
Vous savez certainement déjà que Google change constamment son algorithme de classement pour offrir les meilleurs résultats possibles aux utilisateurs.
Le moteur de recherche a annoncé le 7 août 2023 la recherche d’un nouveau cadre de classement appelé Term Weighting BERT (TW-BERT) qui a pour vocation d’améliorer les résultats de recherche.
À travers cet article, nous découvrons en quoi consiste le TW-BERT et la façon dont il pourrait permettre à Google d’améliorer ses résultats de recherche.
L’annonce de Google du cadre de recherche TW-BERT
Google a élaboré un document de recherche qui présente un cadre fascinant connu sous le nom de TW-BERT. Sa fonction principale est d’améliorer le classement des recherches sans encourir des modifications substantielles.
TW-BERT se présente comme un contexte de pondération des termes de requête qui associe deux paradigmes pour rehausser les résultats de recherche.
Il s’harmonise avec les modèles d’expansion des requêtes déjà en place tout en augmentant leur efficacité. De plus, son introduction dans un nouveau cadre requiert seulement des modifications minimes.
Term Weighting BERT (TW-BERT) est un cadre de classement impressionnant que Google a révélé. Il optimise les résultats de recherche et peut être intégré facilement dans les systèmes de classement existants.
Même si Google n’a pas confirmé l’exploitation de TW-BERT, ce nouveau cadre représente une avancée majeure qui va améliorer les processus de classement dans différents domaines, notamment l’expansion des requêtes.
Parmi les contributeurs notables de TW-BERT, nous avons Marc Najork, un chercheur éminent au sein de Google DeepMind et ancien directeur principal de l’ingénierie de la recherche à Google Research.
TW-BERT – De quoi parle-t-on ?
TW-BERT est un contexte de classement qui donne des scores, aussi appelés poids, aux mots contenus dans une requête de recherche. L’objectif est de déterminer de manière plus précise, les pages spécifiques qui sont pertinentes pour cette requête en particulier.
En ce qui concerne l’expansion des requêtes, TW-BERT est très utile. Cette expansion est un processus qui reformule une requête de recherche ou y ajoute des mots (par exemple, l’ajout du mot « domicile » à la recherche « exercice de musculation« ) dans le but de faire correspondre de manière plus adéquate la requête de recherche avec les documents.
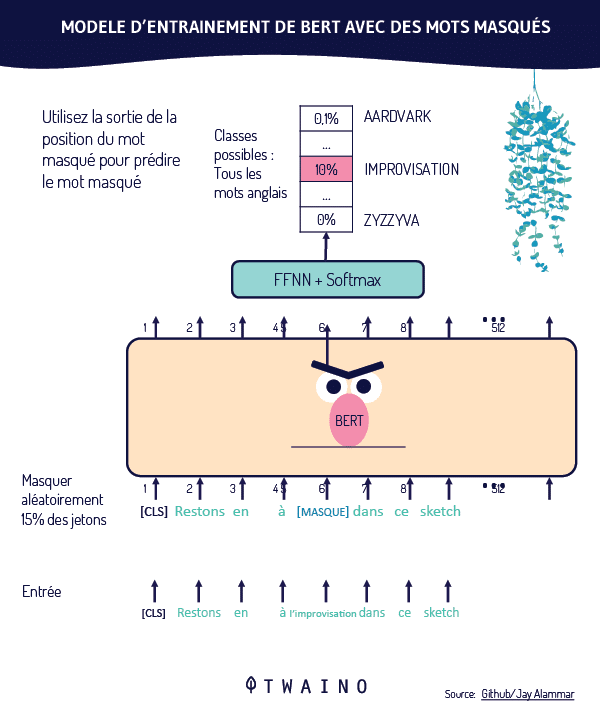
Le document de recherche parle de deux méthodes de recherche différentes : une se basant sur les statistiques et une autre orientée sur des modèles d’apprentissage profond.
Selon les chercheurs,
“Ces méthodes d’extraction basées sur les statistiques permettent une recherche efficace qui s’adapte à la taille du corpus et se généralise à de nouveaux domaines. Toutefois, les termes sont pondérés de manière indépendante et ne tiennent pas compte du contexte de l’ensemble de la requête.
