Agence SEO >> Outils SEO >>
Crawler | Deep Crawl
Agence SEO >> Outils SEO >>
DeepCrawl est un robot d’exploration qui parcourt votre site web pour révéler les performances techniques optimales afin de vous aider à améliorer son indexabilité et son expérience utilisateur pour des fins de référencement naturel.

Si vous avez besoin d’examiner la santé technique de votre site web, Deepcrawl est un explorateur qui vous permet de voir comment les moteurs de recherche explorent votre site.
L’outil fournit un large éventail d’informations sur chaque page de votre site web pour vous donner une idée claire de sa probabilité d’indexabilité.
Découvrons dans cette description comment Deepcraw fonctionne.
L’outil fonctionne en soustrayant des données de différentes sources comme les sitemaps XML, la search console, ou Google analytics.
Ainsi, il vous donne la possibilité de lier jusqu’à 5 sources pour rendre l’analyse de vos pages pertinemment efficace.
L’objectif est de simplifier la détection des failles dans l’architecture de votre site en fournissant des données telles que les pages orphelines générant du trafic.
L’outil vous permet d’avoir une vue claire de la santé technique de votre site web et des informations exploitables que vous pouvez utiliser pour améliorer la visibilité SEO et convertir le trafic organique en revenus.
La configuration d’un site web pour l’exploration peut se faire en quatre étapes simples.
Lorsque vous vous inscrivez pour un essai gratuit de Deep Crawl , vous êtes redirigé vers le tableau de bord du projet. La deuxième étape consiste à choisir les sources de données pour l’ exploration.
En suivant suivant les instructions, vous pouvez rapidement configurer votre site web et passez aux choses les plus importantes :
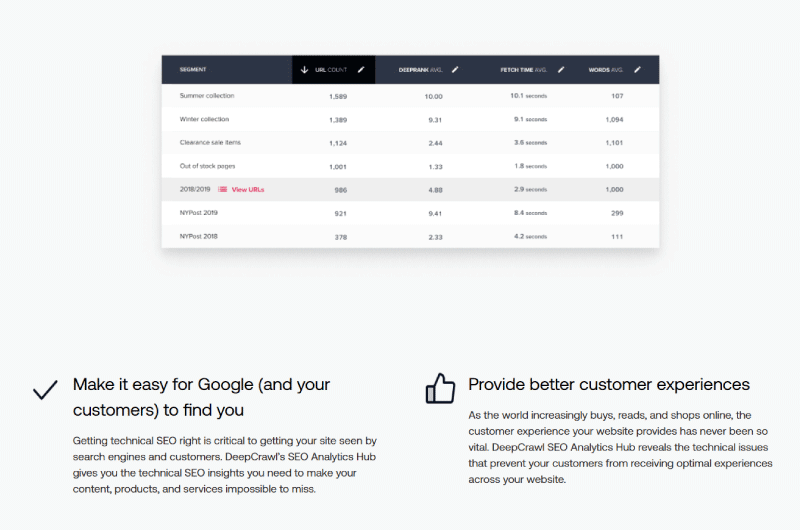
Lorsque Deep Crawl finit d’explorer l’ensemble d’un site web, il affiche dans un tableau de bord assez intuitif une vue globale et précise de tous les fichiers journaux repérés.
Dans un premier graphique, on peut lire une ventilation complète et rapide de l’ensemble des demandes effectuées par les utilisateurs d’appareils mobiles comme ordinateurs.
Il en suit un résumé qui met non seulement en évidence les principaux problèmes liés à l’exploration du site web, mais aussi une liste de tous les éléments qui peuvent, d’une manière ou d’une autre, empêcher l’indexation des pages du site web.
Deep Crawl soustrait et analyse toutes les données utiles de toutes les sources que vous avez liées lors de la configuration et les combine avec les données issues des fichiers journaux pour mieux qualifier chaque problème détecté.
On observe de ce rapport que nombreuses sont les Url répertoriées dans les sitemap XML qui n’ont pas été demandées.
Et cela peut être dû à une faible liaison des pages entre elles ou une profondeur assez importante de l’architecture du site au point où il faut un robot plus performant pour atteindre les pages web du fond.
De plus, lorsque le sitemaps XML est obsolète, il ne reflète plus en aucun cas les Urle actives.
Dans ce cas, on peut déduire qu’un budget de crawl s’avère très important surtout si vous avez un grand site web.
La section d’analyse approfondie se caractérise par deux ensembles de données qui sont ‘’Bot Hits’’ et ‘’Issues’’.
Le premier ensemble de données appelé ‘’Bot Hits’’ répertorie l’ensemble des URL demandées en tenant non seulement compte du nombre total de requêtes, mais aussi des appareils utilisés pour effectuer les demandes.
L’idée est de vous aider à voir les pages sur lesquelles les robots se focalisent le plus lorsqu’ils explorent votre site web et les zones de déficience comme les pages potentiellement obsolètes ou encore les pages orphelines.
Il existe également une option de filtre qui vous permet de repérer toutes les Urls qui sont probablement affectées par les problèmes des quelques-unes.
