
DUST, ou URLs diferentes com texto semelhante, ocorre quando várias URLs em um link de um site para uma página no mesmo site. Muitas vezes esse é um conteúdo que pode ser acessado de diferentes lugares no mesmo domínio ou por diferentes meios. Também conhecido como URLs duplicadas, DUST confunde os mecanismos de busca quando os rastejadores precisam rastejar e indexar URLs duplicadas. O PÓ reduz a eficiência do rastejamento e dilui a autoridade da página principal.
A criação de conteúdo é a principal responsabilidade dos webmasters quando se trata de classificar um website. Embora o ideal seja criar um conteúdo único, é difícil fazer isso sem contar os raspadores de conteúdo que duplicarão o seu.
O conteúdo duplicado é responsável por 25-30% do conteúdo da rede e nem todo ele é resultado de intenções desonestas. Ela também pode ser criada involuntariamente em um site sem que os webmasters se dêem conta disso.
Esse é o caso de URLs diferentes com texto semelhante (DUST), onde uma URL pode ser duplicada centenas de vezes. A grande maioria dos websites se depara com esse problema e suas causas são numerosas.
Mas em termos concretos;
- O que é PÓ?
- Como é que os URLs do PÓS aparecem em um site?
- Quais são os problemas potenciais com o PÓ?
- Como posso corrigir os problemas relacionados com o PÓ?
Neste artigo, vou dar respostas explícitas a essas perguntas para desmistificar o PÓ. Descobriremos também como evitar que esse problema ocorra em um local.
Portanto, sigam!
Capítulo 1: O que é o PÓ e que problemas ele causa em termos de SEO?
Conteúdo duplicado é um dos 5 maiores problemas de SEO que os sites enfrentam e DUST é apenas uma forma de conteúdo duplicado.
Este capítulo discute a definição de DUST e os problemas de SEO que podem causar um site.
1.1. PÓ: O que é isso?
O conteúdo duplicado é comum na web e o Google o define como conteúdo do mesmo site ou de outros sites que correspondem a outro conteúdo ou são quase semelhantes.
Através dessa definição, podemos ver que o conteúdo duplicado ocorre em dois níveis: no mesmo domínio ou entre vários domínios.

Quando ocorre no mesmo site, pode tomar a forma de conteúdo que aparece em páginas diferentes de um domínio ou uma página que é acessível em várias URLs.
No último caso, o conteúdo duplicado é chamado de DUST. Enquanto outras formas de conteúdo duplicado estão relacionadas com a criação de conteúdo, DUST é mais um resultado da duplicação de URLs.

Essa duplicação de URLs é muito comum e muitas vezes é o resultado de um problema técnico que todos os websites podem enfrentar em algum momento. Os seguintes URLs apontam todos para o mesmo site e são um exemplo de DUST.
- www.votresite.com/ ;
- seu site.com ;
- http://votresite.com ;
- http://votresite.com/ ;
- https://www.votresite.com;
- https://votresite.com.
Embora esses URLs pareçam ser os mesmos e tenham como alvo a mesma página, as sintaxes não são as mesmas e isso pode causar problemas para um website
1.2. Por que o PÓ ou a URL duplicada é um problema?
Ao contrário de outras formas de conteúdo duplicado, o PÓ não prejudica diretamente a SEO de um website. Na verdade, o Google entende perfeitamente que essa duplicação não é maliciosa.

No entanto, o DUST apresenta três problemas principais com os motores de busca. Os motores de busca são incapazes de :
- Identificar quais URLs devem ser incluídas ou excluídas de seu índice;
- Conhecer o URL para o qual atribuir métricas de link como confiança, autoridade, justiça..
- Identificar quais URLs eles devem classificar para os resultados da busca.
Para entender essas questões, vejamos como funcionam os motores de busca. Eles conseguem exibir os resultados das buscas através de três funções principais:
- Rastejando ;
- Indexação;
- Ranking.

