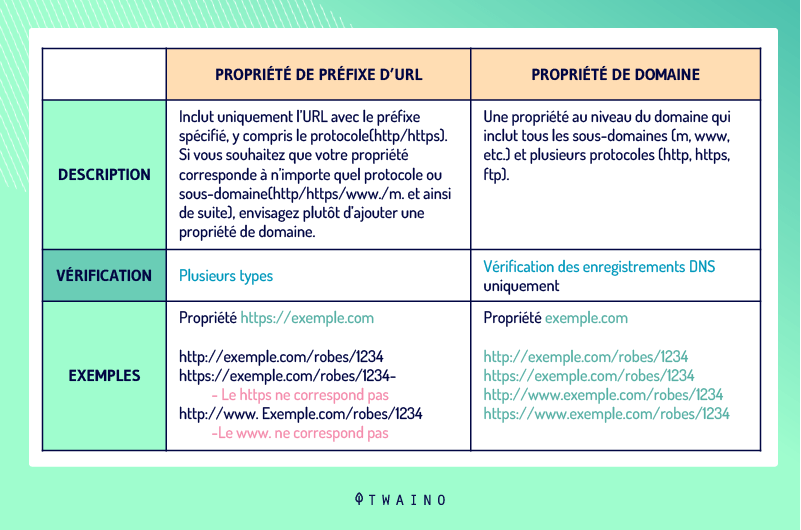
Per procedere all’impostazione della versione dell’URL del suo sito, vada su Google Search Console e scelga “Aggiungi proprietà”
2.2.4.2. Gestione dei parametri URL
La configurazione delle impostazioni URL in Google Search Console le consente di specificare quali impostazioni URL deve ignorare. Tuttavia, deve fare attenzione a non aggiungere URL errati che potrebbero danneggiare il suo sito.
Per farlo, clicchi su Crawl nello strumento e clicchi su “Configura impostazioni URL”. Il pulsante “Configura impostazioni URL” le consente di inserire le sue impostazioni.
Fonte: seerinteractive
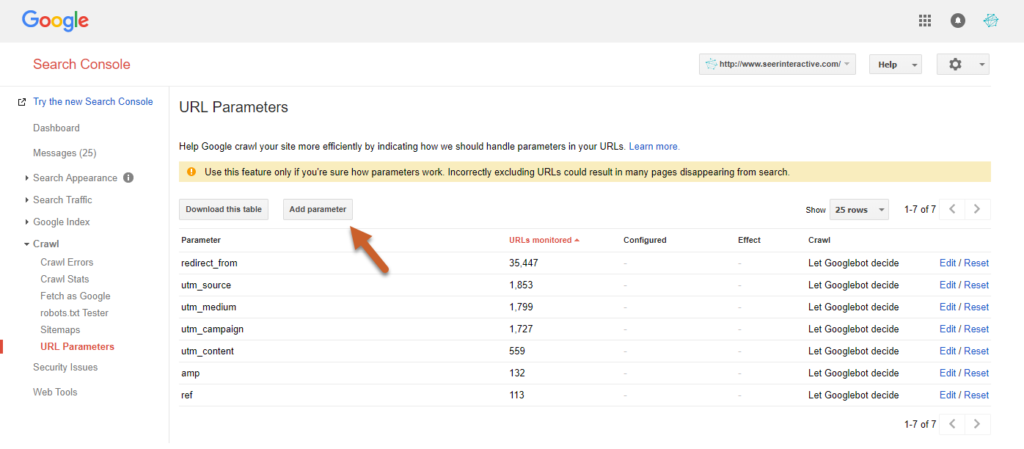
Fonte: seerinteractive
Per salvare l’impostazione, selezioni se questa modifica o meno il modo in cui il contenuto sarà visualizzato dagli utenti
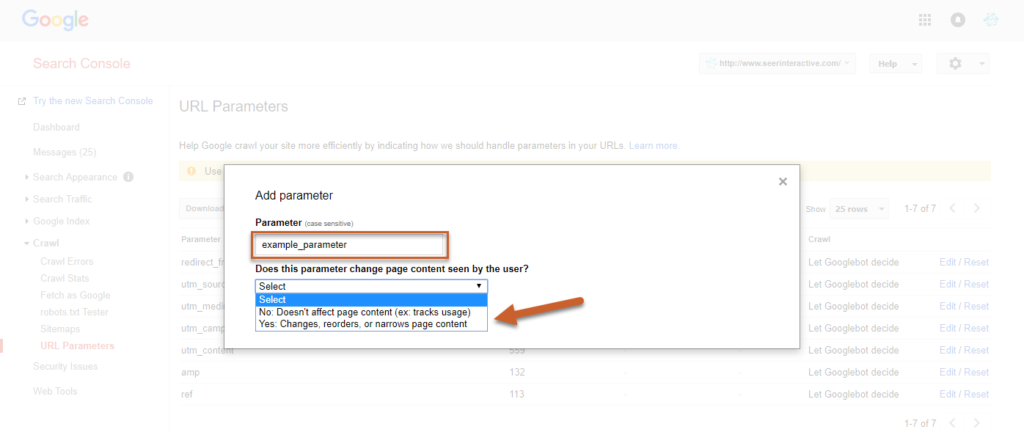
Fonte: seerinteractive
A questo punto, scelga SÌ per definire come il parametro può influenzare il contenuto.
2.2.4.3. Dichiarare gli URL passivi
La gestione dei parametri URL le consente anche di impostare determinati URL come passivi, in modo che i Googlebot li ignorino durante il crawling di un sito.
Questa è probabilmente la tecnica più efficace per eliminare gli URL ingombranti dai risultati di ricerca.
Si consiglia di applicare questa tecnica temporaneamente, mentre il suo team può aggiungere i tag canonici e impostare il reindirizzamento 301 per i duplicati.
Per dichiarare passivi alcuni dei suoi URL, dovrà seguire la stessa procedura e cliccare su NO prima di salvare. Di conseguenza, non appariranno più nelle SERP. Tuttavia, questa tecnica non è priva di inconvenienti.

