
O senhor provavelmente já sabe que o Google está constantemente mudando seu algoritmo de classificação para oferecer aos usuários os melhores resultados possíveis.
Em 7 de agosto de 2023, o mecanismo de busca anunciou que estava pesquisando uma nova estrutura de classificação chamada Term Weighting BERT (TW-BERT), que foi criada para melhorar os resultados da busca.
Neste artigo, vamos descobrir o que é o TW-BERT e como ele pode ajudar o Google a melhorar seus resultados de pesquisa.
Anúncio do Google sobre a estrutura de pesquisa TW-BERT
O Google desenvolveu um documento de pesquisa que apresenta uma estrutura fascinante conhecida como TW-BERT. Sua principal função é melhorar as classificações de pesquisa sem incorrer em modificações substanciais.
O TW-BERT é apresentado como um contexto de ponderação de termos de consulta que combina dois paradigmas para aprimorar os resultados da pesquisa.
Ele se harmoniza com os modelos de expansão de consultas existentes e aumenta sua eficácia. Além disso, sua introdução em uma nova estrutura requer apenas modificações mínimas.
O Term Weighting BERT (TW-BERT) é uma estrutura de classificação impressionante que o Google revelou. Ela otimiza os resultados da pesquisa e pode ser facilmente integrada aos sistemas de classificação existentes.
Embora o Google não tenha confirmado a exploração do TW-BERT, essa nova estrutura representa um grande avanço que melhorará os processos de classificação em várias áreas, inclusive na expansão de consultas.
Entre os principais colaboradores do TW-BERT estão Marc Najork, um dos principais pesquisadores do Google DeepMind e ex-diretor sênior de engenharia de pesquisa do Google Research.
TW-BERT – Do que estamos falando?
O TW-BERT é um contexto de classificação que atribui pontuações, também conhecidas como pesos, às palavras contidas em uma consulta de pesquisa. O objetivo é determinar com mais precisão quais páginas específicas são relevantes para essa consulta específica.
Quando se trata de expansão de consultas, o TW-BERT é muito útil. Essa expansão é um processo que reformula uma consulta de pesquisa ou adiciona palavras a ela(por exemplo, adicionar a palavra “home” (casa) à pesquisa “bodybuilding exercise” (exercícios de musculação)) para que a consulta de pesquisa se aproxime mais dos documentos.
O artigo de pesquisa fala sobre dois métodos de pesquisa diferentes: um baseado em estatísticas e outro baseado em modelos de aprendizagem profunda.
De acordo com os pesquisadores,
“Esses métodos de recuperação baseados em estatísticas permitem uma pesquisa eficiente que se adapta ao tamanho do corpus e se generaliza para novos domínios. No entanto, os termos são ponderados de forma independente e não levam em conta o contexto da consulta como um todo.
Para esse problema, os modelos de aprendizagem profunda podem realizar essa contextualização na consulta para fornecer melhores representações para termos individuais.“
Para ilustrar a ponderação dos termos de pesquisa por meio do TW-BERT, os pesquisadores usam o exemplo da consulta “tênis de corrida Nike”. Cada termo dessa consulta recebe uma pontuação, ou “ponderação”, que permite que a consulta seja entendida como foi enviada pelo usuário.
Nesta ilustração, a palavra “Nike” é considerada importante. Naturalmente, essa palavra receberá uma pontuação mais alta. Os pesquisadores concluem enfatizando a importância de garantir que a palavra “Nike” receba peso suficiente ao exibir tênis de corrida nos resultados finais.