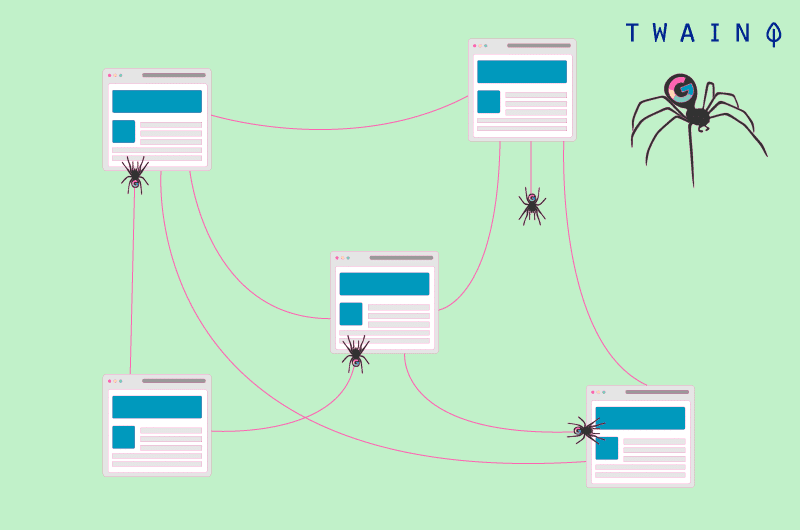
Web crawling é o processo pelo qual os motores de busca descobrem conteúdos novos e recentemente atualizados na web. Eles enviam robôs chamados spiders que se movem de URL para URL em um site.
Quando várias URLs levam à mesma página, as aranhas as consideram como URLs diferentes e rastejam cada uma delas. Descobrem então que o conteúdo dessas diferentes URLs é o mesmo e as tratam como conteúdo duplicado.
No decorrer do rastejamento, os bots podem acrescentar ao índice os novos recursos interessantes que encontram, uma enorme base de dados de URLs.
Embora isso possa acontecer, as aranhas evitam indexar a mesma página várias vezes e se concentram em indexar apenas aquelas páginas que oferecem conteúdo único. Assim, as aranhas podem ter que fazer escolhas sobre quais URLs devem ser indexadas.

Eles podem incluir no índice qualquer URL que possa não ser a URL correta ou aquela que o senhor queira indexar.
Além disso, é a partir do conteúdo indexado que os motores de busca escolhem o conteúdo relevante quando um usuário faz uma consulta. É óbvio, portanto, que uma página que não existe no índice não pode aparecer nos resultados da busca.
1.como pode o DUST prejudicar sua SEO?
URLs duplicadas podem prejudicar a SEO de várias maneiras.
1.3.1. Reduzir a eficiência do rastejamento
O fato de que as URLs duplicadas apontam todas para a mesma página e que os robôs ainda rastejarão cada um deles pode reduzir a eficiência do rastejamento dos robôs.
Isso porque o Google aloca um orçamento de rastejamento para todos os sites. Esse orçamento representa o número de URLs que os rastejadores podem seguir em um site. Quanto mais URLs, mais provável é que o orçamento de rastejamento se esgote.

No entanto, os rastejadores não poderão rastejar todas as páginas quando o orçamento estiver esgotado e talvez não possam rastejar todas as páginas relevantes do site.
É, portanto, crucial que os proprietários do site trabalhem para otimizar o orçamento para permitir que os rastejadores sigam todas as URLs relevantes.
1.3.2. Perda de tráfego e diluição do patrimônio líquido
Quando os motores de busca indexam uma URL com uma estrutura ímpar entre URLs duplicadas, os usuários podem ter dúvidas quando ela aparece nos resultados da busca. Isso pode levar a uma perda de tráfego, apesar de estar bem classificado.
Também pode acontecer que os robôs indexem várias URLs entre as duplicatas. Mesmo neste caso, os URLs são considerados de maneira diferente. Cada um deles recebe autoridades e classificações diferentes.

Isso dilui a visibilidade de todas as duplicatas. Isso porque cada uma das URLs duplicadas pode capturar backlinks, enquanto esses links podem todos apontar para a URL principal.
1.4. Como aparecem as URLs duplicadas?
Os webmasters não duplicam intencionalmente os URLs. O PÓ freqüentemente ocorre quando os sites usam um sistema que cria múltiplas versões da mesma página. Essa situação é comum em sites de comércio eletrônico, especialmente em fichas de produtos.
