
Disallow é uma diretriz que os webmasters usam para administrar os rastejadores dos motores de busca. O objetivo principal dessa diretriz é dizer a esses robôs em um arquivo Robots.txt para não rastejar a página ou arquivo específico em um website. Em contraste, temos a diretriz Allow que diz aos rastejadores que eles podem ter acesso a esses mesmos elementos
A criação de conteúdo de qualidade e de backlinks são técnicas populares para se fazer referência a um site. Embora essas técnicas dominem, há muitas outras técnicas que contribuem para a SEO de um website.
A maioria dessas técnicas infelizmente não são bem conhecidas, embora algumas delas tenham provado ser bens reais para referenciar um local.
Esse é o caso do arquivo robots.txt, um arquivo que comunica aos motores de busca através de várias diretrizes, como explorar as páginas de um website. Entre essas diretrizes, destaca-se o Disallow. É uma ferramenta poderosa capaz de influenciar a referência de um site.
Neste artigo, tomaremos conhecimento da diretriz Disallow e de sua utilidade para a SEO. Finalmente, vamos explorar algumas melhores práticas para evitar erros na sua utilização.
Capítulo 1: O que é a diretriz Disallow e como ela é útil na SEO?
A diretriz Disallow é uma prática legítima de SEO que muitos webmasters já usam. Este capítulo é dedicado à definição desta diretriz e à sua importância no mundo da SEO.
1. O que é a Diretiva de Não Autorização?
Como outras tags como Nofollow, a diretiva Disallow influencia o comportamento de rastreadores da web, como o Googlebot e o Bingbot, em relação a certas seções de um website.

Esses bots funcionam como arquivistas da Internet e coletam conteúdo da web para catalogá-lo. Para fazer isso, eles rastejam todos os websites para descobrir novas páginas e indexá-las.

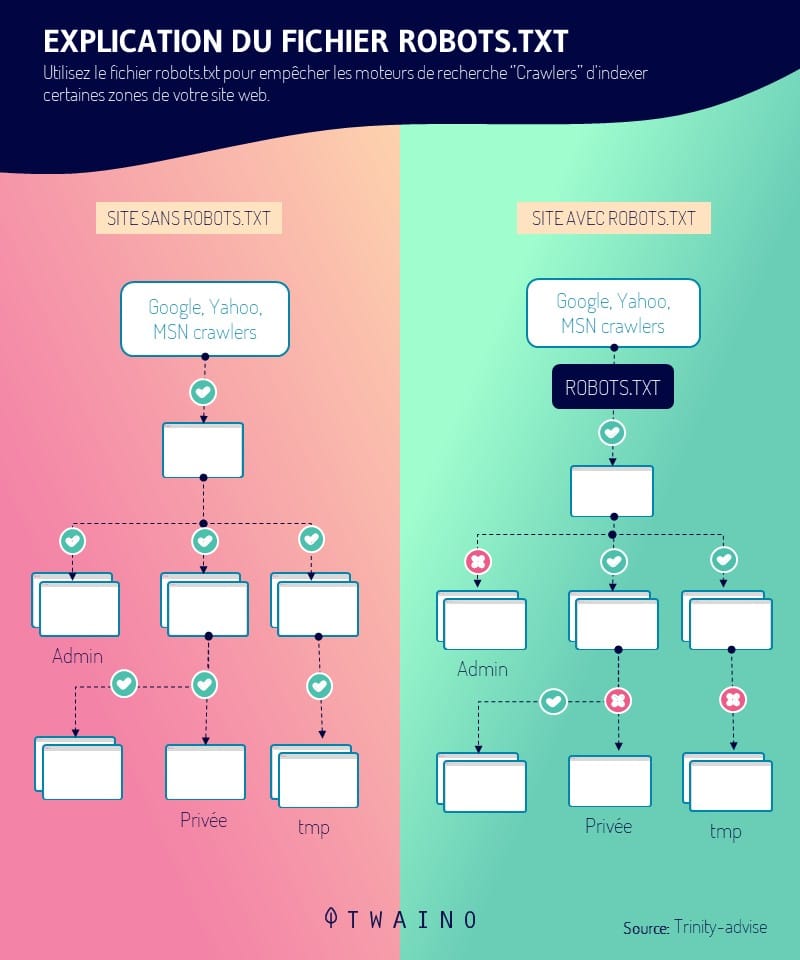
Os webmasters podem dar várias instruções aos rastejadores que acessam seus sites através um arquivo robots.txt. A diretriz de não admissão é uma dessas instruções.
Ele permite aos webmasters bloquear o acesso a recursos específicos em um website. Em conseqüência disso, os rastreadores da web não poderão rastrear URLs que estejam bloqueados usando a diretiva Disallow.
Esta diretriz é às vezes usada em conjunto com a permitir a diretriz. Ao contrário da diretriz Disallow, ela dá acesso aos navegadores e lhes diz quais recursos eles devem explorar.