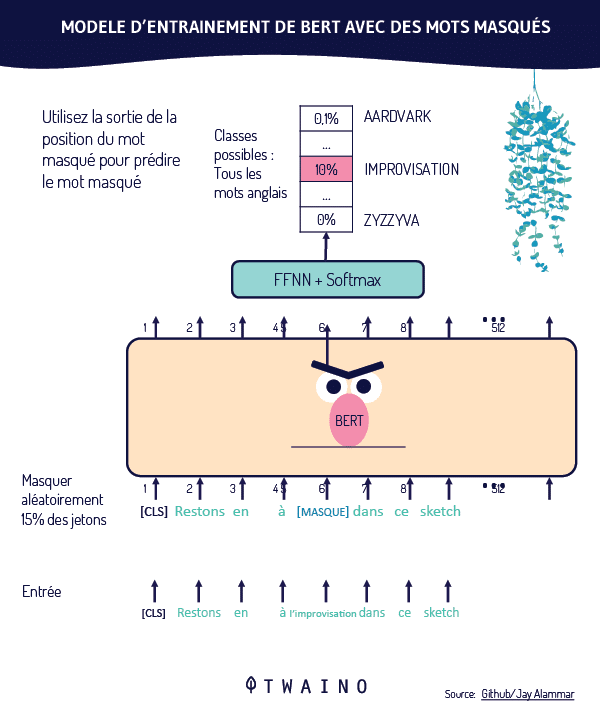
O outro desafio é entender a conexão entre as palavras “running” (corrida) e “shoes” (tênis). Isso significa que a ponderação deve ser aumentada quando as duas palavras são combinadas para formar a expressão “tênis de corrida”, em vez de ponderar cada palavra separadamente.
O TW-BERT: a solução para as limitações das estruturas atuais
O documento de pesquisa discute as limitações inerentes à ponderação atual no que diz respeito à variabilidade da consulta e aponta que os métodos de ponderação baseados em estatísticas têm um desempenho inferior em situações de “aprendizado do zero”.
Aprender do zero refere-se à capacidade de um modelo de resolver um problema para o qual não foi treinado.
Os pesquisadores também apresentaram um resumo das limitações inerentes aos métodos atuais de expansão de termos.
A expansão de termos refere-se ao uso de sinônimos para encontrar mais respostas às consultas de pesquisa ou quando outra palavra é deduzida.
Por exemplo, quando alguém procura por “canja de galinha”, isso implica em “receita de canja de galinha”.
Os pesquisadores descrevem as deficiências das abordagens atuais nos seguintes termos:
“… essas funções auxiliares de pontuação não levam em conta as etapas adicionais de ponderação implementadas pelas funções de pontuação usadas nos extratores existentes, como estatísticas de consulta, estatísticas de documentos e valores de hiperparâmetro.
Isso pode alterar a distribuição original dos pesos atribuídos aos termos durante a avaliação final e a recuperação“.
Posteriormente, os pesquisadores argumentam que a aprendizagem profunda tem seus próprios desafios na forma de complexidade de implementação e comportamento imprevisível quando encontra novos domínios para os quais não foi pré-treinada.
É aí que entra o TW-BERT.
O que o TW-BERT tem a oferecer?
A solução proposta se assemelha a uma abordagem híbrida.
Os pesquisadores escrevem:
“Para preencher essa lacuna, aproveitamos a robustez dos extratores léxicos existentes com as representações contextuais do texto fornecidas por modelos profundos.
Os extratores léxicos já atribuem pesos a termos de n-gramas na consulta durante a pesquisa.
Exploramos um modelo linguístico nesse estágio do pipeline para atribuir pesos apropriados aos termos de n-gramas na consulta.
Esse método de ponderação dos termos do BERT (TW-BERT) é otimizado globalmente usando as mesmas funções de pontuação usadas no pipeline para garantir a consistência entre o treinamento e a recuperação.
Isso melhora a pesquisa ao usar os pesos dos termos produzidos por um modelo TW-BERT e, ao mesmo tempo, mantém uma infraestrutura de recuperação de informações semelhante à sua contraparte de produção existente.”
O algoritmo TW-BERT atribui pesos às consultas para fornecer uma pontuação de relevância mais precisa sobre a qual o restante do processo de classificação pode trabalhar.