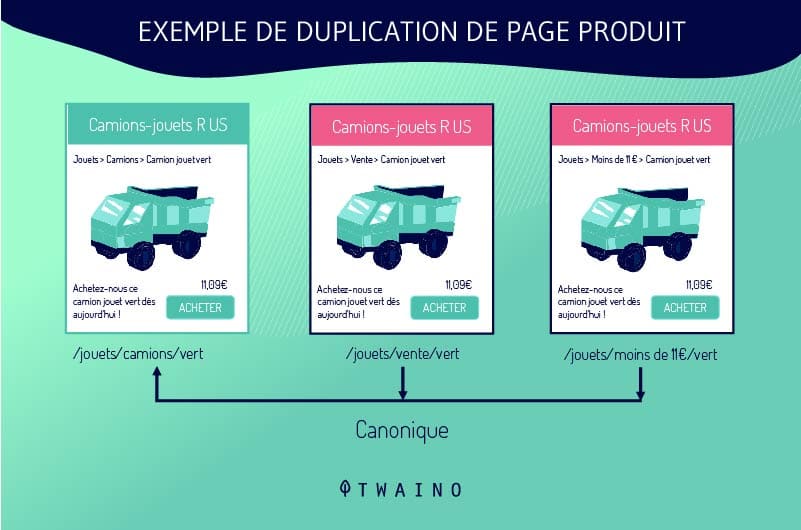
As fichas de produtos são configuradas de uma maneira que permite aos clientes escolher entre diferentes tamanhos ou cores enquanto permanecem na mesma página. O sistema de gestão de conteúdo, portanto, gera múltiplos URLs DUST que ligam a uma única página.
Por exemplo, se um site oferece uma camisa azul em três tamanhos diferentes, o sistema pode gerar os seguintes URLs:
- shoponline.com/blueshirt-A ;
- shoponline.com/blueshirt-B;
- shoponline.com/blueblueblouse-C.
As URLs duplicadas são também o resultado dos filtros que os sites oferecem para facilitar a busca por seus visitantes. Todas as diferentes combinações geram links DUST, que infelizmente os motores de busca vêem de maneira diferente.
Os sites também criam URLs duplicadas quando eles publicam uma versão para impressão de uma página. Da mesma forma, as URLs duplicadas também provêm:
- URLs dinâmicos;
- Versões antigas e esquecidas de uma página;
- Identificação das sessões.
Observe também que os URLs são sensíveis à presença ou ausência da barra (/) no final. Por exemplo, o Google tratará o site example.com/page/ e o site example.com/page de maneira diferente.
Assim, essas duas URLs serão tratadas como URLs duplicadas, mesmo que acessem o mesmo conteúdo.
Capítulo 2: Como identificar os URLs do PÓ e como corrigi-los
A correção de URLs de PÓ pode ter um efeito significativo sobre a SEO de um website. Neste capítulo, descobrimos como detectar esses URLs e as diferentes formas de tratamento que podem ser dadas a eles.
2.1. Como encontrar URLs duplicadas
É essencial detectar URLs de PÓ para corrigir esse problema. Felizmente, há dicas e ferramentas on-line que permitem ao senhor verificar a existência de URLs duplicadas em um domínio.
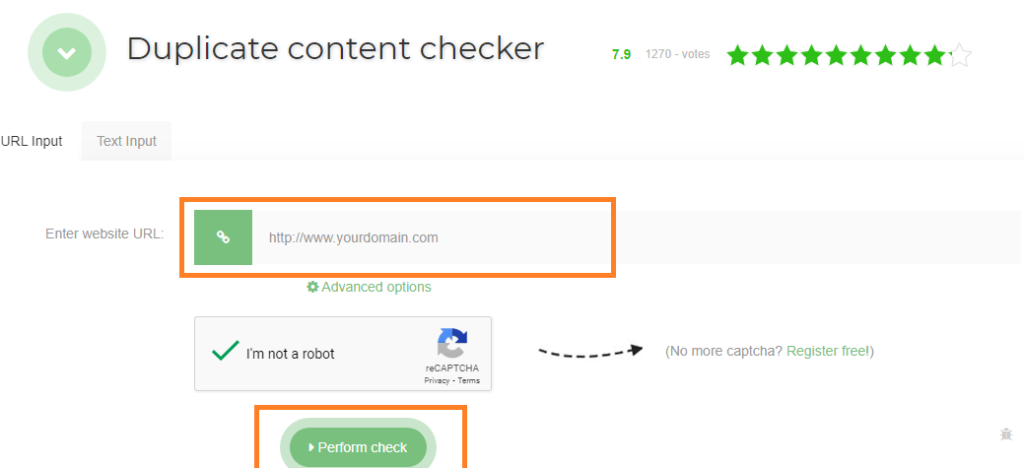
2.1.1. Ferramentas de verificação de URL duplicadas
Entre as ferramentas para a verificação de URLs duplicadas, sugiro as Ferramentas de Revisão Seo. Basta digitar o URL visado na barra reservada para esse fim e clicar em “Executar verificação”. A ferramenta lhe mostrará o número de duplicatas do URL que o senhor entrou.