Par ailleurs, l’onglet ‘’Isues’’ montre tout problème affectant votre domaine avec tous les détails d’erreurs en se basant sur les données du fichier journal.
Il s’agit essentiellement de :
Cette section fournit une vue de l’ensemble des URL trouvées dans le fichier journal lors de l’exploration, mais qui renvoient un code de réponse de serveur 4XX ou 5XX.
Il s’agit des Url qui peuvent causer d’énormes problèmes au site web et nécessitent une réparation urgente.
Cette section met en évidence les URL explorables par les moteurs de recherche, mais sont définies sur noindex et qui contiennent une référence canonique à une URL alternative ou carrément sont bloquées dans robots.txt par exemple.
Ce rapport affiche les URL en tenant compte du nombre d’URL accessibles dans les fichiers journaux.
En réalité, toutes les URL ici ne sont pas nécessairement mauvaises, mais c’est un excellent moyen de mettre en évidence le budget de crawl réellement affecté à des pages spécifiques, ce qui vous permet de faire une répartition équitable si nécessaire.
Lorsque vous bloquez l’indexation de certaines URL de votre site dans un fichier robots.txt, cela ne signifie pas qu’il n’y aura aucune demande dans le fichier journal.
Cette section vous permet d’identifier les URL de votre site web qui peuvent être indexées malgré qu’elles sont bloquées dans un fichier robots.txt.
Cela vous permet également de voir les éléments qui manquent à certaines pages pour qu’elles ne soient pas indexées par les robots des moteurs de recherche comme vous l’auriez souhaité, par exemple les pages sans l’attribut noindex.
Ici, vous pouvez voir toutes les URL de votre site web qui peuvent facilement être indexées par les moteurs de recherche.