A differenza del tag canonico, l’URL principale che viene mantenuto dopo che i duplicati sono stati definiti nelle impostazioni di Google Search Console non beneficia di nessuno di questi ultimi in termini di SEO.
Tuttavia, i problemi non sorgono quando gli URL marcati passivamente sono nuovi o hanno una scarsa autorità di pagina. Le suggeriamo pertanto di verificare l’autorità delle pagine che desidera aggiungere nelle impostazioni.
Per farlo, può utilizzare ad esempio lo strumento di verifica di Ahrefs. Quando l’autorità di una pagina è elevata, non deve contrassegnare il suo URL come passivo, altrimenti perderà preziosi vantaggi SEO.
Capitolo 3: Altre domande frequenti su DUST
Questo capitolo è dedicato alle domande che vengono spesso poste sugli URL di DUST.
3.1) Come posso evitare gli URL duplicati?
Anche se ci sono URL DUST che sono inevitabili in alcuni casi, molti dei duplicati possono essere evitati. I webmaster dovrebbero sempre utilizzare un formato URL coerente per tutti i link interni dei loro domini.
Ad esempio, un webmaster dovrebbe definire la versione canonica del suo sito web e assicurarsi che tutti coloro che aggiungono link interni al suo sito web seguano questo formato.
Quando la versione canonica del sito in questione è www.example.com/, tutti i link interni devono andare ahttp://www.example.com/ anziché ahttp://example.com/. La differenza fondamentale è la presenza di (www) nella versione canonica del sito.
3.2. Tutte le strategie di cui sopra possono essere utilizzate contemporaneamente per DUST?
In realtà, non esiste un’unica soluzione per gestire gli URL duplicati. Le soluzioni sopra menzionate hanno i loro vantaggi e svantaggi. Ad esempio, il reindirizzamento 301 può ridurre l’efficienza del crawling.