Siteliner é também uma ferramenta poderosa para encontrar URLs duplicadas em um domínio. Ele examina seu domínio e mostra ao senhor um relatório de links duplicados em seu site.
Para usar essa ferramenta, basta entrar no seu domínio na barra de busca. Quando o Siteliner mostrar ao senhor a análise de seu site, clique em “conteúdo duplicado” para exibir as URLs duplicadas.
2.1.2. Usando o site do operador de busca: exemplo.com intitle :
O senhor também pode verificar a existência de URLs duplicadas em seu site usando o site dos operadores de busca : exemplo.com intitle: “sua palavra-chave“. O Google mostrará a você as URLs em seu domínio (exemplo.com) que contêm a palavra-chave visada.
Tudo o que o senhor tem que fazer é olhar os URLs que o Google lhe mostra para ver quais URLs se conectam com a mesma página. Agora que o senhor pode encontrar URLs duplicadas em seu site, passemos às medidas corretivas que o senhor pode tomar.
2.2 Como consertar os URLs do PÓ
2.2.1. 301 redirecionamento
301 O redirecionamento é uma maneira de enviar usuários e motores de busca para um endereço que é diferente do que eles estão solicitando permanentemente. No caso de URLs DUST, consiste em redirecionar as duplicatas para a URL original.
Dessa maneira, as diferentes URLs que provavelmente serão classificadas de maneira diferente são agrupadas em uma só e deixam de competir. Além disso, todos os URLs passam todo o seu equipamento para o URL principal.

Esse URL se beneficia assim do poder de referência de suas duplicatas. Isso naturalmente terá um impacto significativo sobre a referência da página em questão. Note-se, no entanto, que o 301 redirecionamento não remove a duplicata do PÓ.
2.2.2. A etiqueta rel=canônica
A etiqueta rel=canônica continua sendo uma das melhores maneiras de transferir o potencial de referência de uma página duplicada para outra página. É uma tag HTML que simplesmente diz aos motores de busca qual o URL a ser adicionado aos seus índices.

O Google define a URL canônica como a URL mais representativa de um grupo de conteúdo duplicado. Essa URL é a que os rastejadores seguirão regularmente a fim de otimizar o orçamento de rastejamento de um site. Os outros serão visitados com menos freqüência.
O Google e outros mecanismos de busca atribuem o potencial completo de SEO de URLs duplicadas à URL canônica. A etiqueta rel=canônica é acrescentada ao cabeçalho de uma página HTML.
Os motores de busca consideram as outras páginas como duplicatas da URL canônica e não as fazem desaparecer. Isso é muito vantajoso, sobretudo porque o senhor certamente não quer que todas as duplicatas sejam retiradas.
2.2.3. Uso de meta robôs
O uso de meta-robôs é simples e eficaz quando se trata de impedir que as páginas apareçam nos resultados das buscas. Consiste em acrescentar as tags Noindex e Nofollow ao código HTML de uma página.

A etiqueta Noindex diz aos motores de busca que o senhor não quer que eles adicionem uma URL aos seus índices e, portanto, não a mostrem nos resultados da busca.
O senhor simplesmente acrescenta a tag Noindex às URLs duplicadas para evitar que elas concorram com a URL principal.
A etiqueta Nofollow diz ao Google para não seguir um link e para não passar sua autoridade para as páginas para as quais faz link. Assim, as aranhas ignorarão todos os elos que incluem a etiqueta Nofollow.