Pour ce problème, les modèles d’apprentissage profond peuvent effectuer cette contextualisation sur la requête afin de fournir de meilleures représentations pour les termes individuels.«
Pour illustrer la pondération des termes de recherche via TW-BERT, les chercheurs prennent l’exemple de la requête « chaussures de course Nike ». Chaque terme de cette requête reçoit un score, ou une « pondération », ce qui permet de comprendre la requête telle qu’elle a été émise par l’utilisateur.
Avec cette illustration, le mot « Nike » est considéré comme important. Naturellement, ce mot recevra un score plus élevé. Les chercheurs concluent en insistant sur l’importance d’assurer que le mot « Nike » reçoit une pondération suffisante tout en affichant des chaussures de course dans les résultats finaux.
L’autre défi est de comprendre la connexion entre les mots « course » et « chaussures ». Cela implique que la pondération devrait être augmentée lorsque les deux mots sont combinés pour former l’expression « chaussures de course », plutôt que de pondérer chaque mot séparément.
Le TW-BERT : La solution pour les limites des cadres actuels
Le document de recherche parle des limites inhérentes de la pondération actuelle en matière de variabilité des requêtes et signale que les méthodes de pondération fondées sur les statistiques sont sous-performantes pour les situations de « tir à zéro ».
L’apprentissage à partir de zéro évoque la capacité d’un modèle à résoudre un problème pour lequel il n’a pas été formé.
Les chercheurs ont aussi présenté un résumé des limites inhérentes aux méthodes actuelles d’expansion des termes.
L’expansion de termes fait référence à l’utilisation de synonymes pour trouver davantage de réponses à des requêtes de recherche ou lorsqu’un autre mot est déduit.
Par exemple, lorsque quelqu’un cherche « soupe de poulet », cela implique « recette de soupe de poulet ».
Les chercheurs décrivent les lacunes des approches actuelles dans les termes suivants :
« … ces fonctions de notation auxiliaires ne tiennent pas compte des étapes de pondération supplémentaires mises en œuvre par les fonctions de notation utilisées dans les extracteurs existants, telles que les statistiques de requêtes, les statistiques de documents, et les valeurs des hyperparamètres.
Cela peut altérer la distribution originale des poids attribués aux termes lors de l’évaluation finale et de la récupération« .
Par la suite, les chercheurs avancent que l’apprentissage profond a ses propres défis sous la forme d’une complexité de déploiement et d’un comportement imprévisible lorsqu’il rencontre de nouveaux domaines pour lesquels il n’a pas été pré-formé.
C’est là que TW-BERT intervient.
Quel est l’intérêt du TW-BERT ?
La solution proposée ressemble à une approche hybride.
Les chercheurs écrivent :
« Pour combler cet écart, nous tirons profit de la robustesse des extracteurs lexicaux existants avec les représentations contextuelles du texte fournies par les modèles profonds.
Les extracteurs lexicaux attribuent déjà des poids aux termes n-grammes de la requête lors de la recherche.
Nous exploitons un modèle linguistique à ce stade du pipeline pour attribuer des poids appropriés aux termes n-grammes de la requête.
Cette méthode de pondération des termes BERT (TW-BERT) est optimisée de façon globale en utilisant les mêmes fonctions de notation que celles utilisées dans le pipeline pour garantir la cohérence entre la formation et l’extraction.
Cela permet d’améliorer la recherche lorsque l’on utilise les pondérations de termes produits par un modèle de TW-BERT tout en conservant une infrastructure de recouvrement d’informations similaire à son homologue de production existant.”
L’algorithme TW-BERT attribue des poids aux requêtes pour fournir un score de pertinence plus précis sur lequel le reste du processus de classement peut ensuite travailler.
Ce à quoi ressemble le système de recherche lexicale standard
Ce diagramme illustre le flux de données dans un système de recherche lexicale standard.