Lo stesso principio vale per il tag canonico. Infatti, i robot esplorano comunque gli URL duplicati per identificare l’URL canonico e indicizzarlo. Per quanto riguarda i meta robot, non trasmettono l’autorità degli URL duplicati all’URL originale.

Per quanto riguarda la dichiarazione di URL passivi nelle impostazioni di Google Search Console, questo è specifico di Google e non riguarda altri motori di ricerca.
Pertanto, il problema persiste su altri motori di ricerca come Bing, se non è più il caso di Google.
Alla luce di ciò, è ragionevole cercare di utilizzare tutte queste soluzioni in modo appropriato per coprire tutti i potenziali problemi. Tuttavia, è necessario analizzare ciascuna di queste soluzioni per determinare quali soddisfano meglio le sue esigenze.
3.3. Che cos’è un URL dinamico
L’uso di URL dinamici è una delle cause principali di DUST. In generale, l’URL dinamico viene generato da un database quando un utente invia una query di ricerca.

Il contenuto della pagina non cambia quando un utente vuole scegliere un colore di un articolo in un negozio online, ad esempio. Gli URL dinamici contengono spesso caratteri come: ?, &, %, +, =, $.
Al contrario, gli URL statici non cambiano e non contengono parametri URL. Questi URL non causano problemi durante l’esplorazione di un sito, come invece accade con gli URL dinamici.
3.4. Qual è il parametro URL?
I parametri URL sono una delle cause degli URL duplicati. Chiamati anche variabili URL, i parametri URL sono le variabili che vengono dopo il punto interrogativo in un URL.
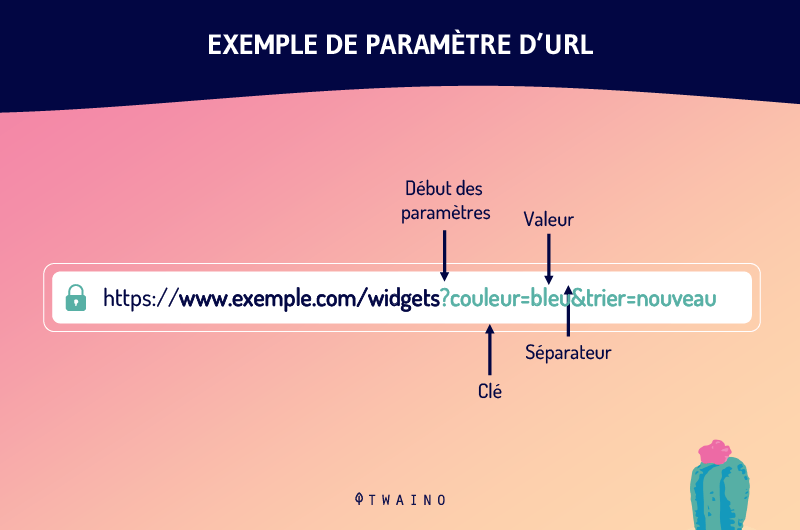
Sono le informazioni che definiscono le diverse caratteristiche e classificazioni di un prodotto o servizio. Possono anche determinare l’ordine in cui le informazioni vengono visualizzate da uno spettatore.
I casi d’uso più comuni per i parametri URL includono
- Filtraggio – Ad esempio, ? tipo=taglia, colore=reg o ? fascia di prezzo=25-40
- Identificare – ? prodotto=big-reg, categoryid=124 o itemid=24AU
- Tradurre – Ad esempio, ? lang=fr, ? language=de.
3.5. Qual è l’ID della sessione
I siti web spesso vogliono tenere traccia dell’attività degli utenti, in modo che possano aggiungere prodotti al carrello della spesa, ad esempio. Il modo per farlo è assegnare a ciascun visitatore un ID di sessione.