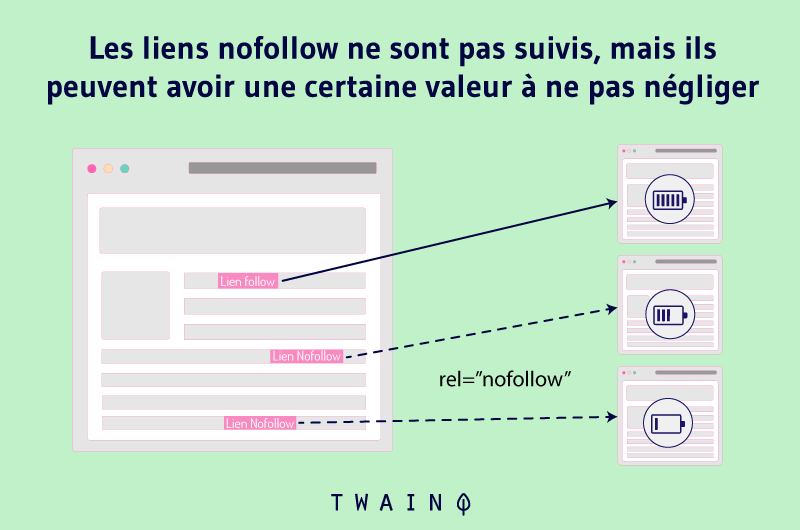
Acrescentar essa etiqueta aos URLs duplicados pode, portanto, ajudar o senhor a corrigir problemas relacionados com a duplicação de URLs.
2.2.4. Instalação no Console de Busca do Google
A inserção de etiquetas canônicas e de metas de bot em centenas de páginas de DUST é muitas vezes muito trabalho. Felizmente, as configurações do Console de Busca do Google podem ser parte da solução para os URLs DUST.
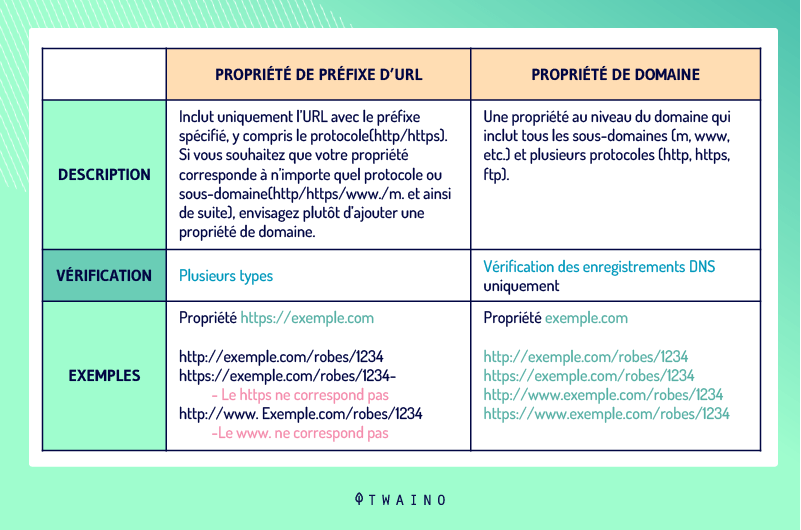
2.2.4.1. Definição da versão URL de seu site
A definição do endereço de um domínio também pode ajudar a resolver problemas de DUST. Os webmasters podem estabelecer uma preferência por seu domínio nessa ferramenta e especificar se os aranhas devem rastejar certas URLs.
Em vez dehttp://www.votresite.com, eles podem especificar quehttp://votresite.com é o endereço de seu domínio. Note a ausência de www e o mesmo se aplica aos protocolos HTTP e HTTPS com a ausência de S.
Para proceder com a definição da versão da URL de seu site, vá ao Console de Busca do Google e escolha “Adicionar Propriedade”
2.2.4.2. Administração dos parâmetros de URL
A configuração das definições de URL no Console de Busca do Google permite que o senhor especifique quais definições de URL deve ignorar. No entanto, o senhor deve ter cuidado para não acrescentar URLs incorretas que possam danificar seu site.
Para fazer isso, clique em Rastejar na ferramenta e clique em “Configurar Configurações de URL”. O botão “Configure URL Settings” permite que o senhor digite suas configurações.
