
Probabilmente sa già che Google modifica costantemente il suo algoritmo di ranking per offrire agli utenti i migliori risultati possibili.
Il 7 agosto 2023, il motore di ricerca ha annunciato la ricerca di un nuovo framework di ranking chiamato Term Weighting BERT (TW-BERT), progettato per migliorare i risultati di ricerca.
In questo articolo, scopriamo cos’è il TW-BERT e come potrebbe aiutare Google a migliorare i suoi risultati di ricerca.
L’annuncio di Google del framework di ricerca TW-BERT
Google ha sviluppato un documento di ricerca che introduce un’affascinante struttura nota come TW-BERT. La sua funzione principale è quella di migliorare le classifiche di ricerca senza subire modifiche sostanziali.
TW-BERT è presentato come un contesto di ponderazione dei termini di query che combina due paradigmi per migliorare i risultati di ricerca.
Si armonizza con i modelli di espansione delle query esistenti, aumentandone l’efficacia. Inoltre, la sua introduzione in un nuovo quadro richiede solo modifiche minime.
Term Weighting BERT (TW-BERT) è un’impressionante struttura di ranking che Google ha rivelato. Ottimizza i risultati di ricerca e può essere facilmente integrato nei sistemi di ranking esistenti.
Sebbene Google non abbia confermato lo sfruttamento di TW-BERT, questo nuovo framework rappresenta un’importante svolta che migliorerà i processi di ranking in diverse aree, tra cui l’espansione delle query.
Tra i collaboratori di rilievo di TW-BERT c’è Marc Najork, ricercatore di punta di Google DeepMind ed ex Direttore Senior di Search Engineering presso Google Research.
TW-BERT – Di cosa stiamo parlando?
TW-BERT è un contesto di ranking che attribuisce punteggi, noti anche come pesi, alle parole contenute in una query di ricerca. L’obiettivo è quello di determinare con maggiore precisione quali pagine specifiche sono rilevanti per quella determinata query.
Per quanto riguarda l’espansione della query, TW-BERT è molto utile. L’espansione è un processo che riformula una query di ricerca o vi aggiunge delle parole(ad esempio, aggiungendo la parola “casa” alla ricerca “esercizio di bodybuilding“), al fine di abbinare meglio la query di ricerca ai documenti.
Il documento di ricerca parla di due diversi metodi di ricerca: uno basato sulle statistiche e un altro basato su modelli di apprendimento profondo.
Secondo i ricercatori,
“Questi metodi di reperimento basati sulle statistiche consentono una ricerca efficiente che si adatta alle dimensioni del corpus e si generalizza a nuovi domini. Tuttavia, i termini sono ponderati in modo indipendente e non tengono conto del contesto della query nel suo complesso.
Per questo problema, i modelli di apprendimento profondo possono eseguire questa contestualizzazione sulla query per fornire rappresentazioni migliori per i singoli termini“
Per illustrare la ponderazione dei termini di ricerca tramite TW-BERT, i ricercatori prendono l’esempio della query “Scarpe da corsa Nike”. Ad ogni termine di questa query viene assegnato un punteggio, o ‘ponderazione’, che consente di comprendere la query così come è stata inviata dall’utente.
In questa illustrazione, la parola “Nike” è considerata importante. Naturalmente, questa parola riceverà un punteggio più alto. I ricercatori concludono sottolineando l’importanza di garantire che la parola “Nike” riceva una ponderazione sufficiente durante la visualizzazione delle scarpe da corsa nei risultati finali.