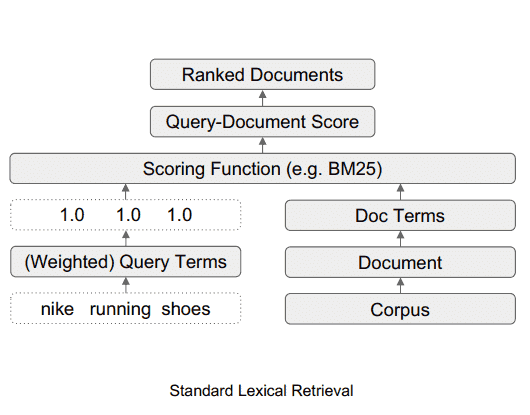
Como é o sistema de pesquisa lexical padrão
Este diagrama ilustra o fluxo de dados em um sistema de pesquisa lexical padrão.
Fonte: searchenginejournal
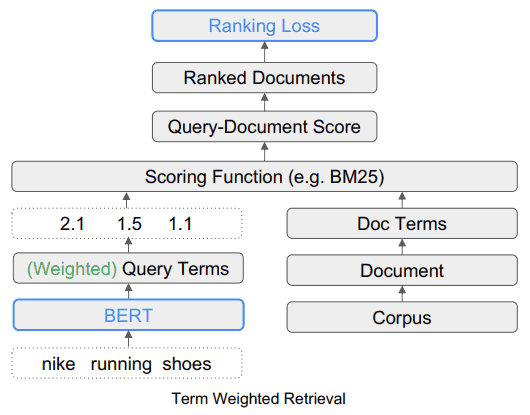
Qual é a aparência do sistema de busca TW-BERT
Este diagrama mostra como a ferramenta TW-BERT se encaixa em uma estrutura de pesquisa.
Fonte: searchenginejournal
A facilidade com que o TW-BERT pode ser implementado
Uma das vantagens do TW-BERT é que ele pode ser facilmente introduzido no processo atual de classificação de busca de informações, como um componente plug-and-play.
“Isso nos permite implementar nossos pesos de termos diretamente em um sistema de recuperação de informações durante a pesquisa.
Isso difere dos métodos de ponderação anteriores, que exigem um ajuste adicional dos parâmetros de um extrator para obter o desempenho ideal de extração, pois otimizam os pesos dos termos obtidos por heurística em vez de otimização de ponta a ponta.”
Um fator importante na facilidade de implementação do TW-BERT é que ele não requer o uso de software especializado ou atualizações de hardware. Essa capacidade torna simples a integração do TW-BERT em um sistema de algoritmo de classificação.
O Google já adicionou o TW-BERT ao seu algoritmo de classificação?
Em termos de sua aplicabilidade ao algoritmo de classificação do Google, a facilidade de integração do TW-BERT sugere que o Google pode ter adotado esse mecanismo na estrutura do seu algoritmo.
A estrutura poderia ser integrada ao sistema de classificação do algoritmo sem exigir uma atualização completa do algoritmo básico.
Por outro lado, certos algoritmos que não são muito eficazes ou não oferecem nenhuma melhoria, embora intrigantes em seu design, podem não ser mantidos no algoritmo de classificação do Google. Por outro lado, algoritmos particularmente eficazes, como o TW-BERT, estão atraindo atenção.
O TW-BERT provou ser muito eficaz no aprimoramento dos recursos dos sistemas de classificação atuais, o que o torna um candidato viável para ser adaptado pelo Google.
Se o Google já tiver implementado o TW-BERT, isso poderia explicar as flutuações de classificação relatadas pelas ferramentas de monitoramento de SEO e pela comunidade de marketing de busca no último mês.
Embora o Google só torne público um número limitado de alterações de classificação, aquelas que têm um impacto significativo, ainda não há confirmação oficial de que o Google tenha integrado o TW-BERT.
Podemos apenas especular sobre sua probabilidade com base nas melhorias significativas feitas na precisão do sistema de busca de informações e na praticidade de seu uso.
Em resumo
O TW-BERT é uma inovação importante no campo da referência natural, que pode mudar a forma como o Google analisa e classifica as páginas da Web. O TW-BERT ainda não foi oficialmente integrado ao algoritmo do Google, mas poderá sê-lo em um futuro próximo.