É preciso lembrar que são apenas os robôs de busca que entendem a linguagem usada no arquivo robot.txt. Os bots que não usam essa linguagem, como os bots maliciosos, podem, portanto, ter acesso a recursos bloqueados pela diretriz Disallow.
1.2 Onde se encontra a diretriz Disallow?
A diretiva Disallow está incluída em um arquivo robots.txt, como mencionado anteriormente. Este arquivo está localizado na raiz de um site no nível superior (www.votresite.com/robots.txt).
Os barcos só podem encontrar o arquivo robots.txt no local mencionado acima. O nome correto é robôs.txt e outras entradas, tais como Robots.txt ou robôs.TXT são simplesmente ignoradas.

O arquivo robots.txt tem outras diretrizes que são :
- Não autorizar ;
- Negar ;
- Ordem ;
- Etc.
O arquivo robots.txt permanece acessível ao público e pode ser visto em qualquer website. Isso aparece quando o senhor acrescenta “/robots.txt” ao final de um domínio. Isso permite ao senhor ver todas as diretrizes de um site quando ele tem esse arquivo.

O link para abrir em seu navegador é o seguinte: www.votresite.com/robots.txt. Quando o arquivo robots.txt não está nesse endereço, os bots assumem que o site não tem tal arquivo.
1.3. Qual é a importância da Diretiva de Não Autorização?
A Diretiva de Não Autorização pode ser usada por muitas razões. Junto com as outras diretrizes do arquivo robots.txt, ele ajuda a melhorar a classificação de um site.
Essas diretrizes ajudam a direcionar os rastejadores para os recursos e a rastejar somente aqueles que são úteis.
1.3.1. Otimização do orçamento de rastejamento
A diretiva Disallow é freqüentemente usada para proibir os rastejadores de páginas que não são de real interesse para a SEO de um website. Isto é o que Google tenta explicar na passagem seguinte:
“O senhor não quer que seu servidor seja sobrecarregado pelo rastejador do Google nem que desperdice seu orçamento rastejante em páginas sem importância ou similares em seu site.“
Em termos simples, o Google aloca um orçamento chamado “crawl” a seus bots para cada website. Esse orçamento é o número de URLs que os Googlebots podem rastrear no site.