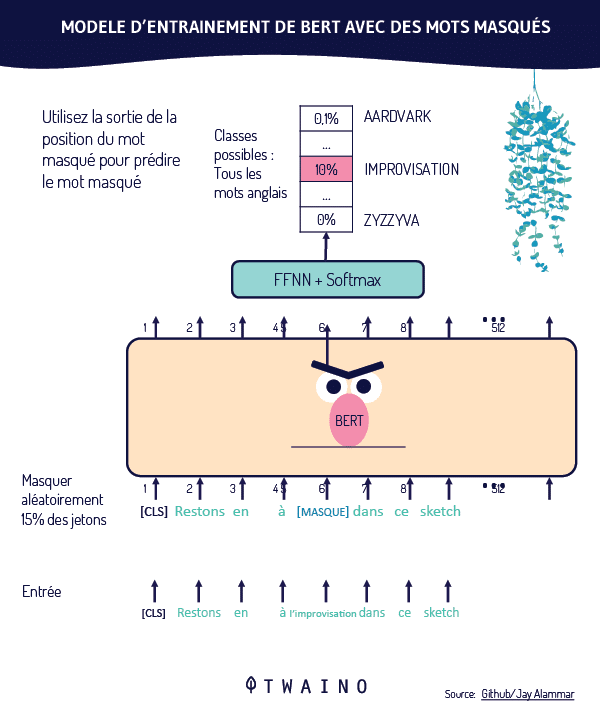
L’altra sfida è capire il legame tra le parole “corsa” e “scarpe”. Ciò significa che la ponderazione dovrebbe essere aumentata quando le due parole sono combinate per formare l’espressione “scarpe da corsa”, piuttosto che ponderare ogni parola separatamente.
Il TW-BERT: la soluzione per i limiti dei quadri attuali
Il documento di ricerca discute i limiti intrinseci della ponderazione attuale quando si tratta di variabilità delle query, e sottolinea che i metodi di ponderazione basati sulla statistica hanno prestazioni inferiori nelle situazioni di ‘apprendimento da zero’.
L’apprendimento da zero si riferisce alla capacità di un modello di risolvere un problema per il quale non è stato addestrato.
I ricercatori hanno anche presentato una sintesi dei limiti intrinseci degli attuali metodi di espansione dei termini.
L’espansione dei termini si riferisce all’uso di sinonimi per trovare più risposte alle query di ricerca o quando si deduce un’altra parola.
Ad esempio, quando qualcuno cerca “zuppa di pollo”, questo implica “ricetta della zuppa di pollo”.
I ricercatori descrivono le carenze degli approcci attuali nei seguenti termini:
“… queste funzioni di punteggio ausiliarie non tengono conto delle fasi di ponderazione aggiuntive implementate dalle funzioni di punteggio utilizzate negli estrattori esistenti, come le statistiche delle query, le statistiche dei documenti e i valori degli iperparametri.
Questo può alterare la distribuzione originale dei pesi assegnati ai termini durante la valutazione finale e il recupero“.
Successivamente, i ricercatori sostengono che l’apprendimento profondo ha le sue sfide sotto forma di complessità di implementazione e di comportamento imprevedibile quando incontra nuovi domini per i quali non è stato pre-addestrato.
È qui che entra in gioco TW-BERT.
Cosa c’è nel TW-BERT?
La soluzione proposta assomiglia a un approccio ibrido.
I ricercatori scrivono:
“Per colmare questo divario, sfruttiamo la robustezza degli estrattori lessicali esistenti con le rappresentazioni contestuali del testo fornite dai modelli profondi.
Gli estrattori lessicali assegnano già dei pesi ai termini n-grammi della query durante la ricerca.
In questa fase della pipeline, sfruttiamo un modello linguistico per assegnare pesi appropriati ai termini n-grammi della query.
Questo metodo di ponderazione dei termini BERT (TW-BERT) è ottimizzato globalmente utilizzando le stesse funzioni di punteggio impiegate nella pipeline per garantire la coerenza tra la formazione e il recupero.
Questo migliora la ricerca quando si utilizzano i pesi dei termini prodotti da un modello TW-BERT, pur mantenendo un’infrastruttura di recupero delle informazioni simile alla sua controparte di produzione esistente“
L’algoritmo TW-BERT assegna dei pesi alle query per fornire un punteggio di pertinenza più accurato, sul quale il resto del processo di classificazione può poi lavorare.
Come si presenta il sistema di ricerca lessicale standard
Questo diagramma illustra il flusso di dati in un sistema di ricerca lessicale standard.