Fonte: Seerinteractive
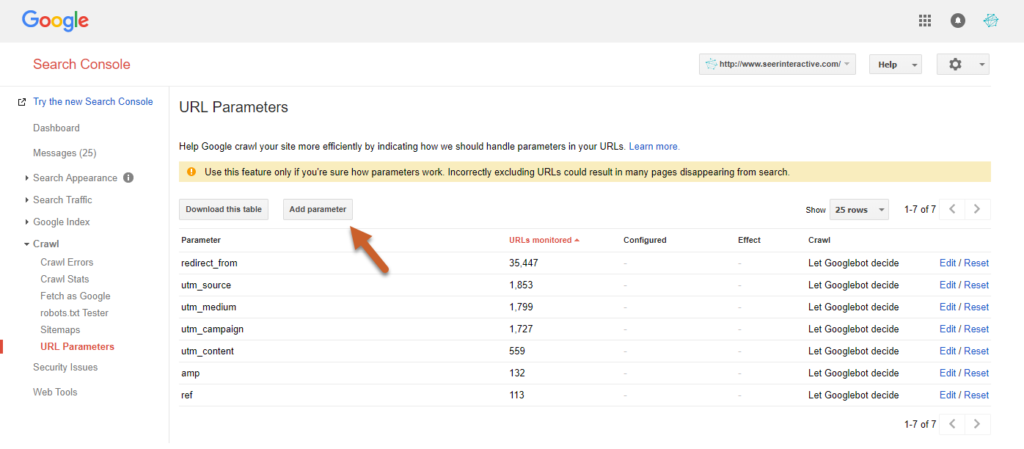
Fonte: Seerinteractive
A fim de salvar a configuração, selecione se a configuração muda ou não a maneira como o conteúdo será visto pelos usuários
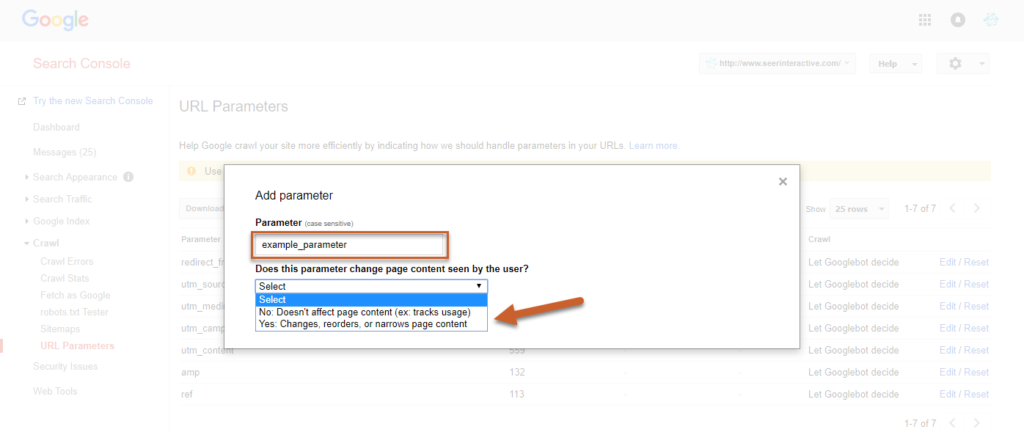
Fonte: Seerinteractive
Neste momento, escolha SIM para definir como o parâmetro pode afetar o conteúdo.
2.2.4.3. Declaração de URLs passivas
A administração de parâmetros de URL também permite ao senhor definir certos URLs como passivos para que os Googlebots os ignorem enquanto rastejam um site.
Esta é provavelmente a técnica mais eficaz para remover URLs desordenadas dos resultados das buscas.
Recomenda-se que o senhor aplique essa técnica temporariamente, enquanto sua equipe pode acrescentar etiquetas canônicas e estabelecer 301 redirecionamentos para duplicatas.
Para declarar alguns de seus URLs como passivos, o senhor só precisará seguir os mesmos passos e clicar em NÃO antes de salvar. Como resultado, eles não mais aparecerão nos SERPs. No entanto, essa técnica não deixa de ter seus inconvenientes.

Ao contrário da tag canônica, a URL principal que é mantida depois que as duplicatas foram definidas nas configurações do Console de Busca do Google não se beneficia de nenhuma destas últimas em termos de SEO.
No entanto, não surgem problemas quando os URLs marcados passivamente são novos ou têm muito pouca autoridade de página. Sugerimos, portanto, que o senhor verifique a autoridade das páginas que deseja acrescentar nos ajustes.
O senhor pode usar, por exemplo, a ferramenta de verificação Ahrefs para fazer isso. Quando a autoridade de uma página é alta, o senhor não deve marcar sua URL como passiva ou perderá benefícios valiosos de SEO.