La particularité de cette fonctionnalité est qu’elle vous montre aussi une liste d’URL qui n’ont généré aucune requête des moteurs de recherche dans les fichiers journaux fournis.
Dans la plupart des cas, il s’agit des pages orphelines, c’est-à-dire celles qui ont peu de liens avec les autres pages du site web.
Ces deux rapports vous permettent de voir si vos pages s’affichent correctement sur les appareils pour lesquels vous les avez définies.
Cette vue est particulièrement utile pour les sites utilisant une version mobile autonome ou pour les sites réactifs et adaptatifs. C’est aussi un meilleur moyen de voir les URL moins demandées, probablement anciennes ou non pertinentes.
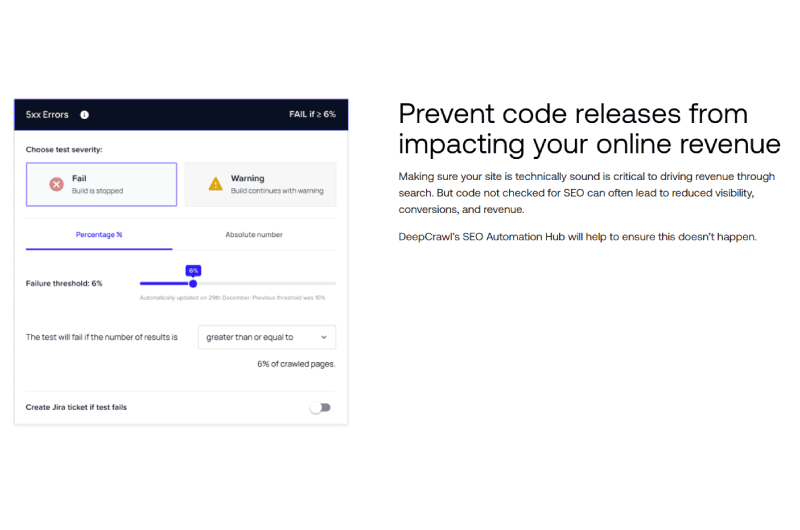
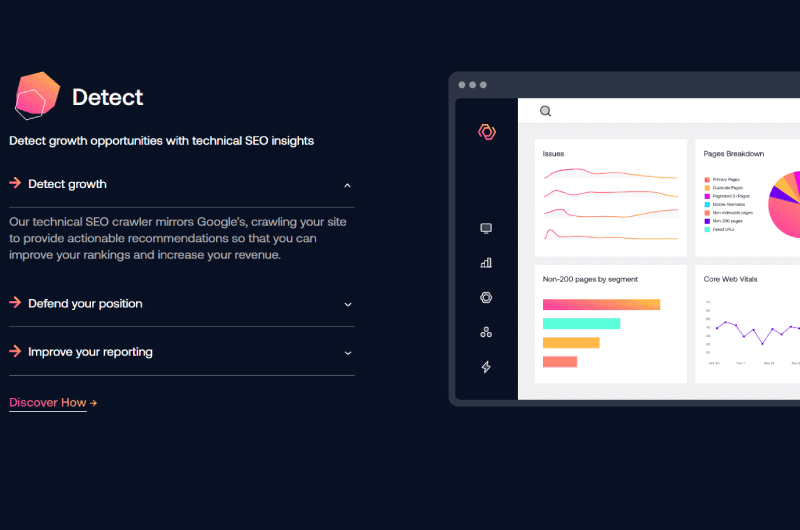
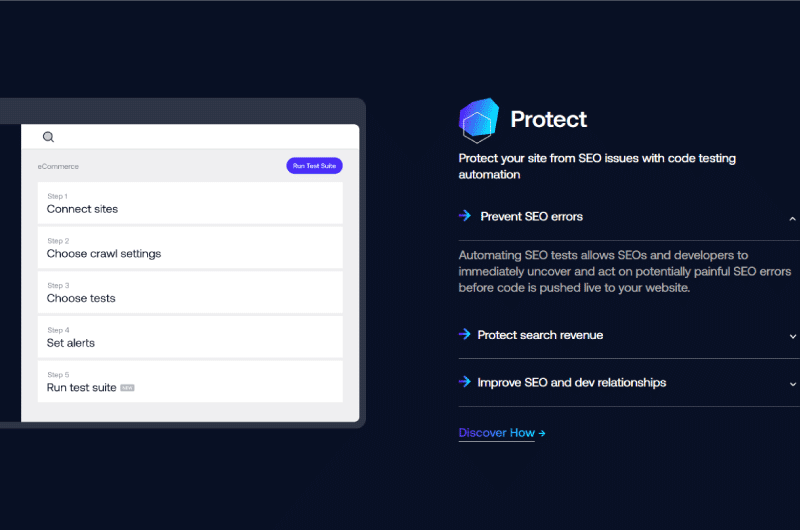


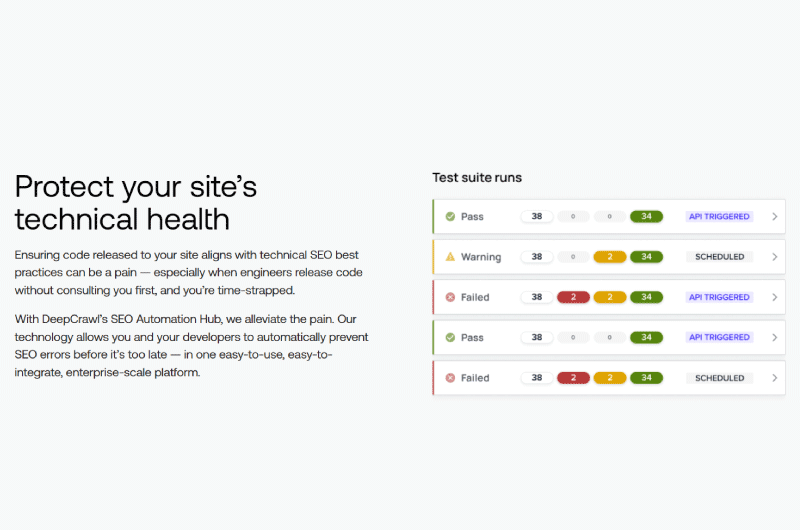
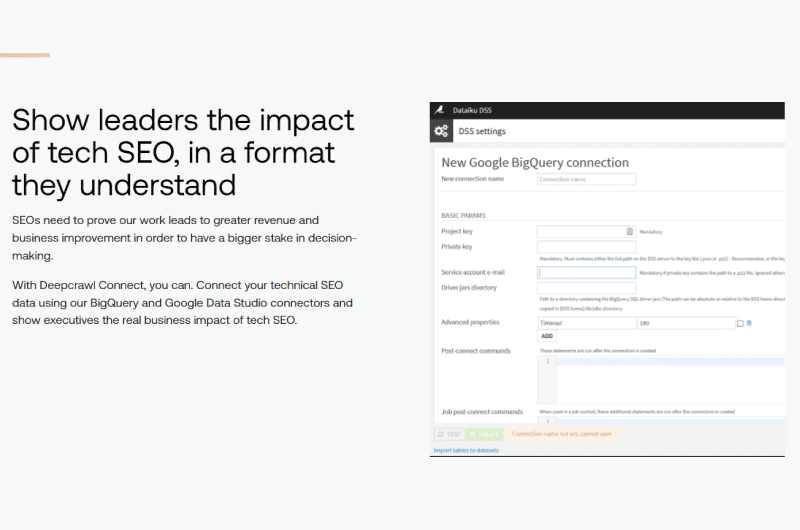
Deep Crawl est une plateforme de référencement technique qui permet de détecter des opportunités de croissance pour les sites.
Elle aide ainsi les grandes marques et entreprises à exploiter pleinement leur potentiel de revenus, tout en protégeant leurs sites contre certaines erreurs de code.
Deep Crawl apparaît comme étant un centre de commande pour le référencement technique et pour la santé des sites web. La plateforme utilise un robot d’exploration assez puissant qui analyse les données des sites.
En dehors du référencement technique, Deep Crawl effectue aussi des opérations d’automatisation dans le but de protéger les sites des menaces.
Deep Crawl dispose d’une équipe de professionnels du numérique dirigée par Craig Durham.
Elle est utilisée par de nombreuses entreprises, parmi lesquelles des marques mondialement reconnues telles qu’Adobe, eBay, Microsoft, Twitch, etc.
 Alexandre MAROTEL
Alexandre MAROTEL