Récemment, une nouvelle a captivé l’attention des experts SEO et des webmasters : Google a apporté une mise à jour à la documentation de son robot d’exploration pour corriger une faute de frappe.
Cette correction, bien qu’apparemment mineure, peut avoir un impact significatif sur la manière dont les sites web sont indexés et classés dans les résultats de recherche.
Plongeons dans les détails de cette correction et de l’impact qu’il pourrait potentiellement avoir sur les sites web.
Google-InspectionTool : Que faut-il savoir sur ce robot d’exploration de Google ?
Ce robot d’exploration est une pièce cruciale de l’infrastructure de Google pour garantir la précision et la pertinence des résultats de recherche.
Il opère en réponse à des requêtes spécifiques, ce qui permet aux utilisateurs d’obtenir des informations précises sur l’état de leurs pages Web et sur la manière dont elles sont traitées par le moteur de recherche.
Il est déployé pour répondre à deux invites principaux sur un site Web.
1. Fonctionnalité d’inspection d’URL dans la Search Console
La première fonctionnalité, l’inspection d’URL, offre un aperçu détaillé de la façon dont Google interprète une page spécifique.
Les utilisateurs peuvent ainsi :
- Vérifier si leur contenu est indexé ;
- Demander une indexation immédiate si nécessaire ;
- Visualiser une version rendue de la page pour comprendre comment elle est affichée aux utilisateurs finaux ;
- Inspecter en direct une URL ;
- Résoudre les problèmes liés à une page Web manquante.
De plus, l’outil fournit des informations sur les ressources chargées, le code JavaScript et d’autres éléments importants qui affectent la manière dont une page est explorée et rendue par Google.
2. Test de résultats enrichis
La deuxième fonctionnalité, test de résultats enrichis, sert à garantir que les données structurées utilisées sur une page Web sont conformes aux normes établies par Google.
Ces données structurées permettent d’améliorer la présentation des résultats de recherche en fournissant des informations contextuelles aux utilisateurs, telles que des évaluations, des prix ou des événements à venir.
Le robot d’exploration spécifique au test vérifie que ces données sont correctement intégrées et conformes aux directives de Google.
Pourquoi l’erreur de frappe de l’agent utilisateur du robot d’exploration est problématique ?
La faute de frappe se trouve dans la section de la documentation relative à l’outil d’inspection Google.
Cette erreur de frappe peut présenter un défi de taille pour les sites web qui sont protégés par un système de paiement, mais qui accordent des privilèges d’accès à certains robots, comme l’agent utilisateur Google-InspectionTool.
Une identification erronée de l’agent utilisateur pourrait également causer des problèmes. Cela serait particulièrement problématique si le CMS tente de bloquer le robot d’exploration en utilisant le fichier robots.txt ou une directive meta-robots pour empêcher Google de découvrir des pages qu’il ne devrait pas indexer.