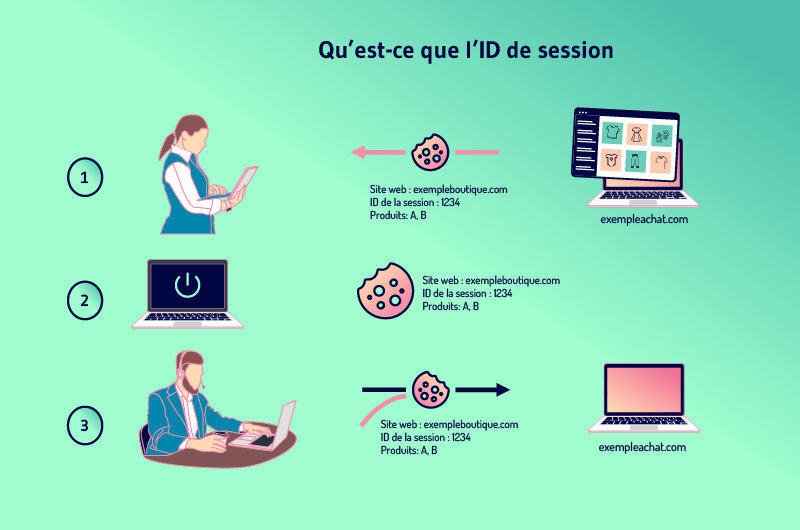
La sessione non è altro che la cronologia di ciò che un utente fa su un sito e l’ID è specifico per ogni visitatore. Per mantenere la sessione quando un visitatore lascia una pagina per un’altra, i siti web devono memorizzare l’ID da qualche parte.
Per fare questo, i siti di solito utilizzano dei cookie che memorizzano l’ID sul computer del visitatore.
Ma quando un visitatore ha precedentemente disabilitato la memorizzazione dei cookie, l’ID di sessione può essere trasferito dal server al browser come parametro allegato all’URL della pagina.
Ciò significa che tutti i link interni del sito hanno l’ID di sessione aggiunto al loro URL. Vengono quindi creati nuovi URL man mano che il visitatore visita altre pagine. Questi nuovi URL sono duplicati dell’URL principale e quindi creano il problema DUST.
3.6. Google penalizza gli URL duplicati?
Google non penalizza i contenuti duplicati o gli URL duplicati, e i dipendenti di Google lo sottolineano continuamente. John Muller, ad esempio, ha dichiarato:
“Non abbiamouna penalizzazione per i contenuti duplicati. Non declassiamo un sito per la presenza di contenuti duplicati.“
Tuttavia, Google sta lavorando per scoraggiare la duplicazione che deriva dalla manipolazione e sta apportando modifiche alle sue classifiche.
Sebbene si possa pensare che le penalizzazioni non riguardino implicitamente gli URL DUST, esse influiscono sulla SEO di un sito web, come discusso in precedenza
Conclusione
Tutto sommato, DUST è un problema comune a molti siti web. Si tratta di un insieme di URL che danno accesso alla stessa pagina su un dominio.
Nella maggior parte dei casi, la POLVERE non causa grossi problemi alla SEO di un sito. Tuttavia, gli errori tecnici che portano alla duplicazione di migliaia di URL di pagine prosciugano il budget di crawl di un sito e possono influire sui suoi sforzi SEO.
Fortunatamente, questi problemi possono essere evitati e la duplicazione degli URL può essere corretta:
- 301 reindirizzamento;
- Impostazione dei meta-robot;
- Il tag rel=canonical
- La definizione degli URL passivi nelle impostazioni di Google Searche Console.
La correzione degli URL di DUST può richiedere molto tempo e una pianificazione accurata. Si consiglia pertanto ai webmaster di evitare il più possibile le situazioni di URL duplicati.
E ora ci dica quali dei modi menzionati in questo articolo l’hanno già aiutata a correggere gli URL duplicati.