Mas quando os bots chegam a um local, eles começam a rastejar cada uma de suas páginas. Quanto mais páginas um site tiver, mais tempo levará para se arrastar.
É por isso que o senhor precisa ajudar os bots a ignorar as páginas sem importância com a diretriz Disallow e direcioná-las com Allow para as páginas importantes que merecem ser classificadas.
Dito isto, ao colocar boas instruções no arquivo robots.txt com o Disallow, os webmasters ajudam os robots a gastar sabiamente o orçamento do crawl. Essa é uma das razões pelas quais a Diretiva de Não Autorização é particularmente útil para a SEO.
Além disso, a diretriz Disallow mantém as seções de um website privadas e ajuda a evitar a sobrecarga do servidor. Também pode ser usado para impedir que certos recursos, como imagens ou vídeos, apareçam nos resultados das buscas.
1.3.2. Será que o “Disallow” impede que uma página seja indexada?
A diretriz Disallow não impede que uma página seja indexada, mas evita que ela seja arrastada.
Portanto, um URL bloqueado com Não Autorizado pode aparecer nos resultados da pesquisa quando o Google encontrar conteúdo relevante para uma consulta. Também pode ser classificado quando há backlinks e etiquetas canônicas que apontam para isso.
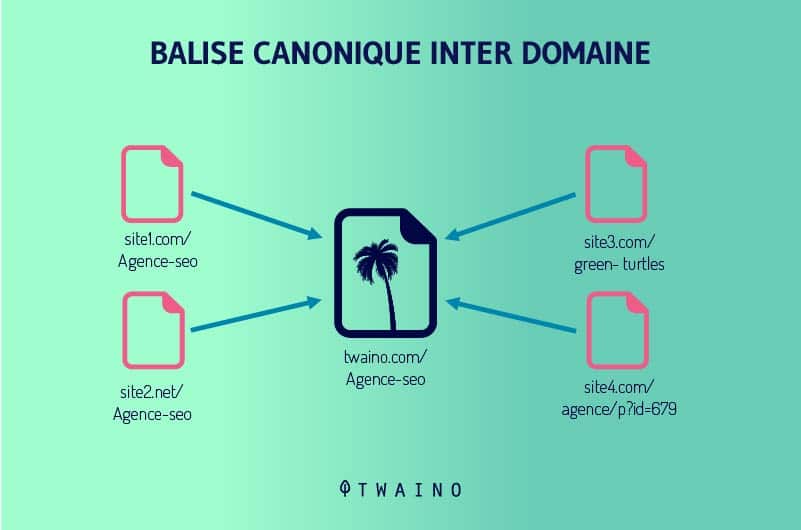
No entanto, o Google só poderá exibir outras informações além do URL da página. Este último aparece, portanto, no lugar do título. Para a meta descrição, o mecanismo de busca mostra uma mensagem de que ela não está disponível devido a um arquivo robots.txt.
Para evitar os motores de busca da indexação de uma página da weba etiqueta Noindex é usada. Ele lhes diz para não considerarem o recurso em questão nos SERPs.
Deve-se lembrar também que as diretrizes Disallow e Noindex podem ser combinadas. A etiqueta Noindex permitirá que o senhor coloque algumas de suas páginas fora do índice e evite problemas como conteúdo duplicado.
Note que essa etiqueta é diferente de Nofollow, uma etiqueta que é usada quando o senhor quer dizer ao Google para indexar a página, mas não para seguir os links dessa página.

O Noindex e Nofollow as etiquetas podem ser combinadas quando o senhor não quer que a página em questão seja indexada e seus links não devem ser seguidos.
Capítulo 2: Formas de aplicação não permitida e melhores práticas para evitar erros
A aplicação da diretriz Disallow é particularmente simples, exigindo apenas um comando de sintaxe e caracteres gerais. Este capítulo discute as formas de aplicação da diretriz Disallow e as boas práticas para evitar erros.
2.1. Uso de agentes-usuários para especificar motores de busca
Para aplicar a diretriz Disallow e as diretrizes de robôs.txt, o senhor deve primeiro definir os agentes-usuários aos quais a mensagem se destina. Estes são os bots que vão considerar as instruções para a diretriz.
Para indicar que são destinados a todos os bots, o símbolo (*) é usado como abaixo.

Mas quando nos dirigimos exclusivamente ao Googlebots, procedemos da seguinte maneira:
- agente-usuário: Googlebots
Quando nos dirigimos apenas aos Bingbots, escrevemos :
- agente-usuário : Bingbots
O registro de um agente-usuário também marca o início das instruções para um conjunto de diretrizes. Assim, todas as diretrizes entre um primeiro agente-usuário e um segundo agente-usuário são tratadas como diretrizes do primeiro agente.

Além disso, o asterisco (*) representa o conjunto de caracteres possíveis, enquanto o sinal do dólar ($) representa a maneira pela qual os URLs são encerrados. O sinal da libra (#) é usado para iniciar um comentário.
Os comentários são apenas para humanos e não são apoiados por robôs. Esses três símbolos são chamados de wildcards, e o maltrato deles pode causar problemas a seu site.
2.2. As diferentes formas de pedido de Não admissão
A sintaxe do Desautorização difere de acordo com a forma de solicitação.
2.2.1. Não é permitido:
Quando o senhor coloca Disallow: sem acrescentar nada depois, o senhor está dizendo aos rastejadores que não há restrições. Isso significa que tudo o que está em sua página é bom de aprender e que os bots podem explorar tudo.