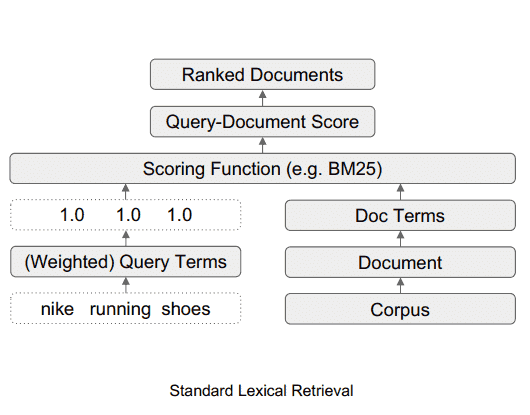
Fonte: searchenginejournal
Come si presenta il sistema di ricerca TW-BERT
Questo diagramma mostra come lo strumento TW-BERT si inserisce in un quadro di ricerca.
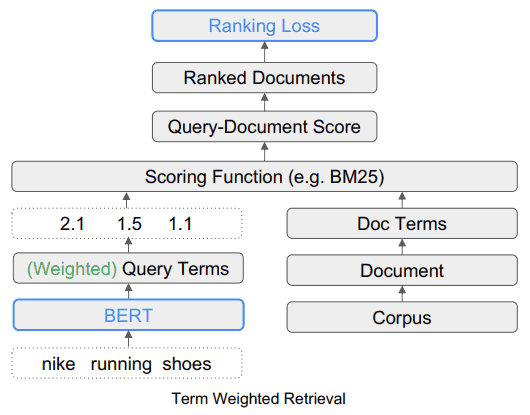
Fonte: searchenginejournal
La facilità di implementazione di TW-BERT
Uno dei vantaggi di TW-BERT è che può essere facilmente introdotto nell’attuale processo di classificazione della ricerca di informazioni, come componente plug-and-play.
“Questo ci permette di implementare i nostri pesi dei termini direttamente in un sistema di recupero delle informazioni durante la ricerca.
Questo si differenzia dai metodi di ponderazione precedenti che richiedono una messa a punto aggiuntiva dei parametri di un estrattore per ottenere prestazioni di estrazione ottimali, in quanto ottimizzano i pesi dei termini ottenuti con l’euristica piuttosto che con l’ottimizzazione end-to-end“.
Un fattore chiave della facilità di implementazione di TW-BERT è che non richiede l’uso di software specialistici o aggiornamenti hardware. Questa capacità rende semplice l’integrazione di TW-BERT in un sistema di algoritmi di ranking.
Google ha già aggiunto TW-BERT al suo algoritmo di ranking?
In termini di applicabilità all’algoritmo di ranking di Google, la facilità di integrazione di TW-BERT suggerisce che Google potrebbe aver adottato questo meccanismo nella struttura del suo algoritmo.
Il framework potrebbe essere integrato nel sistema di ranking dell’algoritmo senza richiedere un aggiornamento completo dell’algoritmo di base.
D’altra parte, alcuni algoritmi poco efficaci o che non offrono alcun miglioramento, sebbene intriganti nel loro design, potrebbero non essere mantenuti per l’algoritmo di ranking di Google. D’altra parte, algoritmi particolarmente efficaci, come TW-BERT, stanno attirando l’attenzione.
TW-BERT ha dimostrato di essere molto efficace nel migliorare le capacità degli attuali sistemi di ranking, rendendolo un candidato valido per l’adattamento da parte di Google.
Se Google ha già implementato TW-BERT, questo potrebbe spiegare le fluttuazioni di ranking segnalate dagli strumenti di monitoraggio SEO e dalla comunità del search marketing nell’ultimo mese.
Mentre Google rende pubblico solo un numero limitato di modifiche al ranking, quelle che hanno un impatto significativo, non c’è ancora una conferma ufficiale che Google abbia integrato TW-BERT.
Possiamo solo ipotizzare la sua probabilità in base ai miglioramenti significativi apportati all’accuratezza del sistema di ricerca delle informazioni e alla praticità del suo utilizzo.
Per riassumere
TW-BERT è un’innovazione importante nel campo della referenziazione naturale, che potrebbe cambiare il modo in cui Google analizza e classifica le pagine web. TW-BERT non è ancora stato integrato ufficialmente nell’algoritmo di Google, ma potrebbe esserlo nel prossimo futuro.