Capítulo 3: Outras perguntas mais freqüentes sobre o PÓ
Este capítulo é dedicado às perguntas que são feitas freqüentemente sobre os URLs do PÓ.
3.1) Como posso evitar a duplicação de URLs?
Embora haja URLs de PÓ que são inevitáveis em alguns casos, muitas das duplicatas podem ser evitadas. Os webmasters devem sempre usar um formato de URL consistente para todos os links internos em seus domínios.
Por exemplo, um webmaster deve definir a versão canônica de seu website e certificar-se de que todos que acrescentem links internos a seu website sigam esse formato.
Quando a versão canônica do site em questão for www.example.com/, todos os links internos devem ir parahttp://www.example.com/ em vez dehttp://example.com/. A diferença fundamental é a presença de (www) na versão canônica do site.
3.2. Todas as estratégias acima podem ser usadas para o DUST ao mesmo tempo?
Na realidade, não existe uma solução única para lidar com URLs duplicadas. As soluções mencionadas acima têm suas vantagens e desvantagens. Por exemplo, o 301 redirecionamento pode reduzir a eficiência do rastejamento.
É o mesmo princípio para a etiqueta canônica. Na verdade, os robôs exploram as URLs duplicadas de qualquer maneira, a fim de identificar a URL canônica para indexá-la. Quanto aos meta robôs, eles não transmitem a autoridade das URLs duplicadas para a URL original.

Com relação à declaração de URLs passivas nas configurações do Console de Busca do Google, isso é específico do Google e não afeta outros mecanismos de busca.
Portanto, o problema persiste em outros mecanismos de busca como o Bing, se não for mais o caso do Google.
Em vista disso, é razoável procurar usar todas essas soluções de maneira apropriada para cobrir todos os problemas potenciais. No entanto, o senhor precisa analisar cada uma dessas soluções para determinar quais são as que melhor atendem às suas necessidades.
3.3. O que é um URL dinâmico
O uso de URLs dinâmicas é uma das principais causas do PÓ. Em geral, a URL dinâmica é gerada a partir de um banco de dados quando um usuário submete uma consulta de busca.

O conteúdo da página não muda quando um usuário quer escolher uma cor de um item em uma loja on-line, por exemplo. Os URLs dinâmicos freqüentemente contêm caracteres como: ?, &, %, +, =, $.
Em contraste, os URLs estáticos não mudam e não contêm nenhum parâmetro de URL. Essas URLs não causam problemas durante a exploração de um site, como é o caso das URLs dinâmicas.
3.4. Qual é o parâmetro do URL?
Os parâmetros de URL são uma das causas de duplicidade de URLs. Ainda chamadas variáveis de URL, parâmetros de URL são as variáveis que vêm depois de um ponto de interrogação em uma URL.
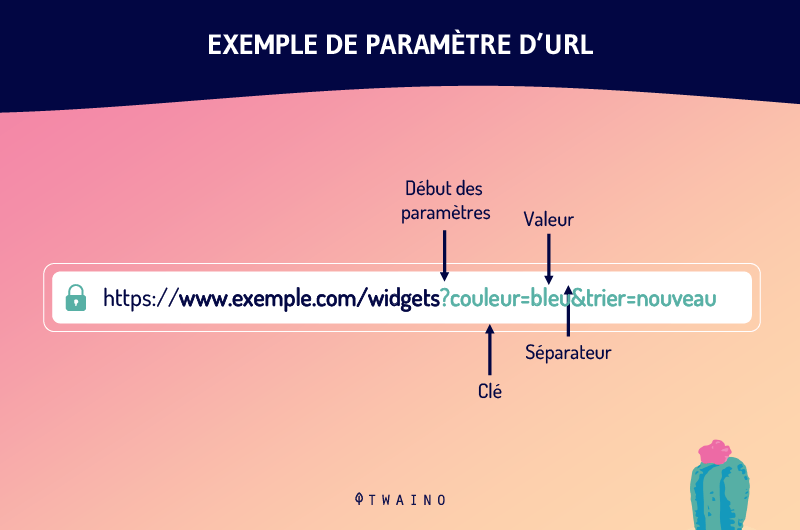
São as peças de informação que definem diferentes características e classificações de um produto ou serviço. Eles também podem determinar a ordem pela qual as informações são mostradas ao telespectador.