O senhor compreende que essa sintaxe não é útil, uma vez que os motores de busca rastejarão seu site de qualquer maneira em sua ausência.
2.2.2. Não permitido:/
Essa diretriz diz Disallow all e permite ao senhor desautorizar um site inteiro. Quando o senhor usar essa sintaxe, os robôs dos agentes-usuários definidos não poderão rastrear nada em seu site. Essa sintaxe pode ser usada quando um site ainda está em manutenção, por exemplo.

2.2.3. Não permitido: blog
Esse código permite ao senhor bloquear o acesso a todas as páginas cuja URL começa com o blog. Portanto, todos os endereços que começam com https://www.votresite.com/blog serão simplesmente ignorados durante a exploração.

2.2.4. Não permitido:/*.pdf
É possível não permitir o rastreamento de um determinado tipo de arquivo e esse código faz exatamente isso com arquivos PDF. Isso permitirá que os rastejadores ignorem arquivos desse tipo quando rastejarem os seguintes URLs:
- https://www.votresite.com/contrat.pdf
- https://www.votresite.com/blog/documents.pdf
Também é possível acrescentar o símbolo ($) à nossa sintaxe para dizer aos bots que todas as páginas com URLs terminando em (.pdf) devem ser ignoradas.
2.3. Não permitir VS Permissão
As diretrizes Disallow e Allow podem ser usadas em conjunto em um arquivo robots.txt. Quando usado em conjunto, o uso de wildcards pode levar a instruções conflitantes.

Além disso, o Google bots muitas vezes executa a diretriz menos restritiva quando as instruções não são claras. Mas quando as diretrizes Disallow e Allow correspondem à mesma URL em um arquivo robots.txt, a instrução mais longa ganha.
A extensão da declaração é o número de caracteres da declaração fora da diretriz. Este é o caminho da diretriz que os bots vão seguir. Para os exemplos abaixo, a segunda instrução será executada.
- Não autorizar /exemplo* (9 caracteres)
- Permita /exemplo.htm $ (13 caracteres)
- Permita /*pdf$(6 caracteres)
2.4. Melhores práticas para evitar erros
A configuração errada do arquivo robots.txt ou uma instrução errada da diretriz Disallow pode retardar o desempenho da SEO de seu site. É por isso que é importante ter cuidado para não bloquear seus recursos por engano.
Por outro lado, o senhor não deve bloquear dados sensíveis somente com a diretriz Disallow. Como foi mencionado anteriormente, uma página bloqueada ainda pode aparecer nos resultados das buscas e se tornar pública.