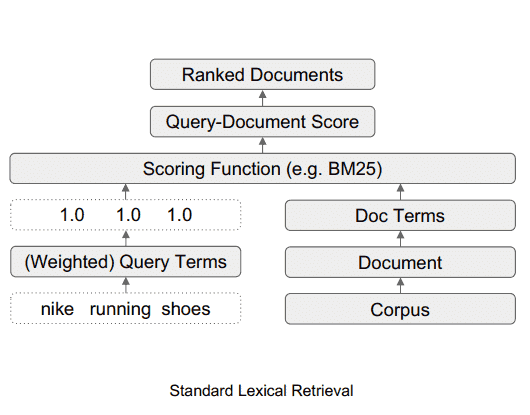
Source : searchenginejournal
Ce à quoi ressemble le système de recherche avec le TW-BERT
Ce diagramme montre comment l’outil TW-BERT s’intègre dans un cadre de recherche.
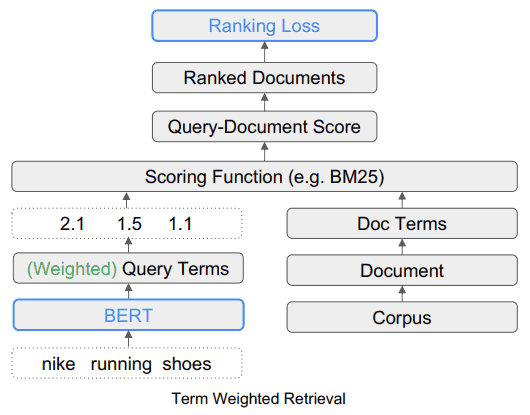
Source : searchenginejournal
La facilité de déploiement de TW-BERT
L’un des avantages de TW-BERT est qu’il peut être facilement introduit dans le processus actuel de classement de la recherche d’informations, comme un composant plug-and-play.
« Cela nous permet de déployer nos pondérations de termes directement dans un système de recherche d’information lors de la recherche.
Cela diffère des méthodes de pondération antérieures qui nécessitent un réglage supplémentaire des paramètres d’un extracteur pour obtenir une performance d’extraction optimale, car elles optimisent les poids des termes obtenus par heuristique au lieu d’optimiser de bout en bout”.
Un facteur clé de la facilité de déploiement de TW-BERT est qu’il ne nécessite pas l’utilisation d’un logiciel spécialisé ou de mises à jour matérielles. Cette capacité rend l’intégration de TW-BERT dans un système d’algorithme de classement simple.
Google a-t-il déjà ajouté TW-BERT à son algorithme de classement ?
En ce qui concerne son applicabilité à l’algorithme de classement de Google, la facilité d’intégration de TW-BERT permet de supposer que Google pourrait avoir adopté ce mécanisme dans la structure de son algorithme.
Le cadre pourrait être intégré dans le système de classement de l’algorithme sans qu’une mise à jour complète de l’algorithme de base soit nécessaire.
Par ailleurs, certains algorithmes peu efficaces ou n’apportant aucune amélioration, bien que intrigants dans leur conception, pourraient ne pas être retenus pour l’algorithme de classement de Google. En revanche, les algorithmes particulièrement performants, comme le TW-BERT, retiennent l’attention.
TW-BERT s’est avéré très efficace pour améliorer les capacités des systèmes de classement actuels, ce qui en fait un candidat viable à l’adaptation par Google.
Si Google a déjà mis en œuvre TW-BERT, cela pourrait expliquer les fluctuations de classement signalées par les outils de surveillance du référencement et la communauté du marketing de recherche au cours du dernier mois.
Alors que Google ne rend public qu’un nombre limité de changements de classement, ceux qui ont un impact significatif, il n’existe pas encore de confirmation officielle de l’intégration de TW-BERT par Google.
Nous ne pouvons qu’émettre des hypothèses sur sa probabilité en nous basant sur les améliorations notables apportées à la précision du système de recherche d’informations et à la praticité de son utilisation.
En résumé
TW-BERT est une innovation majeure dans le domaine du référencement naturel, qui pourrait changer la façon dont Google analyse et classe les pages web. TW-BERT n’est pas encore officiellement intégré à l’algorithme de Google, mais il pourrait l’être dans un avenir proche.