Os casos mais comuns de uso de parâmetros de URL incluem
- Filtragem – Por exemplo, ? tipo=tamanho, cor=reg ou ? faixa de preço=25-40
- Identificar – ? produto=big-reg, categoryid=124 ou itemid=24AU
- Traduzir – por exemplo, ? lang=fr, ? língua=de.
3.5. Qual é a identificação da sessão?
Os websites muitas vezes querem acompanhar a atividade dos usuários para que eles possam acrescentar produtos a um carrinho de compras, por exemplo. A maneira de fazer isso é dar a cada visitante uma identificação de sessão.
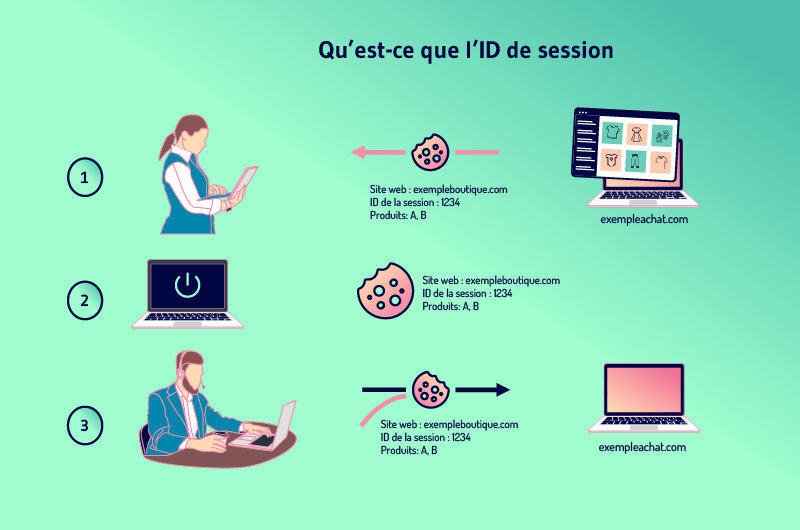
A sessão nada mais é do que a história do que um usuário faz em um site e a identificação é específica para cada visitante. A fim de manter a sessão quando um visitante deixa uma página para outra, os websites precisam armazenar a identificação em algum lugar.
Para fazer isso, os sites geralmente usam cookies que armazenam a identificação no computador do visitante.
Mas quando um visitante tiver previamente desativado o armazenamento de cookies, a identificação da sessão pode ser transferida do servidor para o navegador como um parâmetro anexado à URL da página.
Isso significa que todos os links internos do site têm a identificação da sessão acrescentada ao seu URL. Novas URLs são assim criadas à medida que o visitante visita mais páginas. Essas novas URLs são duplicatas da URL principal e, portanto, criam o problema do DUST.
3.6. O Google penaliza as URLs duplicadas?
O Google não penaliza conteúdo duplicado ou URLs duplicadas, e os funcionários do Google apontam isso repetidas vezes. John Muller, por exemplo, afirmou:
“Não temos nenhuma penalidade por duplicidade de conteúdo. Nós não desmotamos um site por ter conteúdo duplicado o suficiente.“
No entanto, o Google está trabalhando para desencorajar a duplicação que resulta de manipulação e está fazendo ajustes em sua classificação.
Embora se pense que as penalidades não se dirijam implicitamente aos URLs do PÓ, elas afetam o SEO de um website, como discutido acima
Conclusão
Em suma, o PÓ é um problema comum que a maioria dos websites encontra. Trata-se de um conjunto de URLs que dão acesso à mesma página em um domínio.
Na maioria dos casos, o PÓ não causa grandes problemas para a SEO de um site. Entretanto, erros técnicos que levam à duplicação de milhares de URLs de páginas drenam o orçamento de um site e podem ter impacto em seus esforços de SEO.
Felizmente, esses problemas podem ser evitados e a duplicação de URLs pode ser corrigida:
- 301 redirecionamento;
- Criação de meta-robôs;
- A etiqueta rel=canônica
- A definição de URLs passivas nas configurações do Console do Google Searche.
A correção dos URLs do PÓ pode ser bastante demorada e requer um planejamento cuidadoso. O webmaster é, portanto, aconselhado a evitar, tanto quanto possível, situações de duplicação de URL.
E agora, diga-nos quais das maneiras mencionadas neste artigo já ajudaram o senhor a corrigir a duplicação de URLs.