Além disso, os bots maliciosos que não seguem as diretrizes dos robôs.txt podem rastejar páginas que supostamente devem ser protegidas usando o Disallow. Como o arquivo robots.txt é público, qualquer um pode olhar para ele e descobrir o que o senhor está tentando esconder.
No que se refere aos agentes usuários, o senhor precisa saber como utilizá-los, a fim de registrar com exatidão as instruções das diversas diretrizes. Tenha em mente que um motor de busca pode ter vários bots quando o senhor definir os agentes.
Por exemplo, o Google usa o Googlebot para pesquisa orgânica, mas o Googlebot-Image para pesquisa de imagens.
Capítulo 3: Outras questões sobre a Diretiva de Não Autorização
Neste capítulo, examinamos as perguntas que são feitas regularmente em conexão com a diretriz Disallow.
3.1) O que é um robô.txt?
Um arquivo robots.txt dá instruções aos motores de busca sobre suas preferências de rastejamento. Esse arquivo é sensível no mundo da SEO e um pequeno erro pode comprometer um site inteiro.
Mas quando usado sabiamente, ele envia bons sinais ao Google e ajuda seu site a se classificar bem. Para editar um arquivo robots.txt, o senhor simplesmente se conecta ao seu servidor através de um cliente FTP e depois faz as mudanças.
Se o senhor não puder fazer a conexão, poderá contatar seu web host. No entanto, se o senhor precisa criar um novo arquivo robots.txt, pode fazê-lo a partir de um editor de texto simples.
Nesse caso, certifique-se de apagar o antigo, caso já tenha um em seu site. Cuidado para não usar um editor de texto como o Word, ele poderá introduzir outro código ao seu texto.
3.2) O que está rastejando?
Também conhecido como crawling, crawling é um processo pelo qual motores de busca enviam robôs (spiders) para examinar o conteúdo de cada URL.
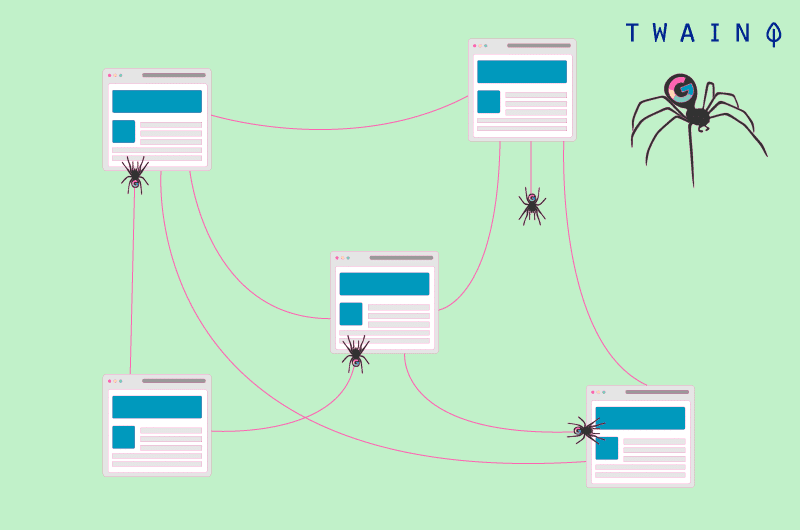
Essas aranhas vão de página em página para encontrar novas URLs ou conteúdos. É este primeiro passo que permite aos motores de busca descobrir seu conteúdo e programá-lo para indexação.
O arquivo robô entra em ação nesta fase e orienta os robôs de acordo com suas preferências. O rastejamento é diferente da indexação, pois esta consiste em armazenar e organizar o conteúdo encontrado durante o rastejamento.
3.3. Que páginas podem ser bloqueadas usando a diretriz Disallow?
Os motores de busca não têm uma regra universal sobre quais páginas devem ser bloqueadas. O uso da diretiva Disallow é, portanto, específico do site e depende do julgamento do webmaster.
No entanto, essa diretriz pode ajudar a dizer às aranhas para não rastejarem páginas em teste. Também pode ser usado para impedir o acesso a certas páginas, tais como as páginas de agradecimento.
Quando o senhor está trabalhando em um site multilíngue, por exemplo, pode bloquear a versão inglesa se ela não estiver pronta e impedir as aranhas de explorá-la.
No que diz respeito à página de agradecimento, ela se destina geralmente a novas perspectivas. Essas páginas ainda podem gastar orçamentos de rastejamento e aparecer nos resultados das buscas.

Quando aparece nos resultados da busca, a página de agradecimento está à disposição de qualquer pessoa e ela pode ser acessada sem passar pelo processo de captura de chumbo.
Mas, ao bloquear a página de agradecimento, o senhor assegura-se de que perspectivas qualificadas possam acessá-la. Nesse caso, a diretriz Disallow por si só não será suficiente, uma vez que não impede que a URL em questão seja indexada.
Dito isto, a página em questão ainda pode figurar nos SERPs. É aconselhável, portanto, combinar a diretriz Disallow com a diretriz Noindex. Isso impedirá os rastejadores de visitar e indexar a página.
Conclusão
Em suma, há muitas ações que podem ser tomadas para melhorar a classificação de um site. A diretriz de não admissão é uma dessas ações que lhe dão uma vantagem real em termos de referenciamento.
Isso permite ao senhor proibir que aranhas de motores de busca rastejem conteúdo que não seja útil para otimizar o orçamento de rastejamento de um website.
Dessa maneira, permite que as aranhas usem esse orçamento da melhor maneira possível para aumentar a visibilidade de seu conteúdo nos resultados da busca.
O uso da diretiva Disallow pode, portanto, ter um impacto significativo quando as instruções são dadas corretamente. No entanto, ela pode quebrar um site inteiro quando as instruções estão erradas.