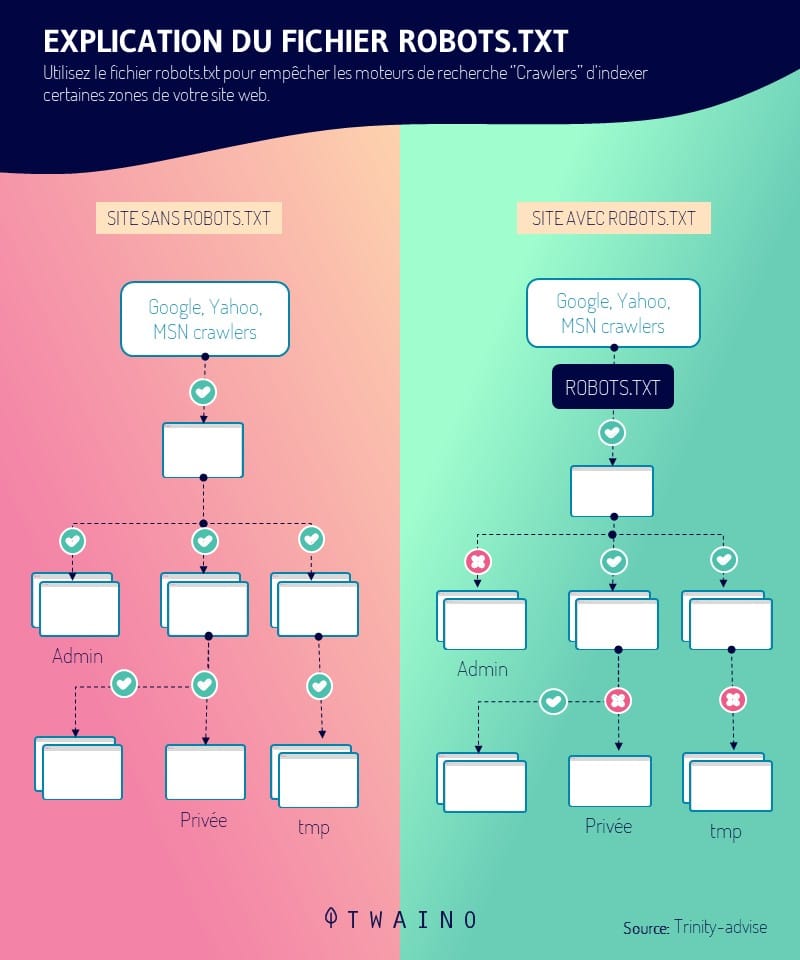
De plus, il existe des méthodes visant à supprimer les liens hypertextes menant vers des éléments du site, tels que :
- la page d’inscription des utilisateurs ;
- les profils des utilisateurs ;
- et la fonction de recherche.
Elles visent à empêcher les robots d’indexer ces pages.
On peut donc comprendre que s’il y a des erreurs, ces pages pourraient être explorées, indexées et affichées dans les SERP.
Analyse de la mise à jour et de la nature de la faute de frappe
Le problème était dû à une petite faute de frappe difficile à repérer dans la description de l’agent utilisateur.
Jetez un coup d’œil à l’image ci-dessus et voyez si vous pouvez faire la différence :

Source : SEJ
Voici la différence :
Version originale
Mozilla/5.0 (compatible ; Google-InspectionTool/1.0)
Nouvelle version
Mozilla/5.0 (compatible ; Google-InspectionTool/1.0 ; )
Vous pouvez comparer la version originale avec la nouvelle version ici.
Il est impératif de mettre à jour le fichier robots.txt, les directives méta-robots ou le code CMS lorsqu’un client ou vous-même ajoutez les robots d’exploration de Google à la liste blanche ou bloquez l’accès aux robots d’exploration sur certaines pages Web.
Ce sont des détails mineurs, mais ils peuvent avoir un impact considérable.
L’Importance de la documentation du robot d’exploration
La documentation du robot d’exploration de Google occupe une place centrale dans le domaine du référencement et de l’indexation web.
Elle sert de référence fondamentale pour les webmasters et les professionnels du référencement, fournissant des directives précises sur la manière dont Google explore et indexe les sites web.
Cette documentation est essentielle pour plusieurs raisons :
- Guidance Précise
La documentation du robot d’exploration de Google explique en détail comment le robot d’exploration (ou spider) de Google parcourt et analyse les sites web. Les webmasters se fient à ces informations pour optimiser leurs sites en fonction des critères de Google.
- Amélioration du Référencement
En comprenant les attentes de Google en matière d’exploration et d’indexation, les professionnels du référencement peuvent optimiser les sites pour un meilleur classement dans les résultats de recherche. Une documentation précise est essentielle pour maximiser la visibilité en ligne.
- Éviter les Erreurs
En suivant les directives de Google, les webmasters peuvent éviter les erreurs qui pourraient nuire au classement de leur site. Une simple faute de frappe ou une mauvaise interprétation de la documentation peut avoir des conséquences néfastes.
En résumé
Pour conclure, la correction d’une faute de frappe dans la documentation du robot d’exploration de Google rappelle l’importance des détails dans le domaine du référencement. Même les modifications apparemment mineures peuvent avoir un impact significatif sur la manière dont les sites web sont explorés et classés dans les résultats de recherche.


